 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoDGS: Dynamic Gaussian Splatting from Causually-captured Monocular Videos
Jun 01, 2024



In this paper, we propose MoDGS, a new pipeline to render novel-view images in dynamic scenes using only casually captured monocular videos. Previous monocular dynamic NeRF or Gaussian Splatting methods strongly rely on the rapid movement of input cameras to construct multiview consistency but fail to reconstruct dynamic scenes on casually captured input videos whose cameras are static or move slowly. To address this challenging task, MoDGS adopts recent single-view depth estimation methods to guide the learning of the dynamic scene. Then, a novel 3D-aware initialization method is proposed to learn a reasonable deformation field and a new robust depth loss is proposed to guide the learning of dynamic scene geometry. Comprehensive experiments demonstrate that MoDGS is able to render high-quality novel view images of dynamic scenes from just a casually captured monocular video, which outperforms baseline methods by a significant margin.
Light Field Segmentation From Super-pixel Graph Representation
Dec 20, 2017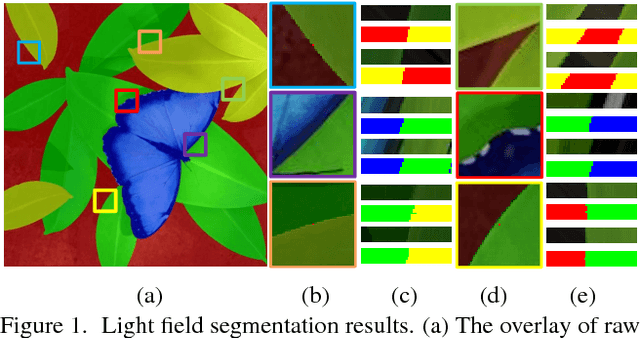

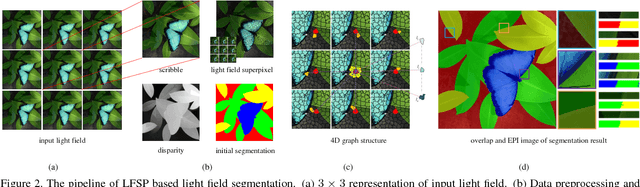
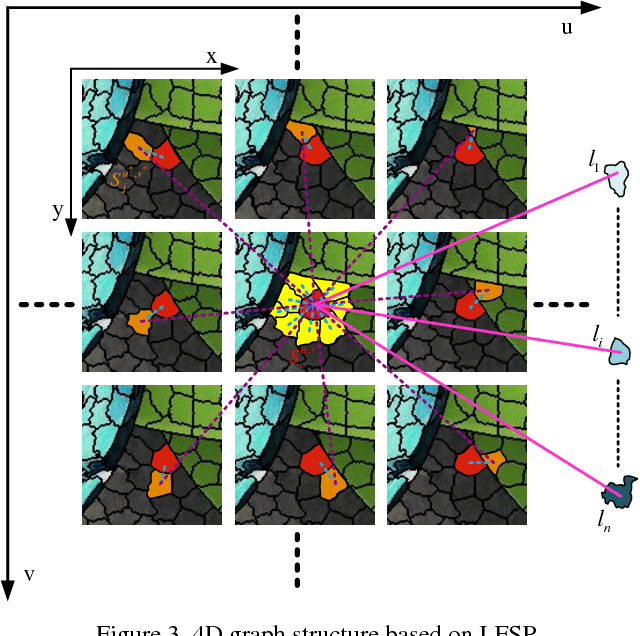
Efficient and accurate segmentation of light field is an important task in computer vision and graphics. The large volume of input data and the redundancy of light field make it an open challenge. In the paper, we propose a novel graph representation for interactive light field segmentation based on light field super-pixel (LFSP). The LFSP not only maintains light field redundancy, but also greatly reduces the graph size. These advantages make LFSP useful to improve segmentation efficiency. Based on LFSP graph structure, we present an efficient light field segmentation algorithm using graph-cuts. Experimental results on both synthetic and real dataset demonstrate that our method is superior to previous light field segmentation algorithms with respect to accuracy and efficiency.