 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Attention Aware Feature Learning for Person Re-Identification
Mar 01, 2020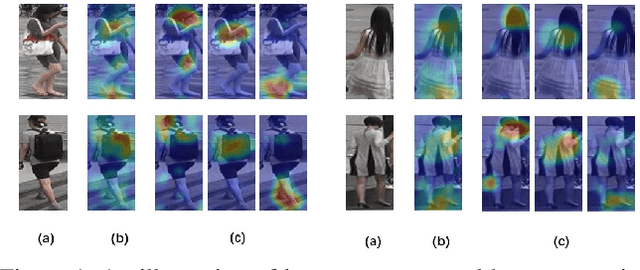

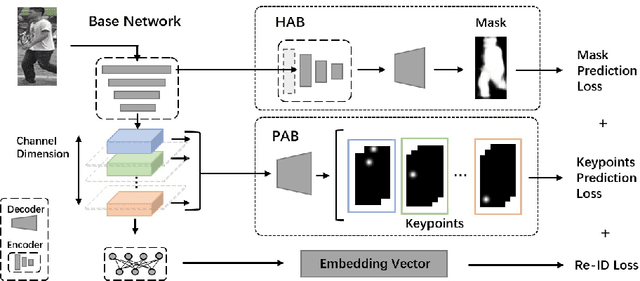
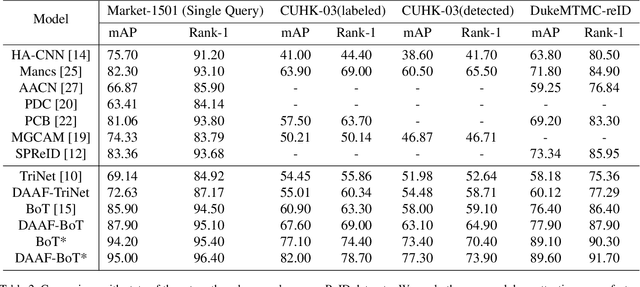
Visual attention has proven to be effective in improving the performance of person re-identification. Most existing methods apply visual attention heuristically by learning an additional attention map to re-weight the feature maps for person re-identification. However, this kind of methods inevitably increase the model complexity and inference time. In this paper, we propose to incorporate the attention learning as additional objectives in a person ReID network without changing the original structure, thus maintain the same inference time and model size. Two kinds of attentions have been considered to make the learned feature maps being aware of the person and related body parts respectively. Globally, a holistic attention branch (HAB) makes the feature maps obtained by backbone focus on persons so as to alleviate the influence of background. Locally, a partial attention branch (PAB) makes the extracted features be decoupled into several groups and be separately responsible for different body parts (i.e., keypoints), thus increasing the robustness to pose variation and partial occlusion. These two kinds of attentions are universal and can be incorporated into existing ReID networks. We have tested its performance on two typical networks (TriNet and Bag of Tricks) and observed significant performance improvement on five widely used datasets.
Predicting People's 3D Poses from Short Sequences
Nov 23, 2015



We propose an efficient approach to exploiting motion information from consecutive frames of a video sequence to recover the 3D pose of people. Instead of computing candidate poses in individual frames and then linking them, as is often done, we regress directly from a spatio-temporal block of frames to a 3D pose in the central one. We will demonstrate that this approach allows us to effectively overcome ambiguities and to improve upon the state-of-the-art on challenging sequences.