 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain-Agnostic Clustering with Self-Distillation
Nov 23, 2021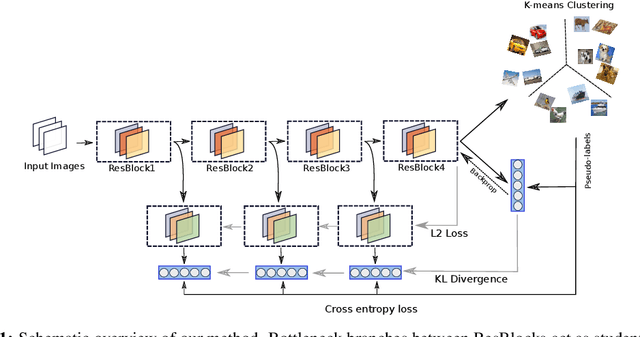

Recent advancements in self-supervised learning have reduced the gap between supervised and unsupervised representation learning. However, most self-supervised and deep clustering techniques rely heavily on data augmentation, rendering them ineffective for many learning tasks where insufficient domain knowledge exists for performing augmentation. We propose a new self-distillation based algorithm for domain-agnostic clustering. Our method builds upon the existing deep clustering frameworks and requires no separate student model. The proposed method outperforms existing domain agnostic (augmentation-free) algorithms on CIFAR-10. We empirically demonstrate that knowledge distillation can improve unsupervised representation learning by extracting richer `dark knowledge' from the model than using predicted labels alone. Preliminary experiments also suggest that self-distillation improves the convergence of DeepCluster-v2.
Gradient Flow in Sparse Neural Networks and How Lottery Tickets Win
Oct 07, 2020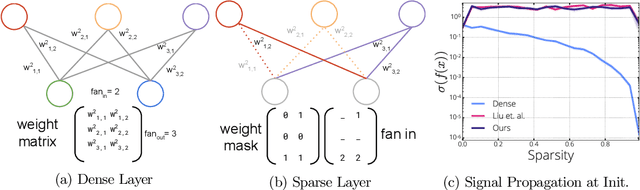
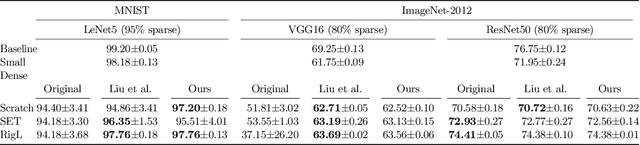
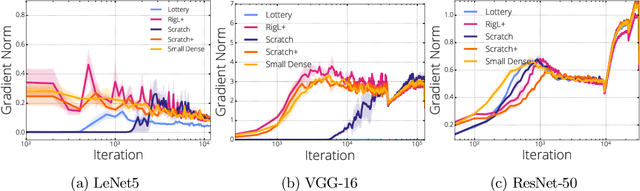
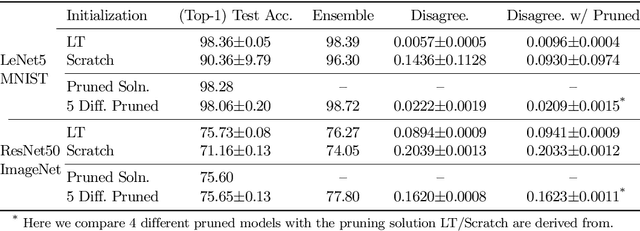
Sparse Neural Networks (NNs) can match the generalization of dense NNs using a fraction of the compute/storage for inference, and also have the potential to enable efficient training. However, naively training unstructured sparse NNs from random initialization results in significantly worse generalization, with the notable exception of Lottery Tickets (LTs) and Dynamic Sparse Training (DST). In this work, we attempt to answer: (1) why training unstructured sparse networks from random initialization performs poorly and; (2) what makes LTs and DST the exceptions? We show that sparse NNs have poor gradient flow at initialization and propose a modified initialization for unstructured connectivity. Furthermore, we find that DST methods significantly improve gradient flow during training over traditional sparse training methods. Finally, we show that LTs do not improve gradient flow, rather their success lies in re-learning the pruning solution they are derived from - however, this comes at the cost of learning novel solutions.