 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChemGymRL: An Interactive Framework for Reinforcement Learning for Digital Chemistry
May 23, 2023



This paper provides a simulated laboratory for making use of Reinforcement Learning (RL) for chemical discovery. Since RL is fairly data intensive, training agents `on-the-fly' by taking actions in the real world is infeasible and possibly dangerous. Moreover, chemical processing and discovery involves challenges which are not commonly found in RL benchmarks and therefore offer a rich space to work in. We introduce a set of highly customizable and open-source RL environments, ChemGymRL, based on the standard Open AI Gym template. ChemGymRL supports a series of interconnected virtual chemical benches where RL agents can operate and train. The paper introduces and details each of these benches using well-known chemical reactions as illustrative examples, and trains a set of standard RL algorithms in each of these benches. Finally, discussion and comparison of the performances of several standard RL methods are provided in addition to a list of directions for future work as a vision for the further development and usage of ChemGymRL.
Dynamic programming with partial information to overcome navigational uncertainty in a nautical environment
Dec 29, 2021
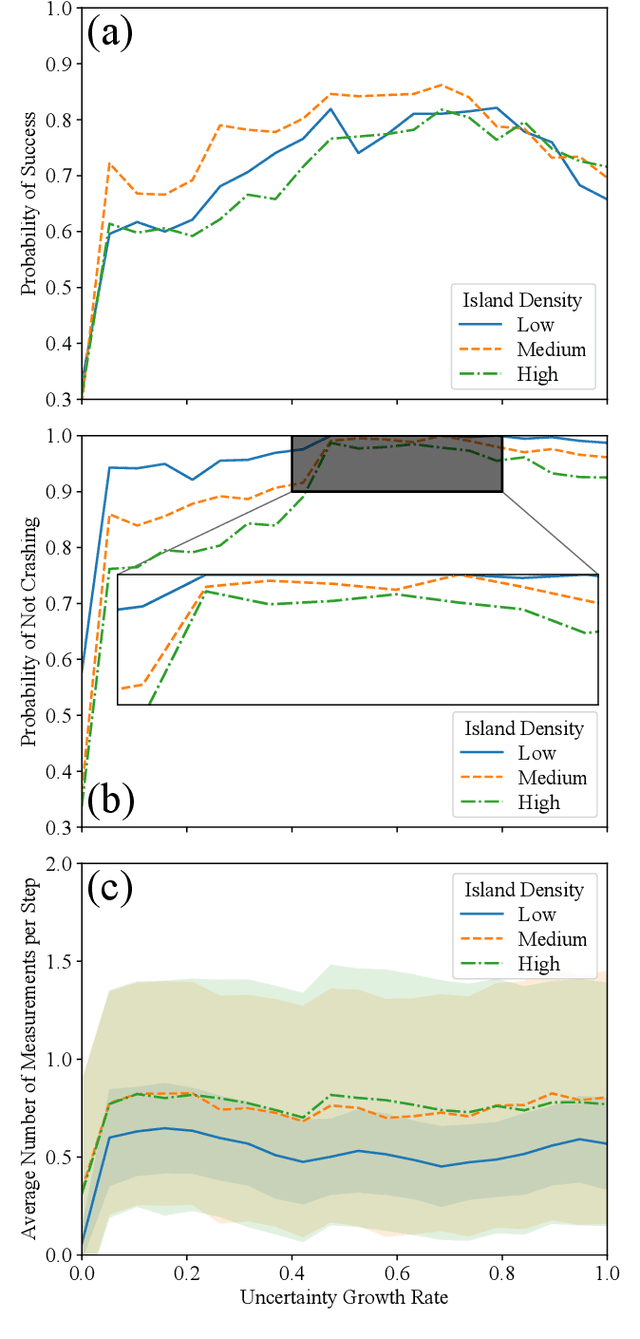
Using a toy nautical navigation environment, we show that dynamic programming can be used when only partial information about a partially observed Markov decision process (POMDP) is known. By incorporating uncertainty into our model, we show that navigation policies can be constructed that maintain safety. Adding controlled sensing methods, we show that these policies can also lower measurement costs at the same time.