 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEWMoE: An effective model for global weather forecasting with mixture-of-experts
May 09, 2024



Weather forecasting is a crucial task for meteorologic research, with direct social and economic impacts. Recently, data-driven weather forecasting models based on deep learning have shown great potential, achieving superior performance compared with traditional numerical weather prediction methods. However, these models often require massive training data and computational resources. In this paper, we propose EWMoE, an effective model for accurate global weather forecasting, which requires significantly less training data and computational resources. Our model incorporates three key components to enhance prediction accuracy: meteorology-specific embedding, a core Mixture-of-Experts (MoE) layer, and two specific loss functions. We conduct our evaluation on the ERA5 dataset using only two years of training data. Extensive experiments demonstrate that EWMoE outperforms current models such as FourCastNet and ClimaX at all forecast time, achieving competitive performance compared with the state-of-the-art Pangu-Weather model in evaluation metrics such as Anomaly Correlation Coefficient (ACC) and Root Mean Square Error (RMSE). Additionally, ablation studies indicate that applying the MoE architecture to weather forecasting offers significant advantages in improving accuracy and resource efficiency.
ESTISR: Adapting Efficient Scene Text Image Super-resolution for Real-Scenes
Jun 04, 2023



While scene text image super-resolution (STISR) has yielded remarkable improvements in accurately recognizing scene text, prior methodologies have placed excessive emphasis on optimizing performance, rather than paying due attention to efficiency - a crucial factor in ensuring deployment of the STISR-STR pipeline. In this work, we propose a novel Efficient Scene Text Image Super-resolution (ESTISR) Network for resource-limited deployment platform. ESTISR's functionality primarily depends on two critical components: a CNN-based feature extractor and an efficient self-attention mechanism used for decoding low-resolution images. We designed a re-parameterized inverted residual block specifically suited for resource-limited circumstances as the feature extractor. Meanwhile, we proposed a novel self-attention mechanism, softmax shrinking, based on a kernel-based approach. This innovative technique offers linear complexity while also naturally incorporating discriminating low-level features into the self-attention structure. Extensive experiments on TextZoom show that ESTISR retains a high image restoration quality and improved STR accuracy of low-resolution images. Furthermore, ESTISR consistently outperforms current methods in terms of actual running time and peak memory consumption, while achieving a better trade-off between performance and efficiency.
W-MAE: Pre-trained weather model with masked autoencoder for multi-variable weather forecasting
Apr 18, 2023



Weather forecasting is a long-standing computational challenge with direct societal and economic impacts. This task involves a large amount of continuous data collection and exhibits rich spatiotemporal dependencies over long periods, making it highly suitable for deep learning models. In this paper, we apply pre-training techniques to weather forecasting and propose W-MAE, a Weather model with Masked AutoEncoder pre-training for multi-variable weather forecasting. W-MAE is pre-trained in a self-supervised manner to reconstruct spatial correlations within meteorological variables. On the temporal scale, we fine-tune the pre-trained W-MAE to predict the future states of meteorological variables, thereby modeling the temporal dependencies present in weather data. We pre-train W-MAE using the fifth-generation ECMWF Reanalysis (ERA5) data, with samples selected every six hours and using only two years of data. Under the same training data conditions, we compare W-MAE with FourCastNet, and W-MAE outperforms FourCastNet in precipitation forecasting. In the setting where the training data is far less than that of FourCastNet, our model still performs much better in precipitation prediction (0.80 vs. 0.98). Additionally, experiments show that our model has a stable and significant advantage in short-to-medium-range forecasting (i.e., forecasting time ranges from 6 hours to one week), and the longer the prediction time, the more evident the performance advantage of W-MAE, further proving its robustness.
