 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlance and Gaze: Inferring Action-aware Points for One-Stage Human-Object Interaction Detection
Paper and Code
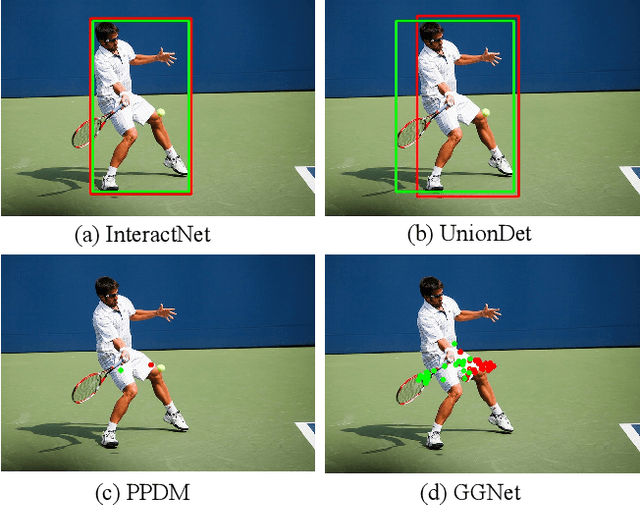
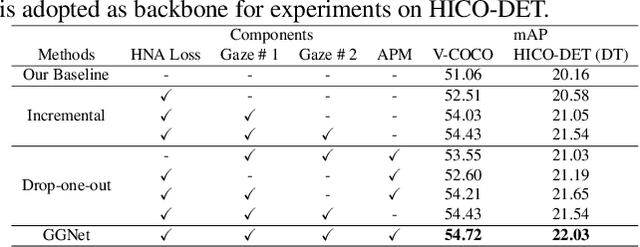
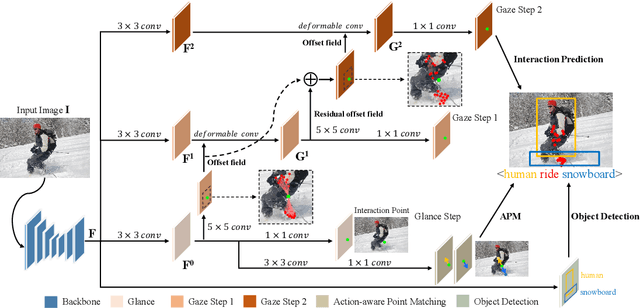
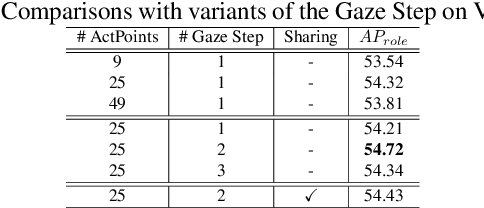
Modern human-object interaction (HOI) detection approaches can be divided into one-stage methods and twostage ones. One-stage models are more efficient due to their straightforward architectures, but the two-stage models are still advantageous in accuracy. Existing one-stage models usually begin by detecting predefined interaction areas or points, and then attend to these areas only for interaction prediction; therefore, they lack reasoning steps that dynamically search for discriminative cues. In this paper, we propose a novel one-stage method, namely Glance and Gaze Network (GGNet), which adaptively models a set of actionaware points (ActPoints) via glance and gaze steps. The glance step quickly determines whether each pixel in the feature maps is an interaction point. The gaze step leverages feature maps produced by the glance step to adaptively infer ActPoints around each pixel in a progressive manner. Features of the refined ActPoints are aggregated for interaction prediction. Moreover, we design an actionaware approach that effectively matches each detected interaction with its associated human-object pair, along with a novel hard negative attentive loss to improve the optimization of GGNet. All the above operations are conducted simultaneously and efficiently for all pixels in the feature maps. Finally, GGNet outperforms state-of-the-art methods by significant margins on both V-COCO and HICODET benchmarks. Code of GGNet is available at https: //github.com/SherlockHolmes221/GGNet.