 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreamDiffusion: Generating High-Quality Images from Brain EEG Signals
Jun 30, 2023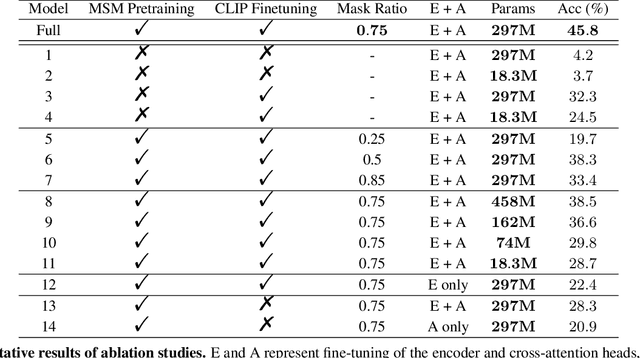



This paper introduces DreamDiffusion, a novel method for generating high-quality images directly from brain electroencephalogram (EEG) signals, without the need to translate thoughts into text. DreamDiffusion leverages pre-trained text-to-image models and employs temporal masked signal modeling to pre-train the EEG encoder for effective and robust EEG representations. Additionally, the method further leverages the CLIP image encoder to provide extra supervision to better align EEG, text, and image embeddings with limited EEG-image pairs. Overall, the proposed method overcomes the challenges of using EEG signals for image generation, such as noise, limited information, and individual differences, and achieves promising results. Quantitative and qualitative results demonstrate the effectiveness of the proposed method as a significant step towards portable and low-cost ``thoughts-to-image'', with potential applications in neuroscience and computer vision. The code is available here \url{https://github.com/bbaaii/DreamDiffusion}.
HRDFuse: Monocular 360°Depth Estimation by Collaboratively Learning Holistic-with-Regional Depth Distributions
Mar 22, 2023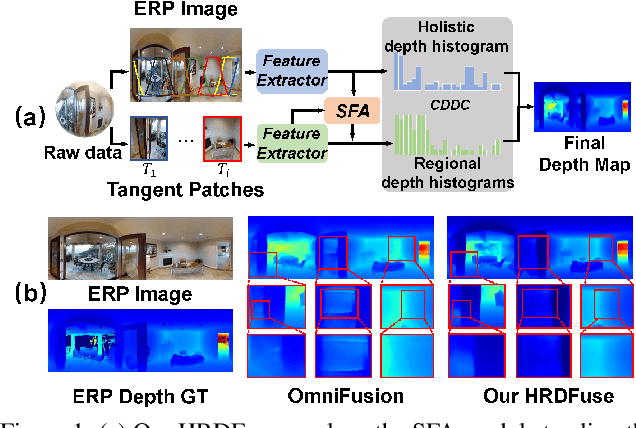
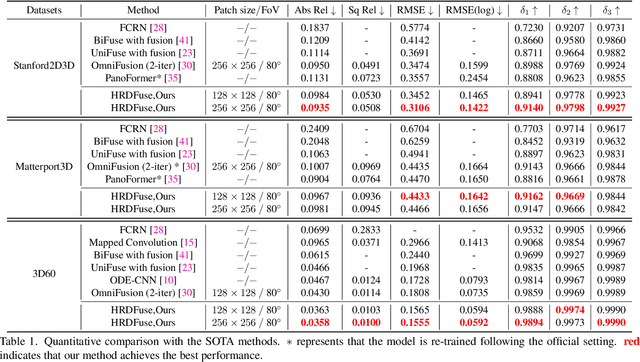
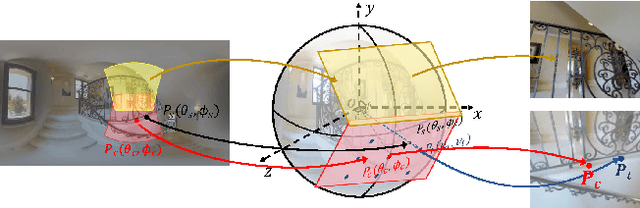
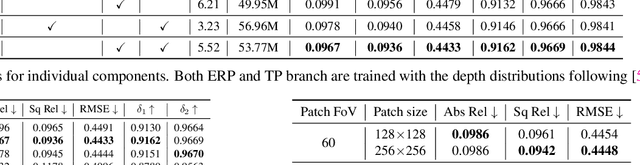
Depth estimation from a monocular 360{\deg} image is a burgeoning problem owing to its holistic sensing of a scene. Recently, some methods, \eg, OmniFusion, have applied the tangent projection (TP) to represent a 360{\deg}image and predicted depth values via patch-wise regressions, which are merged to get a depth map with equirectangular projection (ERP) format. However, these methods suffer from 1) non-trivial process of merging plenty of patches; 2) capturing less holistic-with-regional contextual information by directly regressing the depth value of each pixel. In this paper, we propose a novel framework, \textbf{HRDFuse}, that subtly combines the potential of convolutional neural networks (CNNs) and transformers by collaboratively learning the \textit{holistic} contextual information from the ERP and the \textit{regional} structural information from the TP. Firstly, we propose a spatial feature alignment (\textbf{SFA}) module that learns feature similarities between the TP and ERP to aggregate the TP features into a complete ERP feature map in a pixel-wise manner. Secondly, we propose a collaborative depth distribution classification (\textbf{CDDC}) module that learns the \textbf{holistic-with-regional} histograms capturing the ERP and TP depth distributions. As such, the final depth values can be predicted as a linear combination of histogram bin centers. Lastly, we adaptively combine the depth predictions from ERP and TP to obtain the final depth map. Extensive experiments show that our method predicts\textbf{ more smooth and accurate depth} results while achieving \textbf{favorably better} results than the SOTA methods.