Nearly Optimal Robust Method for Convex Compositional Problems with Heavy-Tailed Noise
Jun 17, 2020
In this paper, we propose robust stochastic algorithms for solving convex compositional problems of the form $f(\E_\xi g(\cdot; \xi)) + r(\cdot)$ by establishing {\bf sub-Gaussian confidence bounds} under weak assumptions about the tails of noise distribution, i.e., {\bf heavy-tailed noise} with bounded second-order moments. One can achieve this goal by using an existing boosting strategy that boosts a low probability convergence result into a high probability result. However, piecing together existing results for solving compositional problems suffers from several drawbacks: (i) the boosting technique requires strong convexity of the objective; (ii) it requires a separate algorithm to handle non-smooth $r$; (iii) it also suffers from an additional polylogarithmic factor of the condition number. To address these issues, we directly develop a single-trial stochastic algorithm for minimizing optimal strongly convex compositional objectives, which has a nearly optimal high probability convergence result matching the lower bound of stochastic strongly convex optimization up to a logarithmic factor. To the best of our knowledge, this is the first work that establishes nearly optimal sub-Gaussian confidence bounds for compositional problems under heavy-tailed assumptions.
The best way to select features?
May 26, 2020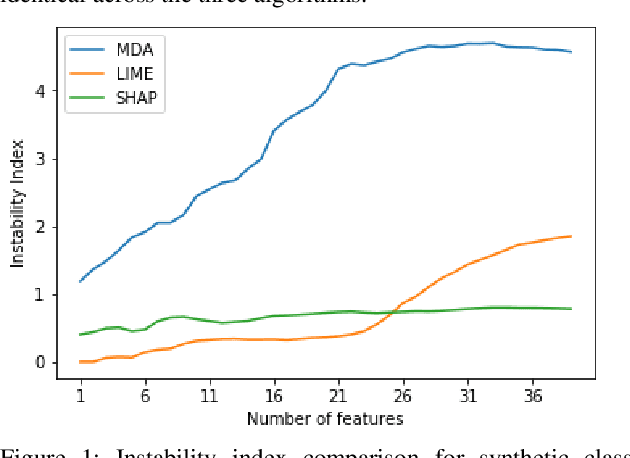

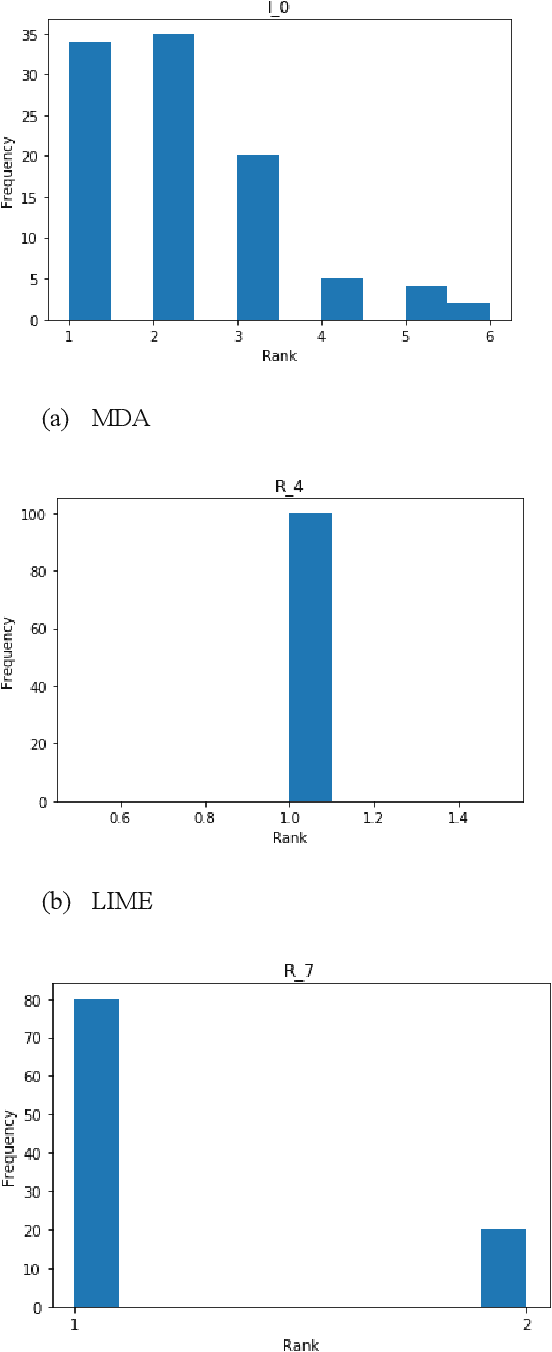
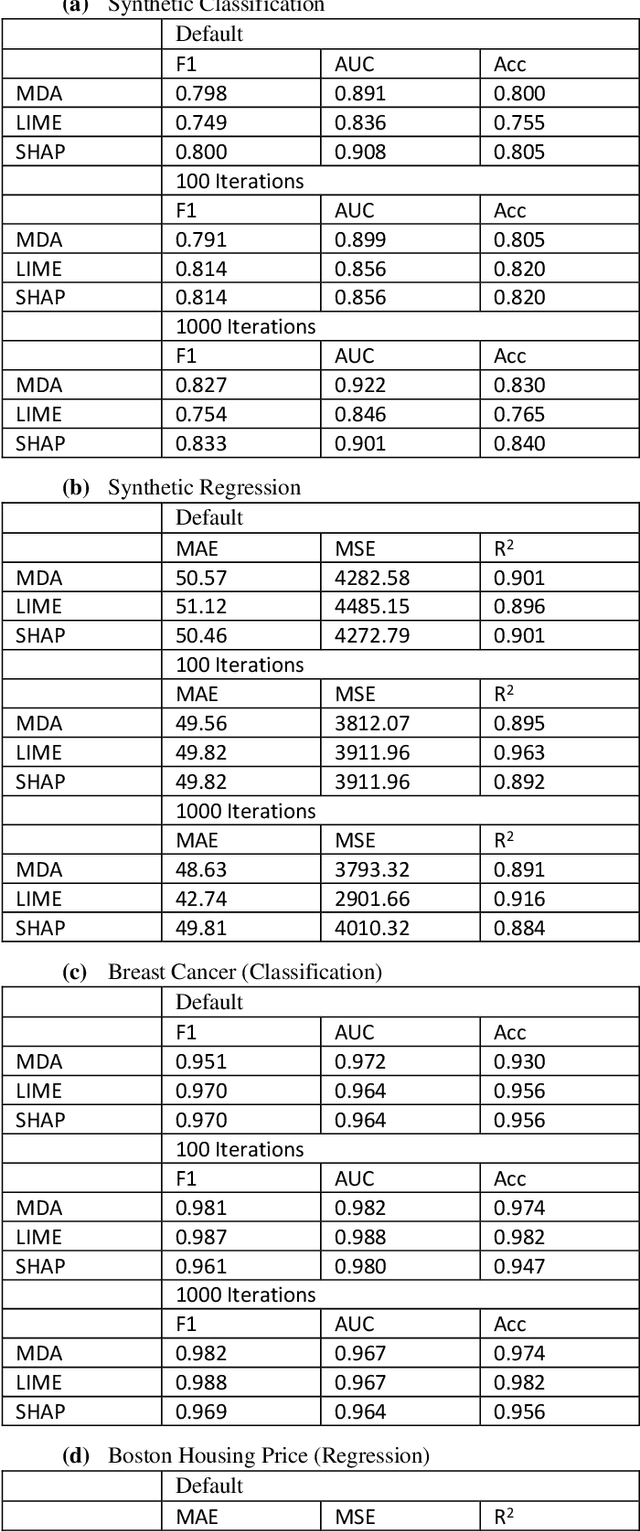
Feature selection in machine learning is subject to the intrinsic randomness of the feature selection algorithms (for example, random permutations during MDA). Stability of selected features with respect to such randomness is essential to the human interpretability of a machine learning algorithm. We proposes a rank based stability metric called instability index to compare the stabilities of three feature selection algorithms MDA, LIME, and SHAP as applied to random forests. Typically, features are selected by averaging many random iterations of a selection algorithm. Though we find that the variability of the selected features does decrease as the number of iterations increases, it does not go to zero, and the features selected by the three algorithms do not necessarily converge to the same set. We find LIME and SHAP to be more stable than MDA, and LIME is at least as stable as SHAP for the top ranked features. Hence overall LIME is best suited for human interpretability. However, the selected set of features from all three algorithms significantly improves various predictive metrics out of sample, and their predictive performances do not differ significantly. Experiments were conducted on synthetic datasets, two public benchmark datasets, and on proprietary data from an active investment strategy.