 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-shot sketch-based remote sensing image retrieval based on multi-level and attention-guided tokenization
Feb 03, 2024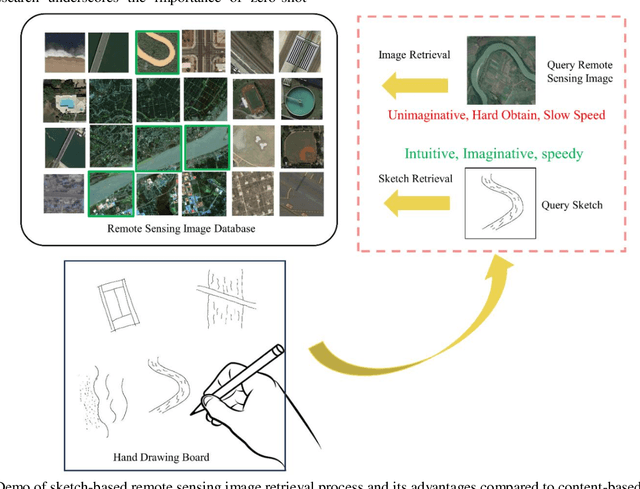



Effectively and efficiently retrieving images from remote sensing databases is a critical challenge in the realm of remote sensing big data. Utilizing hand-drawn sketches as retrieval inputs offers intuitive and user-friendly advantages, yet the potential of multi-level feature integration from sketches remains underexplored, leading to suboptimal retrieval performance. To address this gap, our study introduces a novel zero-shot, sketch-based retrieval method for remote sensing images, leveraging multi-level, attention-guided tokenization. This approach starts by employing multi-level self-attention feature extraction to tokenize the query sketches, as well as self-attention feature extraction to tokenize the candidate images. It then employs cross-attention mechanisms to establish token correspondence between these two modalities, facilitating the computation of sketch-to-image similarity. Our method demonstrates superior retrieval accuracy over existing sketch-based remote sensing image retrieval techniques, as evidenced by tests on four datasets. Notably, it also exhibits robust zero-shot learning capabilities and strong generalizability in handling unseen categories and novel remote sensing data. The method's scalability can be further enhanced by the pre-calculation of retrieval tokens for all candidate images in a database. This research underscores the significant potential of multi-level, attention-guided tokenization in cross-modal remote sensing image retrieval. For broader accessibility and research facilitation, we have made the code and dataset used in this study publicly available online. Code and dataset are available at https://github.com/Snowstormfly/Cross-modal-retrieval-MLAGT.
Learning a Dilated Residual Network for SAR Image Despeckling
Jan 24, 2018
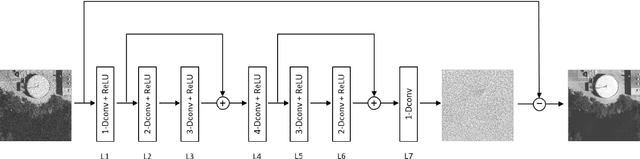


In this paper, to break the limit of the traditional linear models for synthetic aperture radar (SAR) image despeckling, we propose a novel deep learning approach by learning a non-linear end-to-end mapping between the noisy and clean SAR images with a dilated residual network (SAR-DRN). SAR-DRN is based on dilated convolutions, which can both enlarge the receptive field and maintain the filter size and layer depth with a lightweight structure. In addition, skip connections and residual learning strategy are added to the despeckling model to maintain the image details and reduce the vanishing gradient problem. Compared with the traditional despeckling methods, the proposed method shows superior performance over the state-of-the-art methods on both quantitative and visual assessments, especially for strong speckle noise.