 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficient Dual-reference Training Data Acquisition Method for CNN-Based Image Super-Resolution
Sep 02, 2021



For deep learning methods of image super-resolution, the most critical issue is whether the paired low and high resolution images for training accurately reflect the sampling process of real cameras. Low and high resolution (LR$\sim$HR) image pairs synthesized by existing degradation models (e.g. bicubic downsampling) deviate from those in reality; thus the super-resolution CNN trained by these synthesized LR$\sim$HR image pairs does not perform well when being applied to real images. In this paper, we propose a novel method to capture a large set of realistic LR$\sim$HR image pairs using real cameras. The data acquisition is carried out under controllable lab conditions with minimum human intervention and at high throughput (about 500 image pairs per hour). The high level of automation makes it easy to produce a set of real LR$\sim$HR training image pairs for each camera.Our innovation is to shoot images displayed on an ultra-high quality screen at different resolutions. There are three distinctive advantages of our method for image super-resolution. First, as the LR and HR images are taken of a 3D planar surface (the screen) the registration problem fits exactly to a homography model and we can display specially designed markers on the image to improve the registration precision. Second, the displayed digital image file can be exploited as a reference to optimize the high frequency content of the restored image. Third, this high-efficiency data collection method makes it possible to collect a customized dataset for each camera sensor, for which one can train a specific model for the intended camera sensor. Experimental results show that training a super-resolution CNN by our LR$\sim$HR dataset has superior restoration performance than training it by existing datasets on real world images at the inference stage.
Deep Learning with Inaccurate Training Data for Image Restoration
Nov 18, 2018
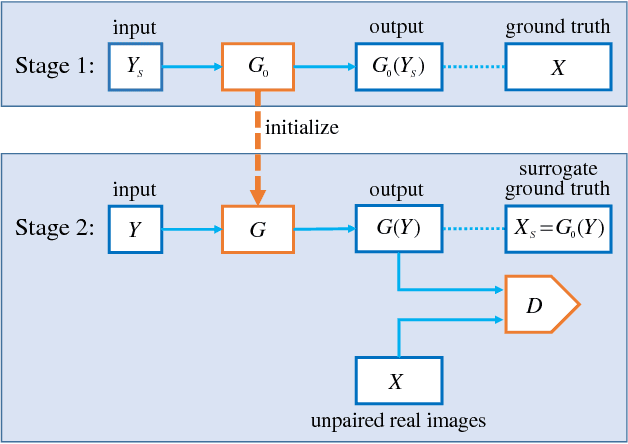


In many applications of deep learning, particularly those in image restoration, it is either very difficult, prohibitively expensive, or outright impossible to obtain paired training data precisely as in the real world. In such cases, one is forced to use synthesized paired data to train the deep convolutional neural network (DCNN). However, due to the unavoidable generalization error in statistical learning, the synthetically trained DCNN often performs poorly on real world data. To overcome this problem, we propose a new general training method that can compensate for, to a large extent, the generalization errors of synthetically trained DCNNs.
On Numerosity of Deep Convolutional Neural Networks
Jul 11, 2018
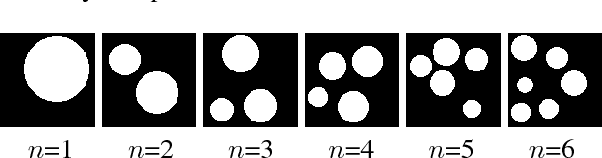
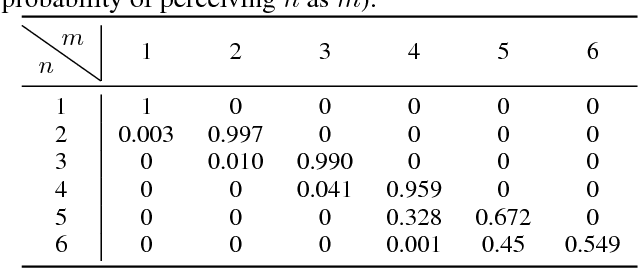

