 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShackled Dancing: A Bit-Locked Diffusion Algorithm for Lossless and Controllable Image Steganography
May 16, 2025Data steganography aims to conceal information within visual content, yet existing spatial- and frequency-domain approaches suffer from trade-offs between security, capacity, and perceptual quality. Recent advances in generative models, particularly diffusion models, offer new avenues for adaptive image synthesis, but integrating precise information embedding into the generative process remains challenging. We introduce Shackled Dancing Diffusion, or SD$^2$, a plug-and-play generative steganography method that combines bit-position locking with diffusion sampling injection to enable controllable information embedding within the generative trajectory. SD$^2$ leverages the expressive power of diffusion models to synthesize diverse carrier images while maintaining full message recovery with $100\%$ accuracy. Our method achieves a favorable balance between randomness and constraint, enhancing robustness against steganalysis without compromising image fidelity. Extensive experiments show that SD$^2$ substantially outperforms prior methods in security, embedding capacity, and stability. This algorithm offers new insights into controllable generation and opens promising directions for secure visual communication.
Multi-Ship Tracking by Robust Similarity metric
Oct 08, 2023Multi-ship tracking (MST) as a core technology has been proven to be applied to situational awareness at sea and the development of a navigational system for autonomous ships. Despite impressive tracking outcomes achieved by multi-object tracking (MOT) algorithms for pedestrian and vehicle datasets, these models and techniques exhibit poor performance when applied to ship datasets. Intersection of Union (IoU) is the most popular metric for computing similarity used in object tracking. The low frame rates and severe image shake caused by wave turbulence in ship datasets often result in minimal, or even zero, Intersection of Union (IoU) between the predicted and detected bounding boxes. This issue contributes to frequent identity switches of tracked objects, undermining the tracking performance. In this paper, we address the weaknesses of IoU by incorporating the smallest convex shapes that enclose both the predicted and detected bounding boxes. The calculation of the tracking version of IoU (TIoU) metric considers not only the size of the overlapping area between the detection bounding box and the prediction box, but also the similarity of their shapes. Through the integration of the TIoU into state-of-the-art object tracking frameworks, such as DeepSort and ByteTrack, we consistently achieve improvements in the tracking performance of these frameworks.
Towards Interpretable Image Synthesis by Learning Sparsely Connected AND-OR Networks
Sep 10, 2019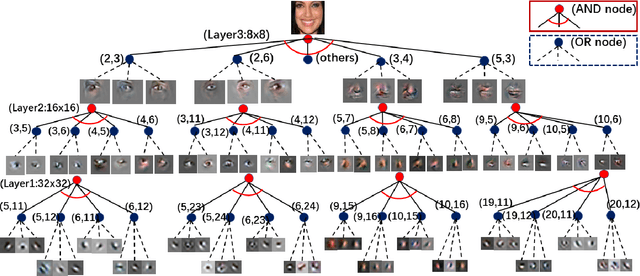

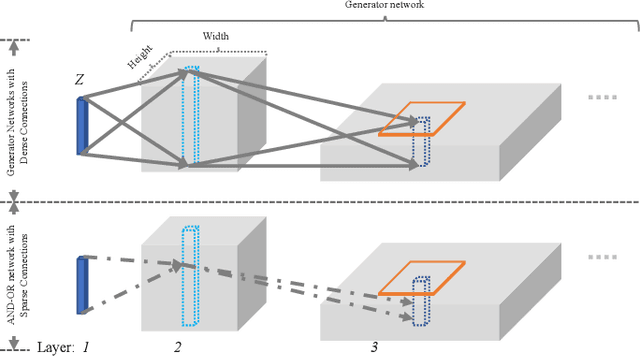

This paper proposes interpretable image synthesis by learning hierarchical AND-OR networks of sparsely connected semantically meaningful nodes. The proposed method is based on the compositionality and interpretability of scene-objects-parts-subparts-primitives hierarchy in image representation. A scene has different types (i.e., OR) each of which consists of a number of objects (i.e., AND). This can be recursively formulated across the scene-objects-parts-subparts hierarchy and is terminated at the primitive level (e.g., Gabor wavelets-like basis). To realize this interpretable AND-OR hierarchy in image synthesis, the proposed method consists of two components: (i) Each layer of the hierarchy is represented by an over-completed set of basis functions. The basis functions are instantiated using convolution to be translation covariant. Off-the-shelf convolutional neural architectures are then exploited to implement the hierarchy. (ii) Sparsity-inducing constraints are introduced in end-to-end training, which facilitate a sparsely connected AND-OR network to emerge from initially densely connected convolutional neural networks. A straightforward sparsity-inducing constraint is utilized, that is to only allow the top-$k$ basis functions to be active at each layer (where $k$ is a hyperparameter). The learned basis functions are also capable of image reconstruction to explain away input images. In experiments, the proposed method is tested on five benchmark datasets. The results show that meaningful and interpretable hierarchical representations are learned with better qualities of image synthesis and reconstruction obtained than state-of-the-art baselines.
Deformable Generator Network: Unsupervised Disentanglement of Appearance and Geometry
Jun 16, 2018



We propose a deformable generator model to disentangle the appearance and geometric information from images into two independent latent vectors. The appearance generator produces the appearance information, including color, illumination, identity or category, of an image. The geometric generator produces displacement of the coordinates of each pixel and performs geometric warping, such as stretching and rotation, on the appearance generator to obtain the final synthesized image. The proposed model can learn both representations from image data in an unsupervised manner. The learned geometric generator can be conveniently transferred to the other image datasets to facilitate downstream AI tasks.