 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition: A Three-Layer Probabilistic Assume-Guarantee Architecture Is Structurally Required for Safe LLM Agent Deployment
May 18, 2026This position paper argues that enforcing LLM agent safety within a single abstraction layer is not merely suboptimal but categorically insufficient for deployed LLM agents -- a structural consequence of how agent execution works, not a contingent limitation of current systems. The three dimensions that jointly constitute safe operation -- semantic intent and policy compliance, environmental validity, and dynamical feasibility -- each depend on a strictly distinct set of information that becomes available at different stages of execution. No single guardrail can certify all three. We argue that the community must respond with a contract-based architecture in which each safety dimension is enforced by an independently certified layer whose probabilistic guarantee satisfies the next layer's assumption. We sketch such an architecture and derive the compositional system-level safety bounds it admits via the chain rule of probability. Three open problems stand between this and a deployable standard: bound estimation from non-i.i.d.\ traces, graceful degradation of contracts under deployment drift, and extension to multi-agent settings -- the most important unfinished business in LLM agent runtime assurance.
InfAnFace: Bridging the infant-adult domain gap in facial landmark estimation in the wild
Oct 17, 2021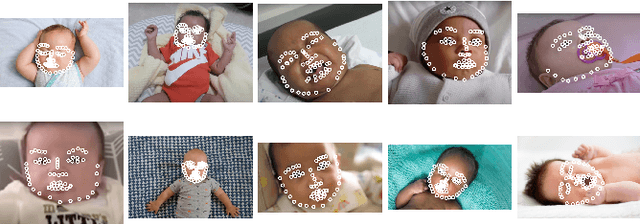
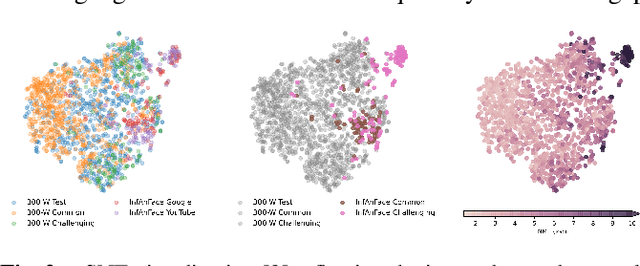
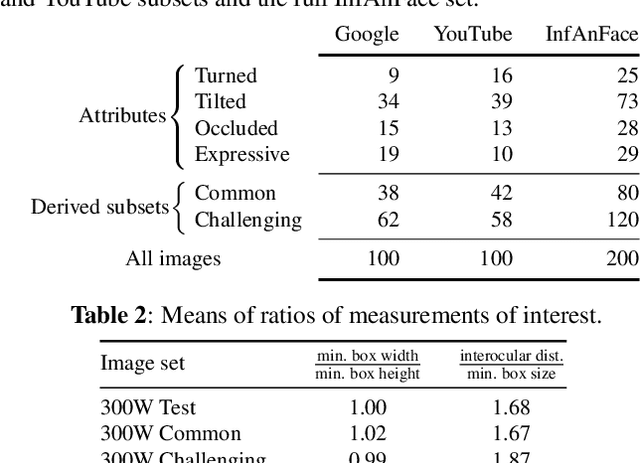
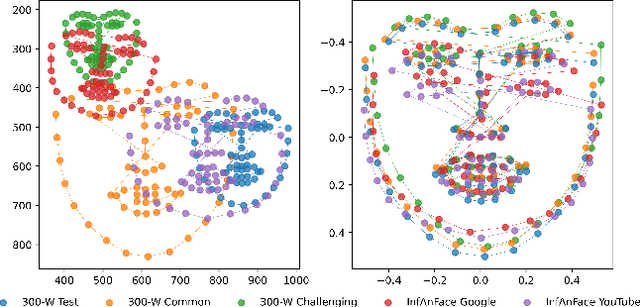
There is promising potential in the application of algorithmic facial landmark estimation to the early prediction, in infants, of pediatric developmental disorders and other conditions. However, the performance of these deep learning algorithms is severely hampered by the scarcity of infant data. To spur the development of facial landmarking systems for infants, we introduce InfAnFace, a diverse, richly-annotated dataset of infant faces. We use InfAnFace to benchmark the performance of existing facial landmark estimation algorithms that are trained on adult faces and demonstrate there is a significant domain gap between the representations learned by these algorithms when applied on infant vs. adult faces. Finally, we put forward the next potential steps to bridge that gap.