Subitizing, or the sense of small natural numbers, is a cognitive construct so primary and critical to the survival and well-being of humans and primates that is considered and proven to be innate; it responds to visual stimuli prior to the development of any symbolic skills, language or arithmetic. Given highly acclaimed successes of deep convolutional neural networks (DCNN) in tasks of visual intelligence, one would expect that DCNNs can learn subitizing. But somewhat surprisingly, our carefully crafted extensive experiments, which are similar to those of cognitive psychology, demonstrate that DCNNs cannot, even with strong supervision, see through superficial variations in visual representations and distill the abstract notion of natural number, a task that children perform with high accuracy and confidence. The DCNN black box learners driven by very large training sets are apparently still confused by geometric variations and fail to grasp the topological essence in subitizing. In sharp contrast to the failures of the black box learning, by incorporating a mechanism of mathematical morphology into convolutional kernels, we are able to construct a recurrent convolutional neural network that can perform subitizing deterministically. Our findings in this study of cognitive computing, without and with prior of human knowledge, are discussed; they are, we believe, significant and thought-provoking in the interests of AI research, because visual-based numerosity is a benchmark of minimum sort for human cognition.
Demoiréing of Camera-Captured Screen Images Using Deep Convolutional Neural Network
Apr 11, 2018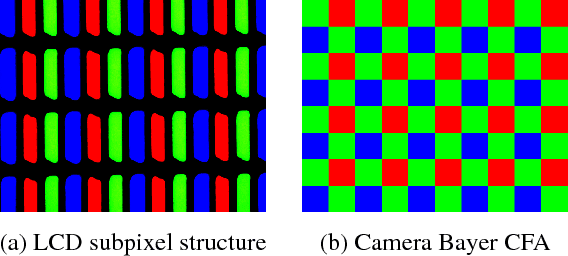


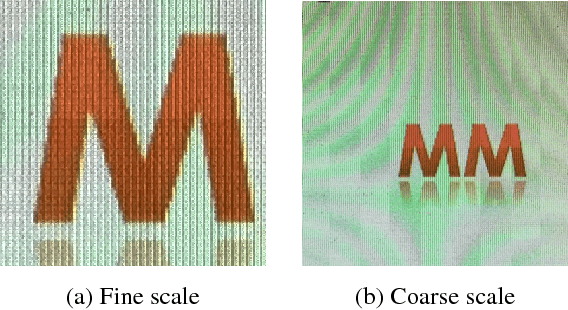
Taking photos of optoelectronic displays is a direct and spontaneous way of transferring data and keeping records, which is widely practiced. However, due to the analog signal interference between the pixel grids of the display screen and camera sensor array, objectionable moir\'e (alias) patterns appear in captured screen images. As the moir\'e patterns are structured and highly variant, they are difficult to be completely removed without affecting the underneath latent image. In this paper, we propose an approach of deep convolutional neural network for demoir\'eing screen photos. The proposed DCNN consists of a coarse-scale network and a fine-scale network. In the coarse-scale network, the input image is first downsampled and then processed by stacked residual blocks to remove the moir\'e artifacts. After that, the fine-scale network upsamples the demoir\'ed low-resolution image back to the original resolution. Extensive experimental results have demonstrated that the proposed technique can efficiently remove the moir\'e patterns for camera acquired screen images; the new technique outperforms the existing ones.
Learning-Based Dequantization For Image Restoration Against Extremely Poor Illumination
Mar 20, 2018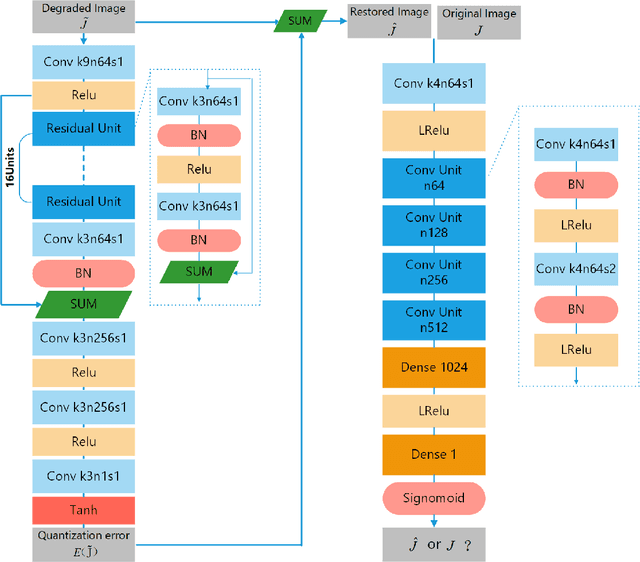
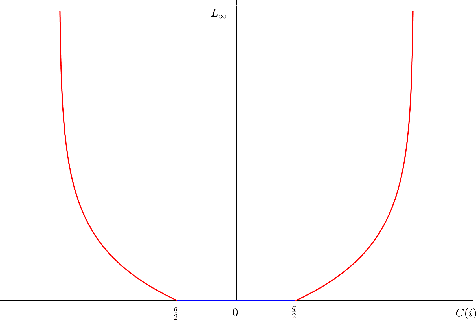


