 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwitching Pushing Skill Combined MPC and Deep Reinforcement Learning for Planar Non-prehensile Manipulation
Mar 30, 2023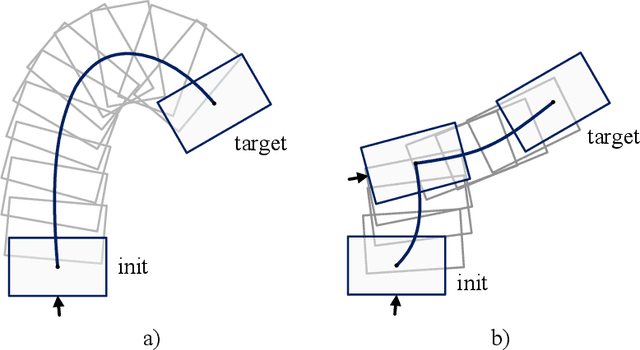
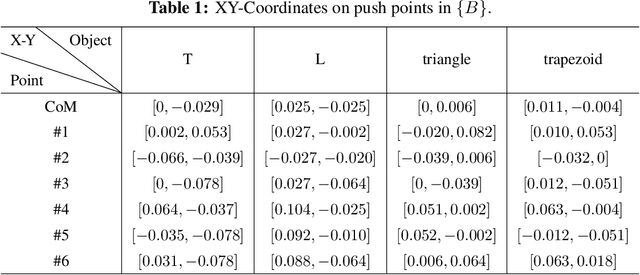
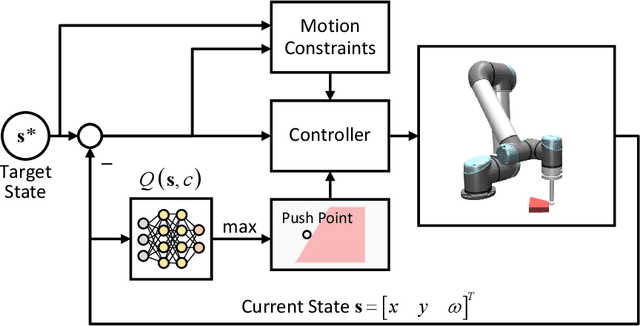

In this paper, a novel switching pushing skill algorithm is proposed to improve the efficiency of planar non-prehensile manipulation, which draws inspiration from human pushing actions and comprises two sub-problems, i.e., discrete decision-making of pushing point and continuous feedback control of pushing action. In order to solve the sub-problems above, a combination of Model Predictive Control (MPC) and Deep Reinforcement Learning (DRL) method is employed. Firstly, the selection of pushing point is modeled as a Markov decision process,and an off-policy DRL method is used by reshaping the reward function to train the decision-making model for selecting pushing point from a pre-constructed set based on the current state. Secondly, a motion constraint region (MCR) is constructed for the specific pushing point based on the distance from the target, followed by utilizing the MPC controller to regulate the motion of the object within the MCR towards the target pose. The trigger condition for switching the pushing point occurs when the object reaches the boundary of the MCR under the pushing action. Subsequently, the pushing point and the controller are updated iteratively until the target pose is reached. We conducted pushing experiments on four distinct object shapes in both simulated and physical environments to evaluate our method. The results indicate that our method achieves a significantly higher training efficiency, with a training time that is only about 20% of the baseline method while maintaining around the same success rate. Moreover, our method outperforms the baseline method in terms of both training and execution efficiency of pushing operations, allowing for rapid learning of robot pushing skills.