Adversary agent reinforcement learning for pursuit-evasion
Aug 25, 2021
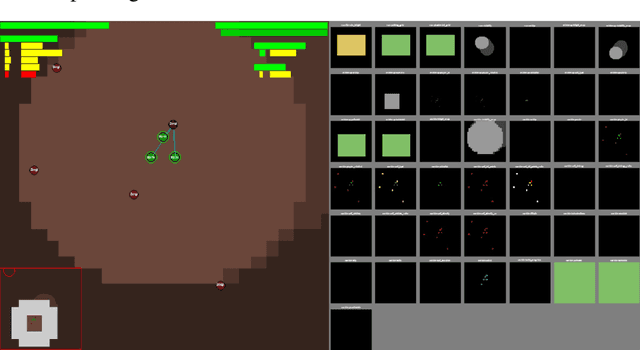

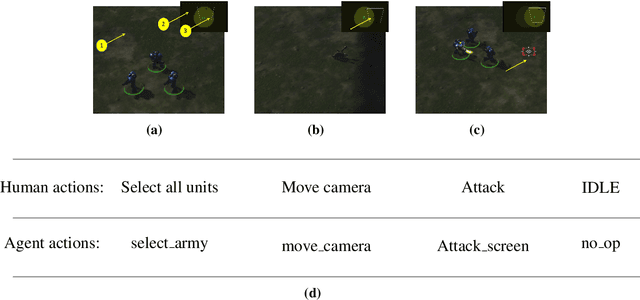
A reinforcement learning environment with adversary agents is proposed in this work for pursuit-evasion game in the presence of fog of war, which is of both scientific significance and practical importance in aerospace applications. One of the most popular learning environments, StarCraft, is adopted here and the associated mini-games are analyzed to identify the current limitation for training adversary agents. The key contribution includes the analysis of the potential performance of an agent by incorporating control and differential game theory into the specific reinforcement learning environment, and the development of an adversary agents challenge (SAAC) environment by extending the current StarCraft mini-games. The subsequent study showcases the use of this learning environment and the effectiveness of an adversary agent for evasion units. Overall, the proposed SAAC environment should benefit pursuit-evasion studies with rapidly-emerging reinforcement learning technologies. Last but not least, the corresponding tutorial code can be found at GitHub.
A survey of joint intent detection and slot-filling models in natural language understanding
Feb 22, 2021
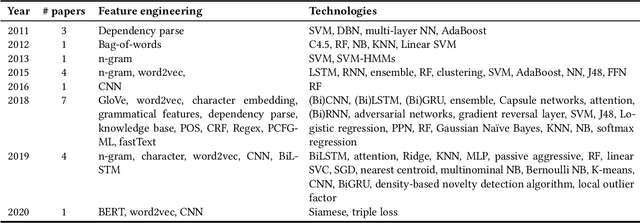
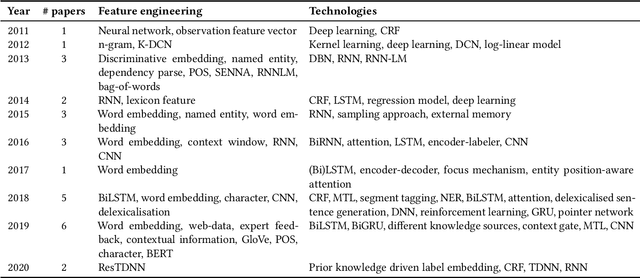
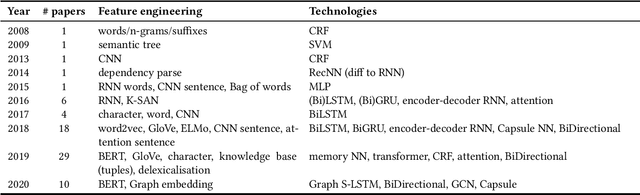
Intent classification and slot filling are two critical tasks for natural language understanding. Traditionally the two tasks have been deemed to proceed independently. However, more recently, joint models for intent classification and slot filling have achieved state-of-the-art performance, and have proved that there exists a strong relationship between the two tasks. This article is a compilation of past work in natural language understanding, especially joint intent classification and slot filling. We observe three milestones in this research so far: Intent detection to identify the speaker's intention, slot filling to label each word token in the speech/text, and finally, joint intent classification and slot filling tasks. In this article, we describe trends, approaches, issues, data sets, evaluation metrics in intent classification and slot filling. We also discuss representative performance values, describe shared tasks, and provide pointers to future work, as given in prior works. To interpret the state-of-the-art trends, we provide multiple tables that describe and summarise past research along different dimensions, including the types of features, base approaches, and dataset domain used.
