 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe best way to select features?
May 26, 2020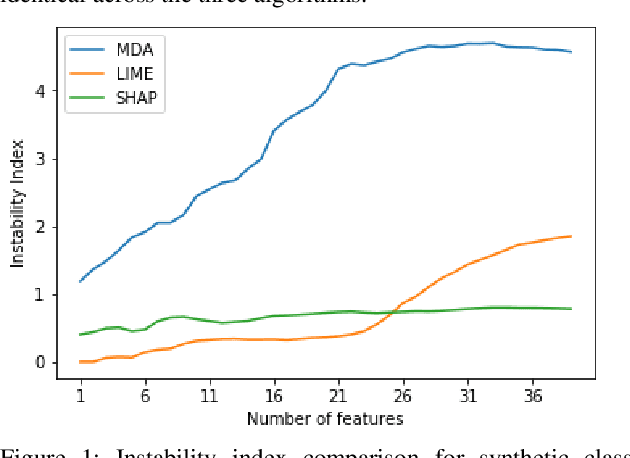

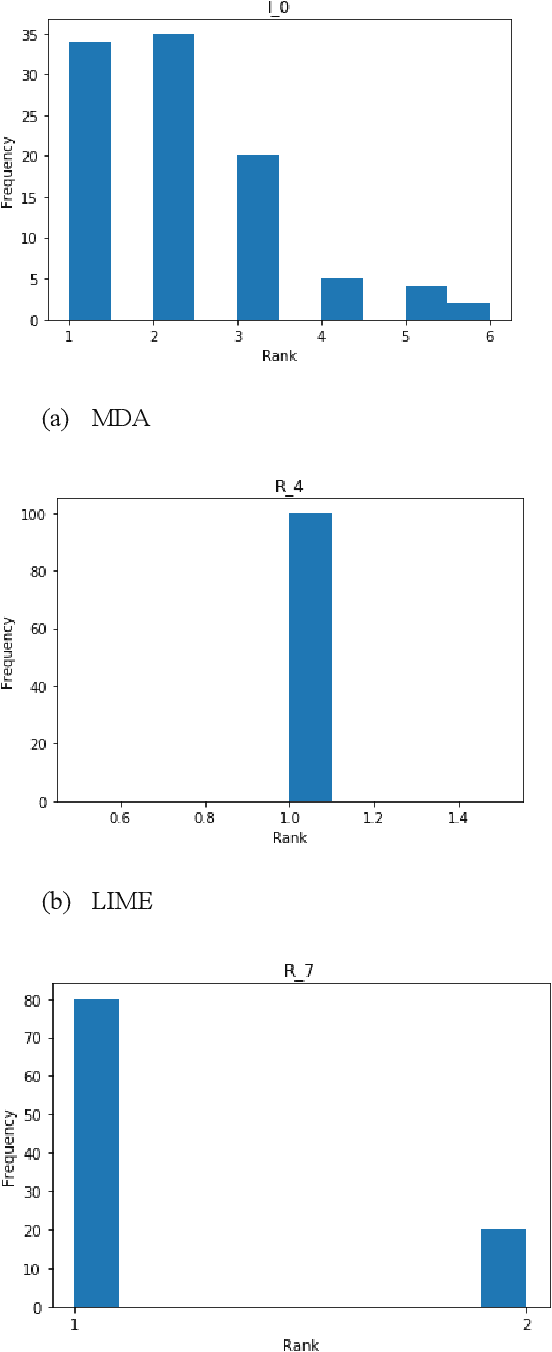
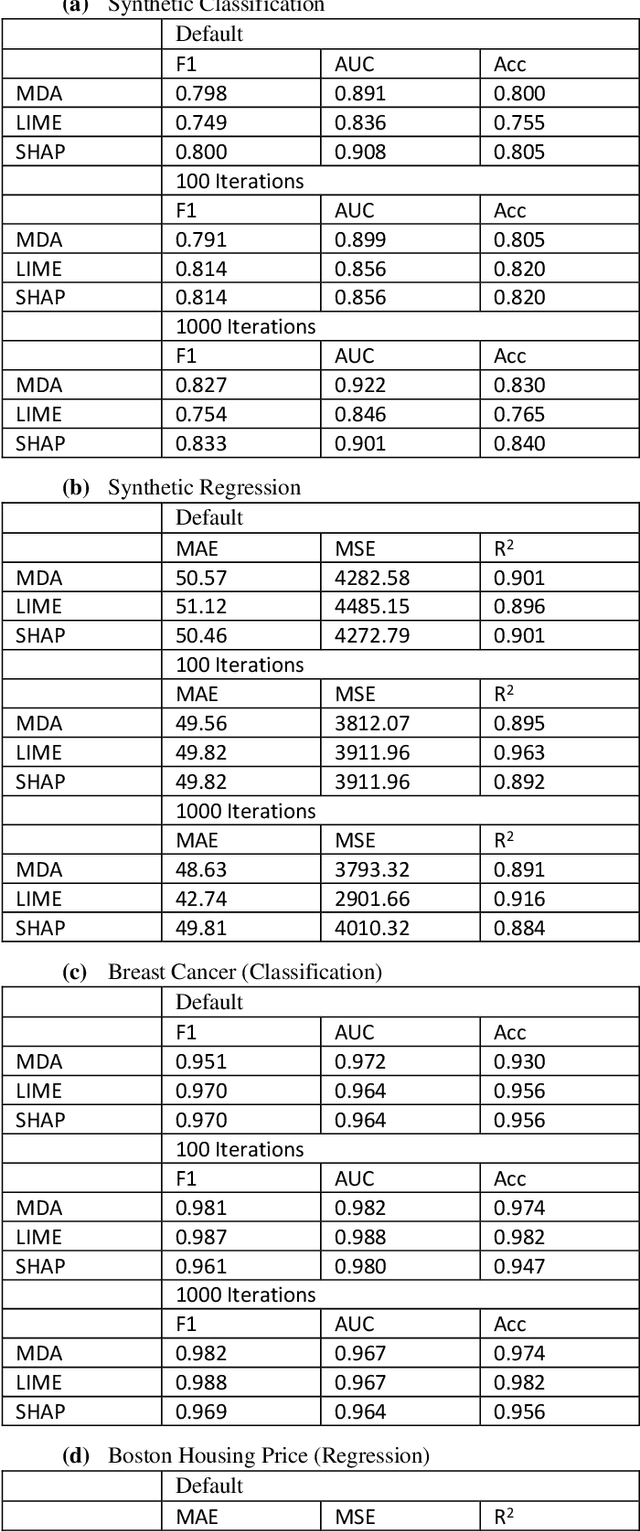
Feature selection in machine learning is subject to the intrinsic randomness of the feature selection algorithms (for example, random permutations during MDA). Stability of selected features with respect to such randomness is essential to the human interpretability of a machine learning algorithm. We proposes a rank based stability metric called instability index to compare the stabilities of three feature selection algorithms MDA, LIME, and SHAP as applied to random forests. Typically, features are selected by averaging many random iterations of a selection algorithm. Though we find that the variability of the selected features does decrease as the number of iterations increases, it does not go to zero, and the features selected by the three algorithms do not necessarily converge to the same set. We find LIME and SHAP to be more stable than MDA, and LIME is at least as stable as SHAP for the top ranked features. Hence overall LIME is best suited for human interpretability. However, the selected set of features from all three algorithms significantly improves various predictive metrics out of sample, and their predictive performances do not differ significantly. Experiments were conducted on synthetic datasets, two public benchmark datasets, and on proprietary data from an active investment strategy.