All existing image enhancement methods, such as HDR tone mapping, cannot recover A/D quantization losses due to insufficient or excessive lighting, (underflow and overflow problems). The loss of image details due to A/D quantization is complete and it cannot be recovered by traditional image processing methods, but the modern data-driven machine learning approach offers a much needed cure to the problem. In this work we propose a novel approach to restore and enhance images acquired in low and uneven lighting. First, the ill illumination is algorithmically compensated by emulating the effects of artificial supplementary lighting. Then a DCNN trained using only synthetic data recovers the missing detail caused by quantization.
Single Image Reflection Removal Using Deep Encoder-Decoder Network
Jan 31, 2018
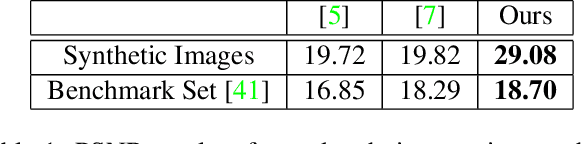


Image of a scene captured through a piece of transparent and reflective material, such as glass, is often spoiled by a superimposed layer of reflection image. While separating the reflection from a familiar object in an image is mentally not difficult for humans, it is a challenging, ill-posed problem in computer vision. In this paper, we propose a novel deep convolutional encoder-decoder method to remove the objectionable reflection by learning a map between image pairs with and without reflection. For training the neural network, we model the physical formation of reflections in images and synthesize a large number of photo-realistic reflection-tainted images from reflection-free images collected online. Extensive experimental results show that, although the neural network learns only from synthetic data, the proposed method is effective on real-world images, and it significantly outperforms the other tested state-of-the-art techniques.
Fast Screening Algorithm for Rotation and Scale Invariant Template Matching
