 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolysemy Deciphering Network for Robust Human-Object Interaction Detection
Paper and Code


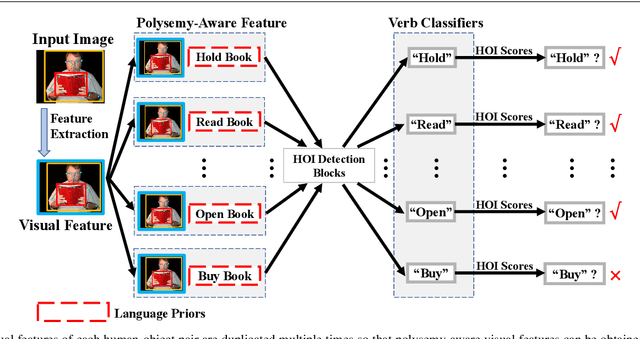

Human-Object Interaction (HOI) detection is important to human-centric scene understanding tasks. Existing works tend to assume that the same verb has similar visual characteristics in different HOI categories, an approach that ignores the diverse semantic meanings of the verb. To address this issue, in this paper, we propose a novel Polysemy Deciphering Network (PD-Net) that decodes the visual polysemy of verbs for HOI detection in three distinct ways. First, we refine features for HOI detection to be polysemyaware through the use of two novel modules: namely, Language Prior-guided Channel Attention (LPCA) and Language Prior-based Feature Augmentation (LPFA). LPCA highlights important elements in human and object appearance features for each HOI category to be identified; moreover, LPFA augments human pose and spatial features for HOI detection using language priors, enabling the verb classifiers to receive language hints that reduce intra-class variation for the same verb. Second, we introduce a novel Polysemy-Aware Modal Fusion module (PAMF), which guides PD-Net to make decisions based on feature types deemed more important according to the language priors. Third, we propose to relieve the verb polysemy problem through sharing verb classifiers for semantically similar HOI categories. Furthermore, to expedite research on the verb polysemy problem, we build a new benchmark dataset named HOI-VerbPolysemy (HOIVP), which includes common verbs (predicates) that have diverse semantic meanings in the real world. Finally, through deciphering the visual polysemy of verbs, our approach is demonstrated to outperform state-of-the-art methods by significant margins on the HICO-DET, V-COCO, and HOI-VP databases. Code and data in this paper will be released at https://github.com/MuchHair/PD-Net.