 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangled Interaction Representation for One-Stage Human-Object Interaction Detection
Dec 04, 2023



Human-Object Interaction (HOI) detection is a core task for human-centric image understanding. Recent one-stage methods adopt a transformer decoder to collect image-wide cues that are useful for interaction prediction; however, the interaction representations obtained using this method are entangled and lack interpretability. In contrast, traditional two-stage methods benefit significantly from their ability to compose interaction features in a disentangled and explainable manner. In this paper, we improve the performance of one-stage methods by enabling them to extract disentangled interaction representations. First, we propose Shunted Cross-Attention (SCA) to extract human appearance, object appearance, and global context features using different cross-attention heads. This is achieved by imposing different masks on the cross-attention maps produced by the different heads. Second, we introduce the Interaction-aware Pose Estimation (IPE) task to learn interaction-relevant human pose features using a disentangled decoder. This is achieved with a novel attention module that accurately captures the human keypoints relevant to the current interaction category. Finally, our approach fuses the appearance feature and pose feature via element-wise addition to form the interaction representation. Experimental results show that our approach can be readily applied to existing one-stage HOI detectors. Moreover, we achieve state-of-the-art performance on two benchmarks: HICO-DET and V-COCO.
Towards Hard-Positive Query Mining for DETR-based Human-Object Interaction Detection
Jul 12, 2022
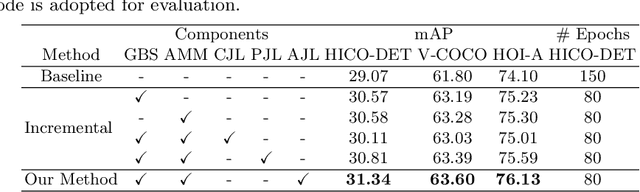
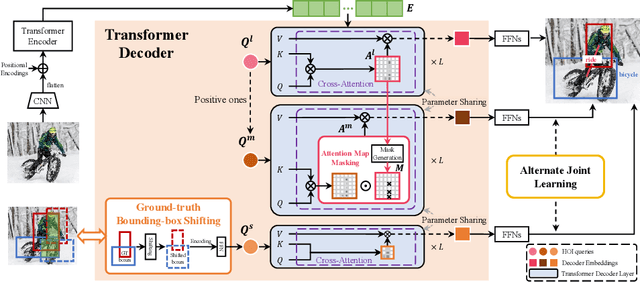
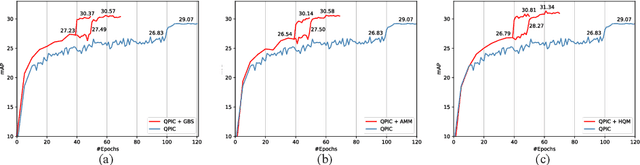
Human-Object Interaction (HOI) detection is a core task for high-level image understanding. Recently, Detection Transformer (DETR)-based HOI detectors have become popular due to their superior performance and efficient structure. However, these approaches typically adopt fixed HOI queries for all testing images, which is vulnerable to the location change of objects in one specific image. Accordingly, in this paper, we propose to enhance DETR's robustness by mining hard-positive queries, which are forced to make correct predictions using partial visual cues. First, we explicitly compose hard-positive queries according to the ground-truth (GT) position of labeled human-object pairs for each training image. Specifically, we shift the GT bounding boxes of each labeled human-object pair so that the shifted boxes cover only a certain portion of the GT ones. We encode the coordinates of the shifted boxes for each labeled human-object pair into an HOI query. Second, we implicitly construct another set of hard-positive queries by masking the top scores in cross-attention maps of the decoder layers. The masked attention maps then only cover partial important cues for HOI predictions. Finally, an alternate strategy is proposed that efficiently combines both types of hard queries. In each iteration, both DETR's learnable queries and one selected type of hard-positive queries are adopted for loss computation. Experimental results show that our proposed approach can be widely applied to existing DETR-based HOI detectors. Moreover, we consistently achieve state-of-the-art performance on three benchmarks: HICO-DET, V-COCO, and HOI-A. Code is available at https://github.com/MuchHair/HQM.
Glance and Gaze: Inferring Action-aware Points for One-Stage Human-Object Interaction Detection
Apr 12, 2021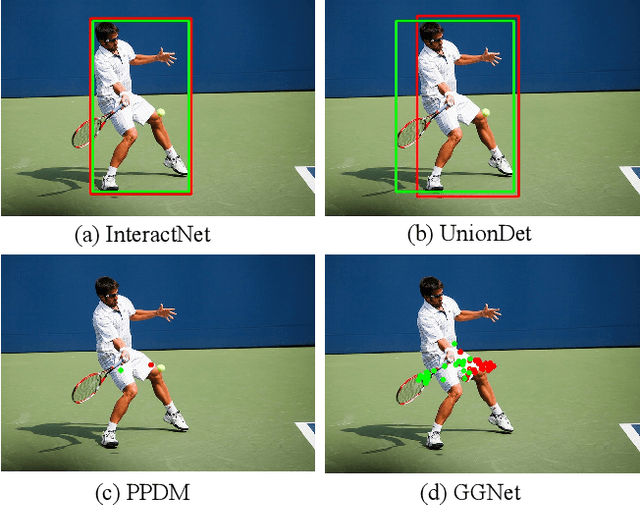
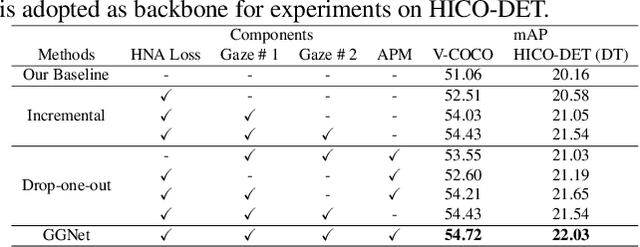
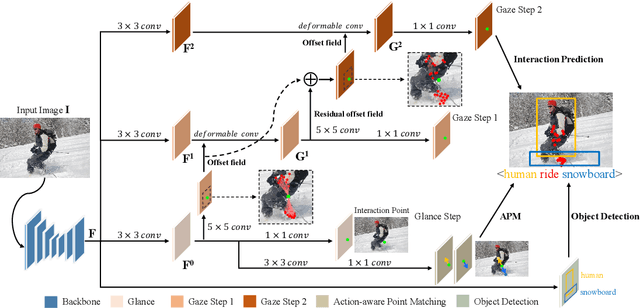
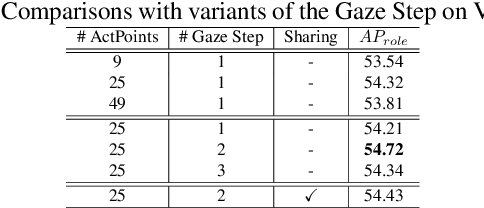
Modern human-object interaction (HOI) detection approaches can be divided into one-stage methods and twostage ones. One-stage models are more efficient due to their straightforward architectures, but the two-stage models are still advantageous in accuracy. Existing one-stage models usually begin by detecting predefined interaction areas or points, and then attend to these areas only for interaction prediction; therefore, they lack reasoning steps that dynamically search for discriminative cues. In this paper, we propose a novel one-stage method, namely Glance and Gaze Network (GGNet), which adaptively models a set of actionaware points (ActPoints) via glance and gaze steps. The glance step quickly determines whether each pixel in the feature maps is an interaction point. The gaze step leverages feature maps produced by the glance step to adaptively infer ActPoints around each pixel in a progressive manner. Features of the refined ActPoints are aggregated for interaction prediction. Moreover, we design an actionaware approach that effectively matches each detected interaction with its associated human-object pair, along with a novel hard negative attentive loss to improve the optimization of GGNet. All the above operations are conducted simultaneously and efficiently for all pixels in the feature maps. Finally, GGNet outperforms state-of-the-art methods by significant margins on both V-COCO and HICODET benchmarks. Code of GGNet is available at https: //github.com/SherlockHolmes221/GGNet.
Polysemy Deciphering Network for Robust Human-Object Interaction Detection
Aug 07, 2020