Discriminative Feature Representation with Spatio-temporal Cues for Vehicle Re-identification
Nov 13, 2020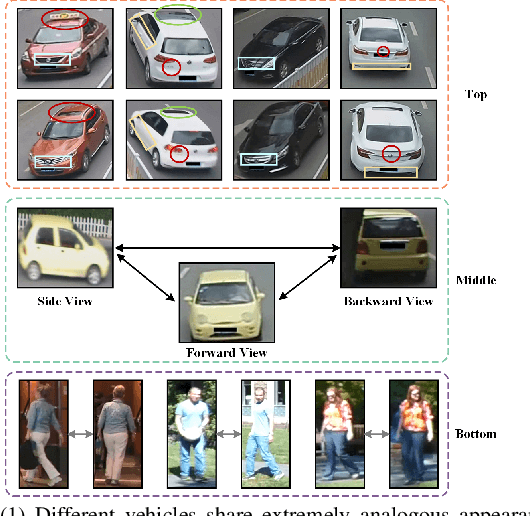
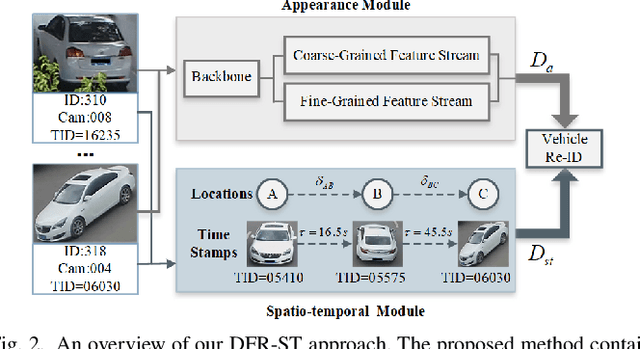
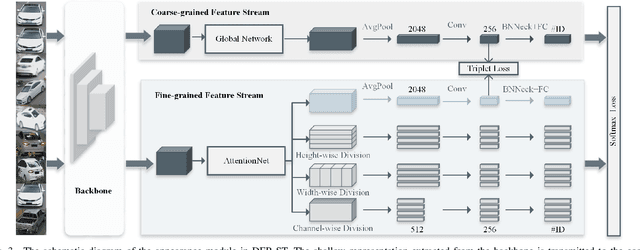
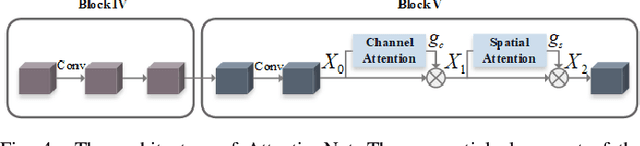
Vehicle re-identification (re-ID) aims to discover and match the target vehicles from a gallery image set taken by different cameras on a wide range of road networks. It is crucial for lots of applications such as security surveillance and traffic management. The remarkably similar appearances of distinct vehicles and the significant changes of viewpoints and illumination conditions take grand challenges to vehicle re-ID. Conventional solutions focus on designing global visual appearances without sufficient consideration of vehicles' spatiotamporal relationships in different images. In this paper, we propose a novel discriminative feature representation with spatiotemporal clues (DFR-ST) for vehicle re-ID. It is capable of building robust features in the embedding space by involving appearance and spatio-temporal information. Based on this multi-modal information, the proposed DFR-ST constructs an appearance model for a multi-grained visual representation by a two-stream architecture and a spatio-temporal metric to provide complementary information. Experimental results on two public datasets demonstrate DFR-ST outperforms the state-of-the-art methods, which validate the effectiveness of the proposed method.