Integrated Task Assignment and Path Planning for Capacitated Multi-Agent Pickup and Delivery
Oct 28, 2021
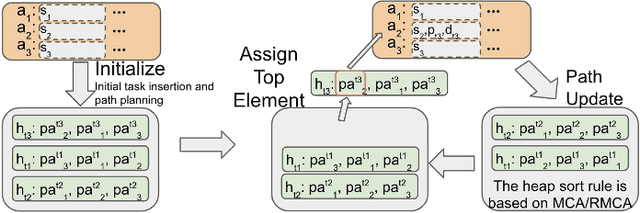

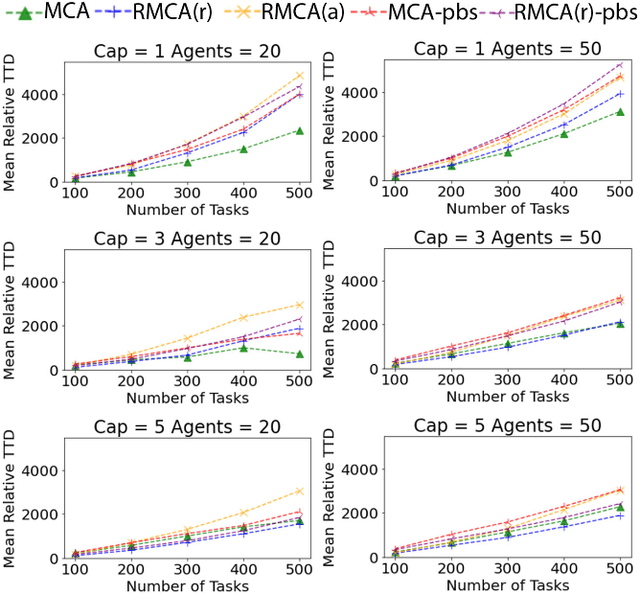
Multi-agent Pickup and Delivery (MAPD) is a challenging industrial problem where a team of robots is tasked with transporting a set of tasks, each from an initial location and each to a specified target location. Appearing in the context of automated warehouse logistics and automated mail sortation, MAPD requires first deciding which robot is assigned what task (i.e., Task Assignment or TA) followed by a subsequent coordination problem where each robot must be assigned collision-free paths so as to successfully complete its assignment (i.e., Multi-Agent Path Finding or MAPF). Leading methods in this area solve MAPD sequentially: first assigning tasks, then assigning paths. In this work we propose a new coupled method where task assignment choices are informed by actual delivery costs instead of by lower-bound estimates. The main ingredients of our approach are a marginal-cost assignment heuristic and a meta-heuristic improvement strategy based on Large Neighbourhood Search. As a further contribution, we also consider a variant of the MAPD problem where each robot can carry multiple tasks instead of just one. Numerical simulations show that our approach yields efficient and timely solutions and we report significant improvement compared with other recent methods from the literature.
Target assignment for robots constrained by limited communication range
Feb 15, 2017
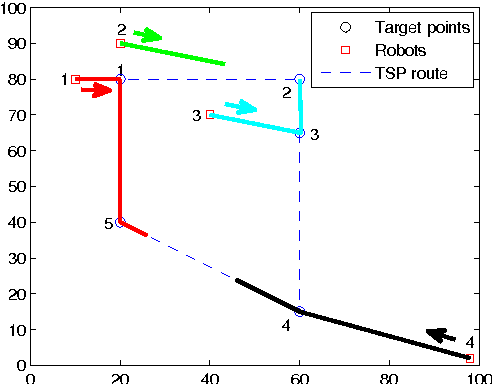
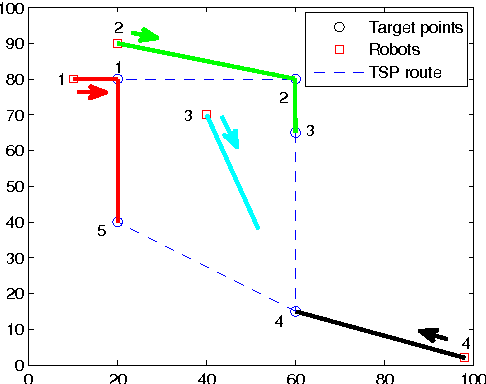
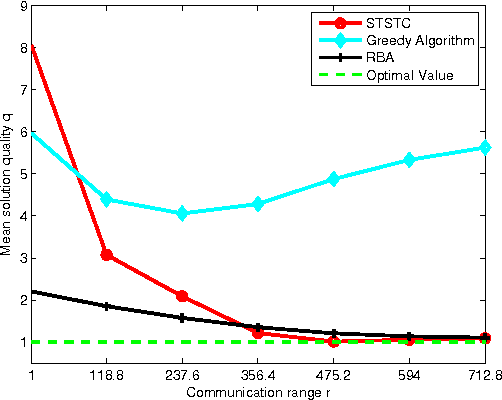
This paper investigates the task assignment problem for multiple dispersed robots constrained by limited communication range. The robots are initially randomly distributed and need to visit several target locations while minimizing the total travel time. A centralized rendezvous-based algorithm is proposed, under which all the robots first move towards a rendezvous position until communication paths are established between every pair of robots either directly or through intermediate peers, and then one robot is chosen as the leader to make a centralized task assignment for the other robots. Furthermore, we propose a decentralized algorithm based on a single-traveling-salesman tour, which does not require all the robots to be connected through communication. We investigate the variation of the quality of the assignment solutions as the level of information sharing increases and as the communication range grows, respectively. The proposed algorithms are compared with a centralized algorithm with shared global information and a decentralized greedy algorithm respectively. Monte Carlo simulation results show the satisfying performance of the proposed algorithms.