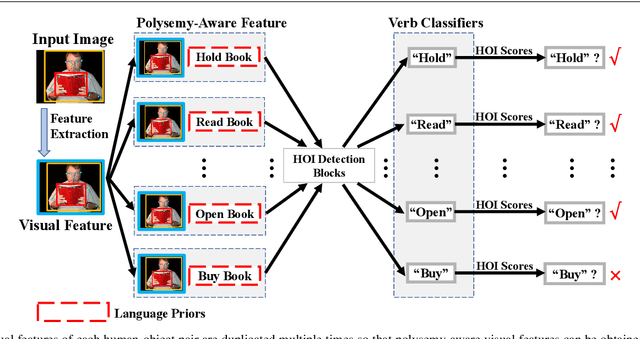

Human-Object Interaction (HOI) detection is important to human-centric scene understanding tasks. Existing works tend to assume that the same verb has similar visual characteristics in different HOI categories, an approach that ignores the diverse semantic meanings of the verb. To address this issue, in this paper, we propose a novel Polysemy Deciphering Network (PD-Net) that decodes the visual polysemy of verbs for HOI detection in three distinct ways. First, we refine features for HOI detection to be polysemyaware through the use of two novel modules: namely, Language Prior-guided Channel Attention (LPCA) and Language Prior-based Feature Augmentation (LPFA). LPCA highlights important elements in human and object appearance features for each HOI category to be identified; moreover, LPFA augments human pose and spatial features for HOI detection using language priors, enabling the verb classifiers to receive language hints that reduce intra-class variation for the same verb. Second, we introduce a novel Polysemy-Aware Modal Fusion module (PAMF), which guides PD-Net to make decisions based on feature types deemed more important according to the language priors. Third, we propose to relieve the verb polysemy problem through sharing verb classifiers for semantically similar HOI categories. Furthermore, to expedite research on the verb polysemy problem, we build a new benchmark dataset named HOI-VerbPolysemy (HOIVP), which includes common verbs (predicates) that have diverse semantic meanings in the real world. Finally, through deciphering the visual polysemy of verbs, our approach is demonstrated to outperform state-of-the-art methods by significant margins on the HICO-DET, V-COCO, and HOI-VP databases. Code and data in this paper will be released at https://github.com/MuchHair/PD-Net.