Physics-informed Gaussian Process for Online Optimization of Particle Accelerators
Sep 08, 2020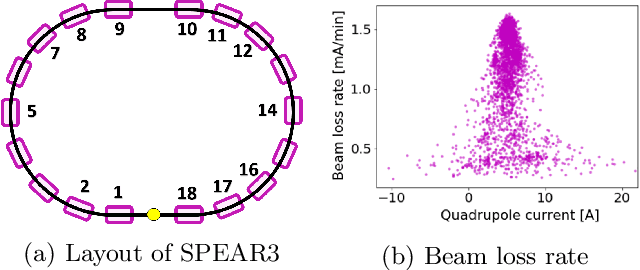
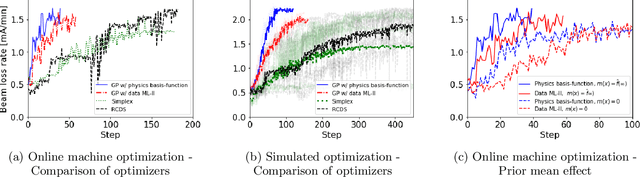
High-dimensional optimization is a critical challenge for operating large-scale scientific facilities. We apply a physics-informed Gaussian process (GP) optimizer to tune a complex system by conducting efficient global search. Typical GP models learn from past observations to make predictions, but this reduces their applicability to new systems where archive data is not available. Instead, here we use a fast approximate model from physics simulations to design the GP model. The GP is then employed to make inferences from sequential online observations in order to optimize the system. Simulation and experimental studies were carried out to demonstrate the method for online control of a storage ring. We show that the physics-informed GP outperforms current routinely used online optimizers in terms of convergence speed, and robustness on this task. The ability to inform the machine-learning model with physics may have wide applications in science.
Online tuning and light source control using a physics-informed Gaussian process Adi
Nov 04, 2019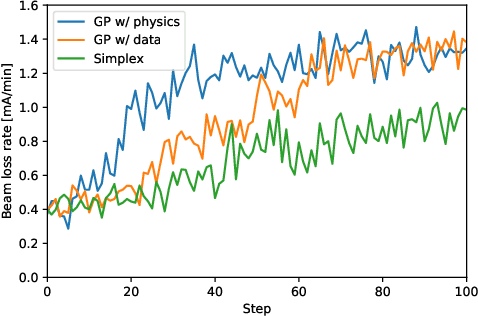
Operating large-scale scientific facilities often requires fast tuning and robust control in a high dimensional space. In this paper we introduce a new physics-informed optimization algorithm based on Gaussian process regression. Our method takes advantage of the existing domain knowledge in the form of realizations of a physics model of the observed system. We have applied a physics-informed Gaussian Process method experimentally at the SPEAR3 storage ring to demonstrate online accelerator optimization. This method outperforms Gaussian Process trained on data as well as the standard approach routinely used for operation, in terms of convergence speed and optimal point. The proposed method could be applicable to automatic tuning and control of other complex systems, without a prerequisite for any observed data.
The Microsoft 2017 Conversational Speech Recognition System
