 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeFlowSLAM: Self-Supervised Scene Motion Decomposition for Dynamic Dense SLAM
Jul 18, 2022

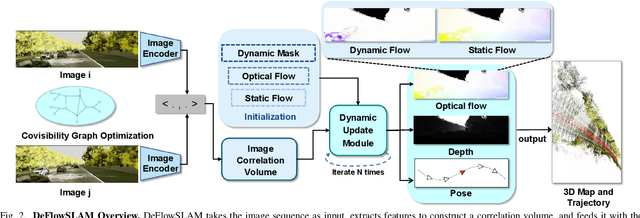
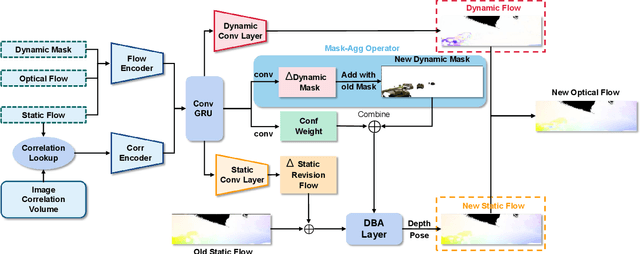
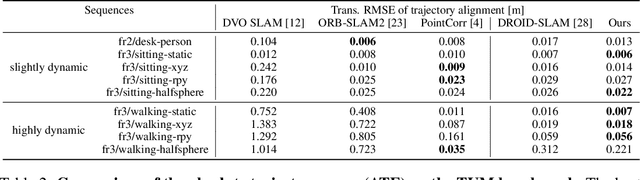
We present a novel dual-flow representation of scene motion that decomposes the optical flow into a static flow field caused by the camera motion and another dynamic flow field caused by the objects' movements in the scene. Based on this representation, we present a dynamic SLAM, dubbed DeFlowSLAM, that exploits both static and dynamic pixels in the images to solve the camera poses, rather than simply using static background pixels as other dynamic SLAM systems do. We propose a dynamic update module to train our DeFlowSLAM in a self-supervised manner, where a dense bundle adjustment layer takes in estimated static flow fields and the weights controlled by the dynamic mask and outputs the residual of the optimized static flow fields, camera poses, and inverse depths. The static and dynamic flow fields are estimated by warping the current image to the neighboring images, and the optical flow can be obtained by summing the two fields. Extensive experiments demonstrate that DeFlowSLAM generalizes well to both static and dynamic scenes as it exhibits comparable performance to the state-of-the-art DROID-SLAM in static and less dynamic scenes while significantly outperforming DROID-SLAM in highly dynamic environments. Code and data are available on the project webpage: \urlstyle{tt} \textcolor{url_color}{\url{https://zju3dv.github.io/deflowslam/}}.
PVO: Panoptic Visual Odometry
Jul 04, 2022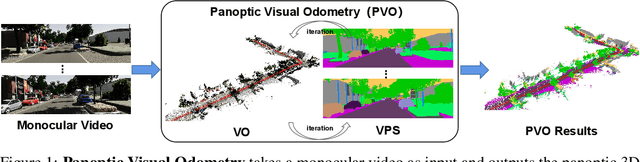
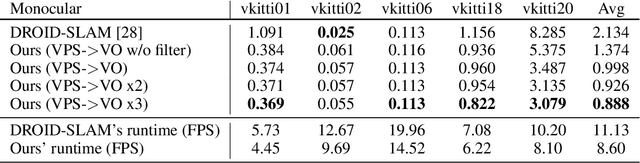
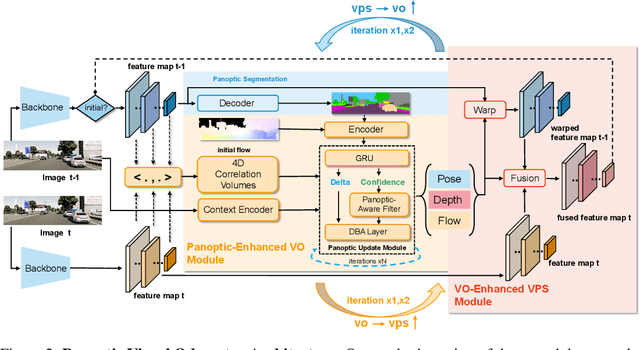
We present a novel panoptic visual odometry framework, termed PVO, to achieve a more comprehensive modeling of the scene's motion, geometry, and panoptic segmentation information. PVO models visual odometry (VO) and video panoptic segmentation (VPS) in a unified view, enabling the two tasks to facilitate each other. Specifically, we introduce a panoptic update module into the VO module, which operates on the image panoptic segmentation. This Panoptic-Enhanced VO module can trim the interference of dynamic objects in the camera pose estimation by adjusting the weights of optimized camera poses. On the other hand, the VO-Enhanced VPS module improves the segmentation accuracy by fusing the panoptic segmentation result of the current frame on the fly to the adjacent frames, using geometric information such as camera pose, depth, and optical flow obtained from the VO module. These two modules contribute to each other through a recurrent iterative optimization. Extensive experiments demonstrate that PVO outperforms state-of-the-art methods in both visual odometry and video panoptic segmentation tasks. Code and data are available on the project webpage: \urlstyle{tt} \textcolor{url_color}{\url{https://zju3dv.github.io/pvo/}}.
