 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmojis Predict Dropouts of Remote Workers: An Empirical Study of Emoji Usage on GitHub
Feb 10, 2021

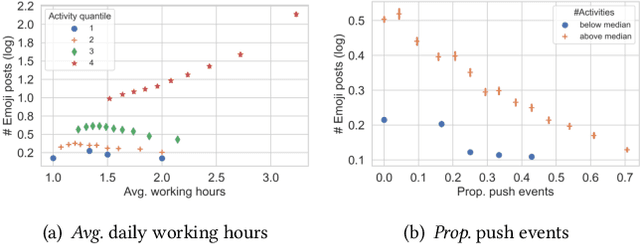
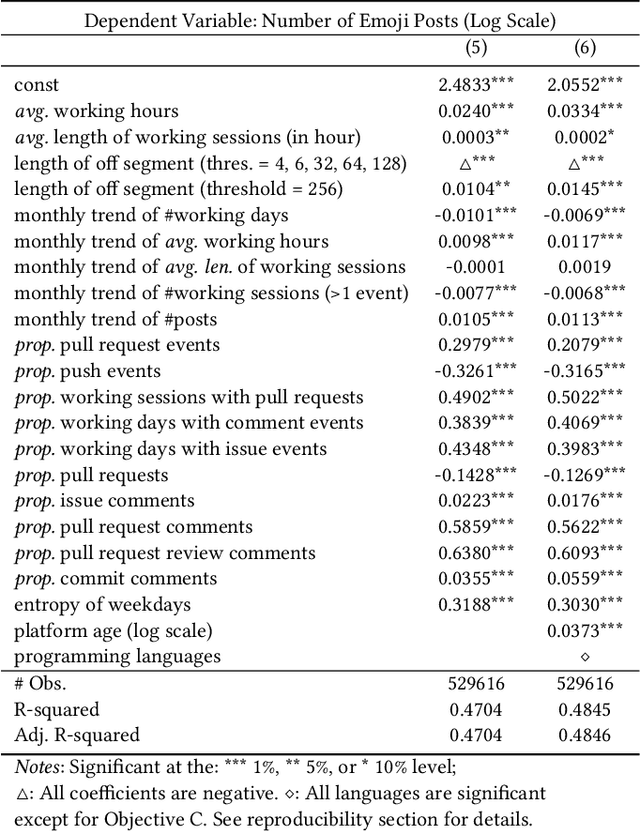
Emotions at work have long been identified as critical signals of work motivations, status, and attitudes, and as predictors of various work-related outcomes. For example, harmonious passion increases commitment at work but stress reduces sustainability and leads to burnouts. When more and more employees work remotely, these emotional and mental health signals of workers become harder to observe through daily, face-to-face communications. The use of online platforms to communicate and collaborate at work provides an alternative channel to monitor the emotions of workers. This paper studies how emojis, as non-verbal cues in online communications, can be used for such purposes. In particular, we study how the developers on GitHub use emojis in their work-related activities. We show that developers have diverse patterns of emoji usage, which highly correlate to their working status including activity levels, types of work, types of communications, time management, and other behavioral patterns. Developers who use emojis in their posts are significantly less likely to dropout from the online work platform. Surprisingly, solely using emoji usage as features, standard machine learning models can predict future dropouts of developers at a satisfactory accuracy.
An Empirical Study on Deployment Faults of Deep Learning Based Mobile Applications
Feb 10, 2021
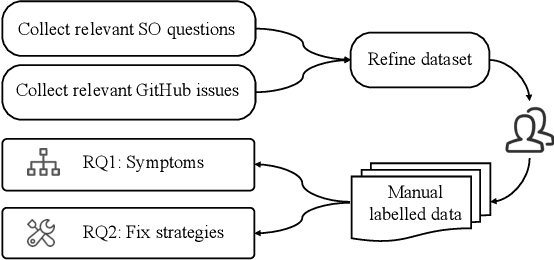
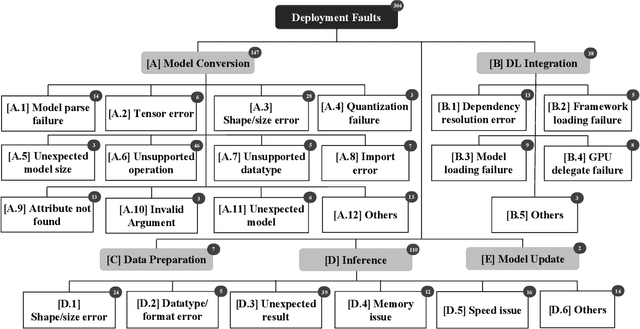

Deep Learning (DL) is finding its way into a growing number of mobile software applications. These software applications, named as DL based mobile applications (abbreviated as mobile DL apps) integrate DL models trained using large-scale data with DL programs. A DL program encodes the structure of a desirable DL model and the process by which the model is trained using training data. Due to the increasing dependency of current mobile apps on DL, software engineering (SE) for mobile DL apps has become important. However, existing efforts in SE research community mainly focus on the development of DL models and extensively analyze faults in DL programs. In contrast, faults related to the deployment of DL models on mobile devices (named as deployment faults of mobile DL apps) have not been well studied. Since mobile DL apps have been used by billions of end users daily for various purposes including for safety-critical scenarios, characterizing their deployment faults is of enormous importance. To fill the knowledge gap, this paper presents the first comprehensive study on the deployment faults of mobile DL apps. We identify 304 real deployment faults from Stack Overflow and GitHub, two commonly used data sources for studying software faults. Based on the identified faults, we construct a fine-granularity taxonomy consisting of 23 categories regarding to fault symptoms and distill common fix strategies for different fault types. Furthermore, we suggest actionable implications and research avenues that could further facilitate the deployment of DL models on mobile devices.
SEntiMoji: An Emoji-Powered Learning Approach for Sentiment Analysis in Software Engineering
Jul 04, 2019


Sentiment analysis has various application scenarios in software engineering (SE), such as detecting developers' emotions in commit messages and identifying their opinions on Q&A forums. However, commonly used out-of-the-box sentiment analysis tools cannot obtain reliable results on SE tasks and the misunderstanding of technical jargon is demonstrated to be the main reason. Then, researchers have to utilize labeled SE-related texts to customize sentiment analysis for SE tasks via a variety of algorithms. However, the scarce labeled data can cover only very limited expressions and thus cannot guarantee the analysis quality. To address such a problem, we turn to the easily available emoji usage data for help. More specifically, we employ emotional emojis as noisy labels of sentiments and propose a representation learning approach that uses both Tweets and GitHub posts containing emojis to learn sentiment-aware representations for SE-related texts. These emoji-labeled posts can not only supply the technical jargon, but also incorporate more general sentiment patterns shared across domains. They as well as labeled data are used to learn the final sentiment classifier. Compared to the existing sentiment analysis methods used in SE, the proposed approach can achieve significant improvement on representative benchmark datasets. By further contrast experiments, we find that the Tweets make a key contribution to the power of our approach. This finding informs future research not to unilaterally pursue the domain-specific resource, but try to transform knowledge from the open domain through ubiquitous signals such as emojis.