Aug 24, 2017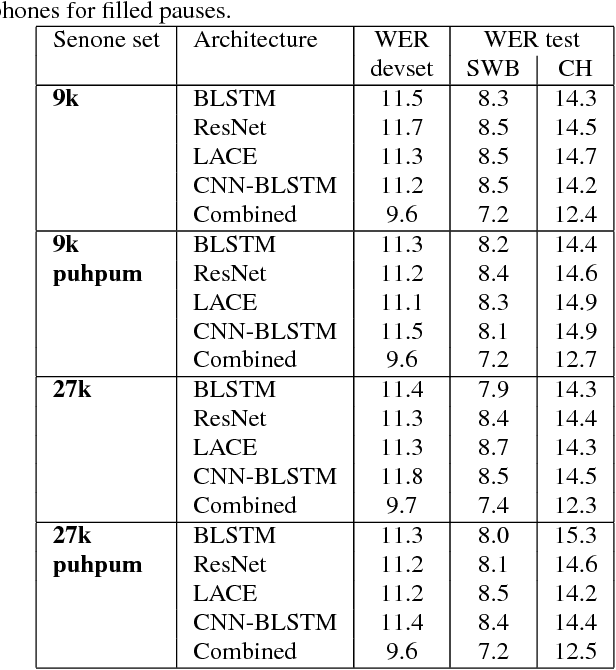
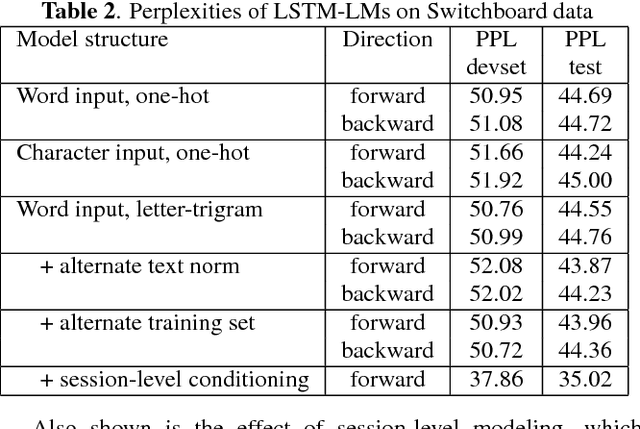
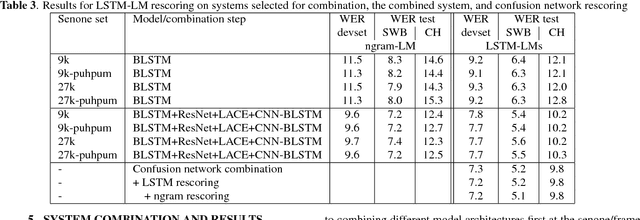
We describe the 2017 version of Microsoft's conversational speech recognition system, in which we update our 2016 system with recent developments in neural-network-based acoustic and language modeling to further advance the state of the art on the Switchboard speech recognition task. The system adds a CNN-BLSTM acoustic model to the set of model architectures we combined previously, and includes character-based and dialog session aware LSTM language models in rescoring. For system combination we adopt a two-stage approach, whereby subsets of acoustic models are first combined at the senone/frame level, followed by a word-level voting via confusion networks. We also added a confusion network rescoring step after system combination. The resulting system yields a 5.1\% word error rate on the 2000 Switchboard evaluation set.
Achieving Human Parity in Conversational Speech Recognition
Feb 17, 2017
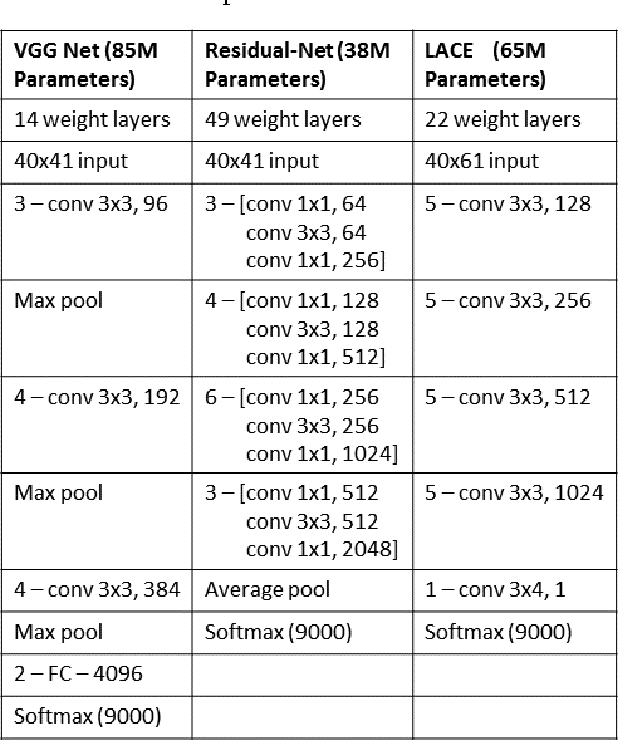
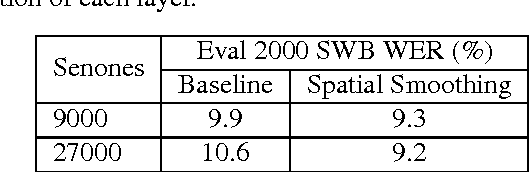
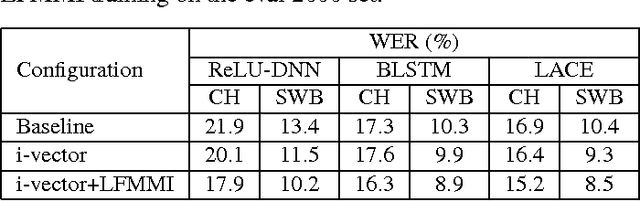
Conversational speech recognition has served as a flagship speech recognition task since the release of the Switchboard corpus in the 1990s. In this paper, we measure the human error rate on the widely used NIST 2000 test set, and find that our latest automated system has reached human parity. The error rate of professional transcribers is 5.9% for the Switchboard portion of the data, in which newly acquainted pairs of people discuss an assigned topic, and 11.3% for the CallHome portion where friends and family members have open-ended conversations. In both cases, our automated system establishes a new state of the art, and edges past the human benchmark, achieving error rates of 5.8% and 11.0%, respectively. The key to our system's performance is the use of various convolutional and LSTM acoustic model architectures, combined with a novel spatial smoothing method and lattice-free MMI acoustic training, multiple recurrent neural network language modeling approaches, and a systematic use of system combination.