Hybrid Tracker with Pixel and Instance for Video Panoptic Segmentation
Mar 02, 2022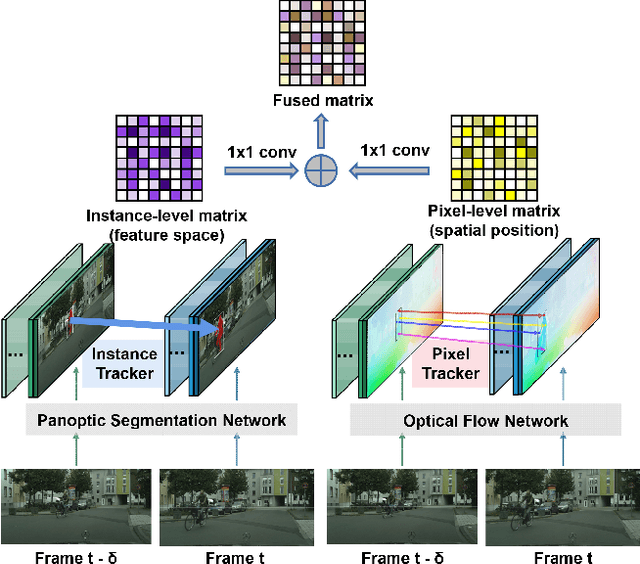
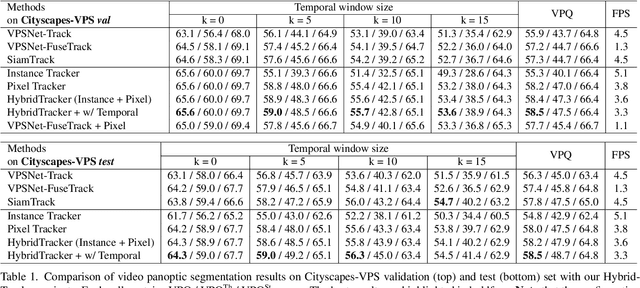
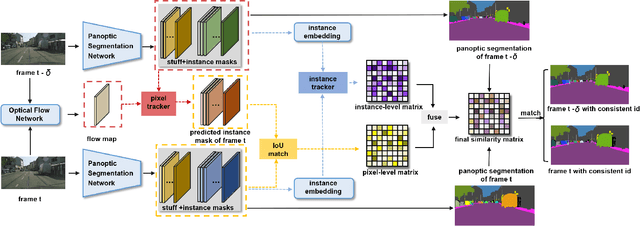
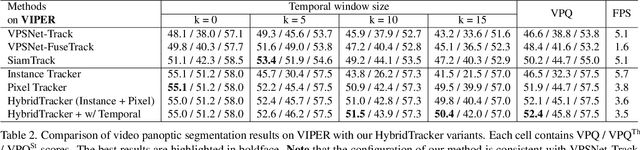
Video Panoptic Segmentation (VPS) requires generating consistent panoptic segmentation and tracking identities to all pixels across video frames. Existing methods are mainly based on the trained instance embedding to maintain consistent panoptic segmentation. However, they inevitably struggle to cope with the challenges of small objects, similar appearance but inconsistent identities, occlusion, and strong instance contour deformations. To address these problems, we present HybridTracker, a lightweight and joint tracking model attempting to eliminate the limitations of the single tracker. HybridTracker performs pixel tracker and instance tracker in parallel to obtain the association matrices, which are fused into a matching matrix. In the instance tracker, we design a differentiable matching layer, ensuring the stability of inter-frame matching. In the pixel tracker, we compute the dice coefficient of the same instance of different frames given the estimated optical flow, forming the Intersection Over Union (IoU) matrix. We additionally propose mutual check and temporal consistency constraints during inference to settle the occlusion and contour deformation challenges. Extensive experiments demonstrate that HybridTracker outperforms state-of-the-art methods on Cityscapes-VPS and VIPER datasets.