Jul 19, 2017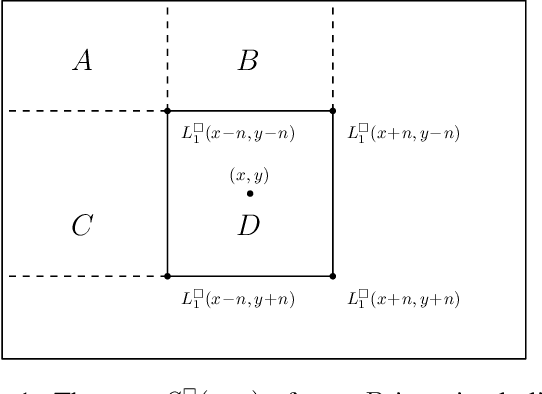
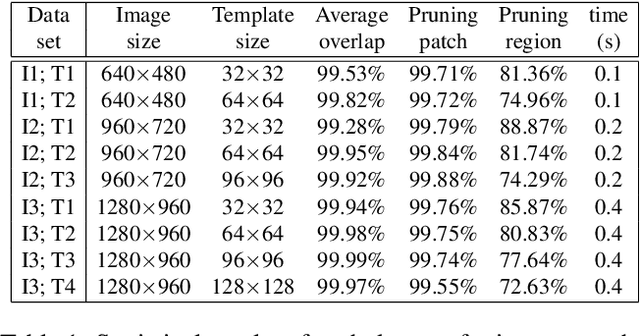
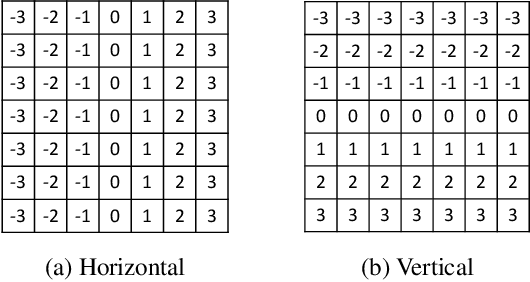
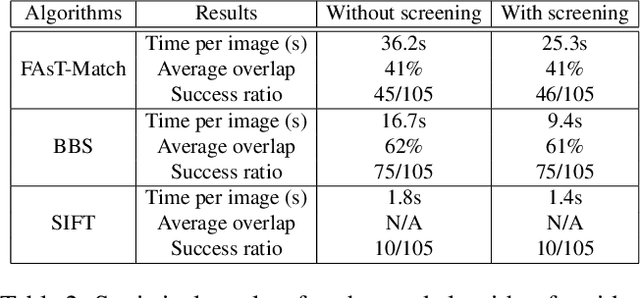
This paper presents a generic pre-processor for expediting conventional template matching techniques. Instead of locating the best matched patch in the reference image to a query template via exhaustive search, the proposed algorithm rules out regions with no possible matches with minimum computational efforts. While working on simple patch features, such as mean, variance and gradient, the fast pre-screening is highly discriminative. Its computational efficiency is gained by using a novel octagonal-star-shaped template and the inclusion-exclusion principle to extract and compare patch features. Moreover, it can handle arbitrary rotation and scaling of reference images effectively. Extensive experiments demonstrate that the proposed algorithm greatly reduces the search space while never missing the best match.
Quality Adaptive Low-Rank Based JPEG Decoding with Applications
Jan 06, 2016
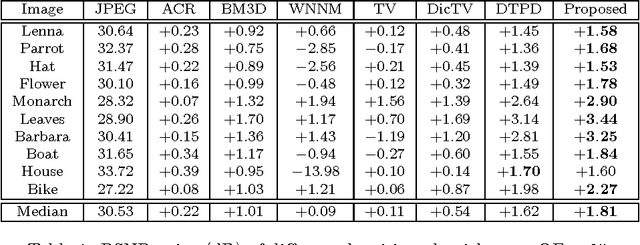

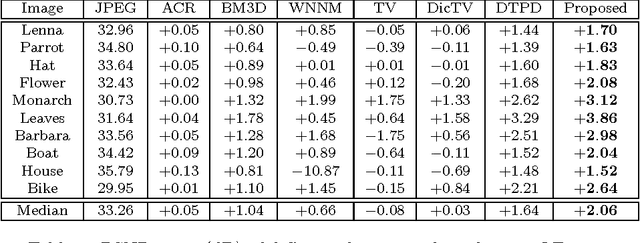
Small compression noises, despite being transparent to human eyes, can adversely affect the results of many image restoration processes, if left unaccounted for. Especially, compression noises are highly detrimental to inverse operators of high-boosting (sharpening) nature, such as deblurring and superresolution against a convolution kernel. By incorporating the non-linear DCT quantization mechanism into the formulation for image restoration, we propose a new sparsity-based convex programming approach for joint compression noise removal and image restoration. Experimental results demonstrate significant performance gains of the new approach over existing image restoration methods.