The Microsoft 2016 Conversational Speech Recognition System
Jan 25, 2017
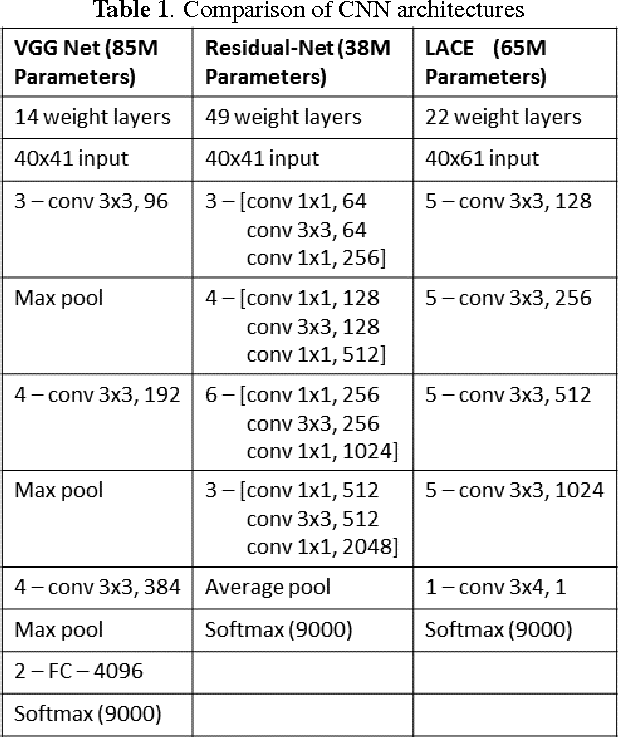
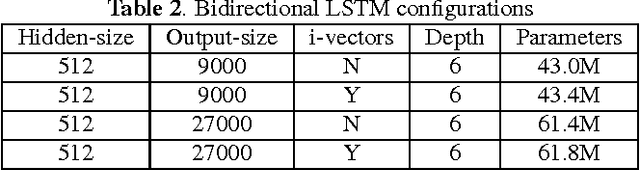
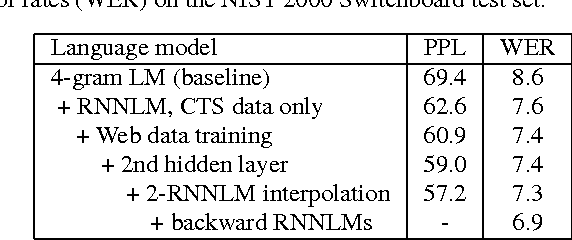
We describe Microsoft's conversational speech recognition system, in which we combine recent developments in neural-network-based acoustic and language modeling to advance the state of the art on the Switchboard recognition task. Inspired by machine learning ensemble techniques, the system uses a range of convolutional and recurrent neural networks. I-vector modeling and lattice-free MMI training provide significant gains for all acoustic model architectures. Language model rescoring with multiple forward and backward running RNNLMs, and word posterior-based system combination provide a 20% boost. The best single system uses a ResNet architecture acoustic model with RNNLM rescoring, and achieves a word error rate of 6.9% on the NIST 2000 Switchboard task. The combined system has an error rate of 6.2%, representing an improvement over previously reported results on this benchmark task.