 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain-Agnostic Clustering with Self-Distillation
Paper and Code
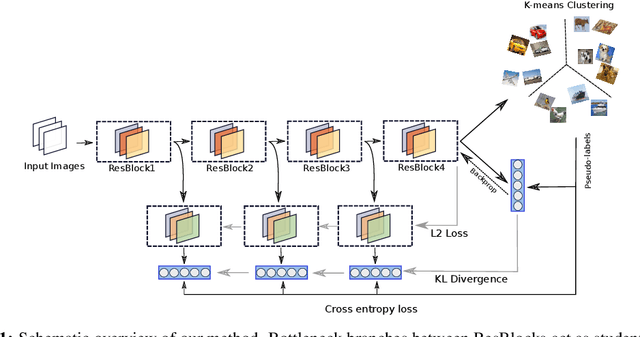

Recent advancements in self-supervised learning have reduced the gap between supervised and unsupervised representation learning. However, most self-supervised and deep clustering techniques rely heavily on data augmentation, rendering them ineffective for many learning tasks where insufficient domain knowledge exists for performing augmentation. We propose a new self-distillation based algorithm for domain-agnostic clustering. Our method builds upon the existing deep clustering frameworks and requires no separate student model. The proposed method outperforms existing domain agnostic (augmentation-free) algorithms on CIFAR-10. We empirically demonstrate that knowledge distillation can improve unsupervised representation learning by extracting richer `dark knowledge' from the model than using predicted labels alone. Preliminary experiments also suggest that self-distillation improves the convergence of DeepCluster-v2.