 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Microsoft 2017 Conversational Speech Recognition System
Aug 24, 2017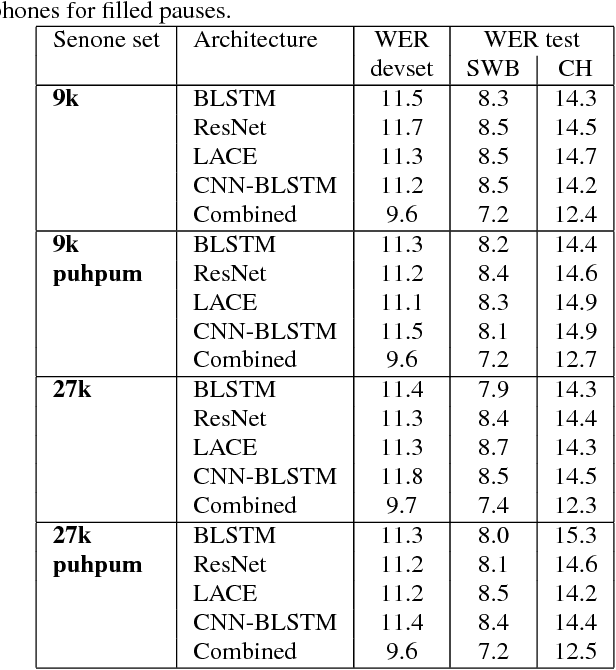
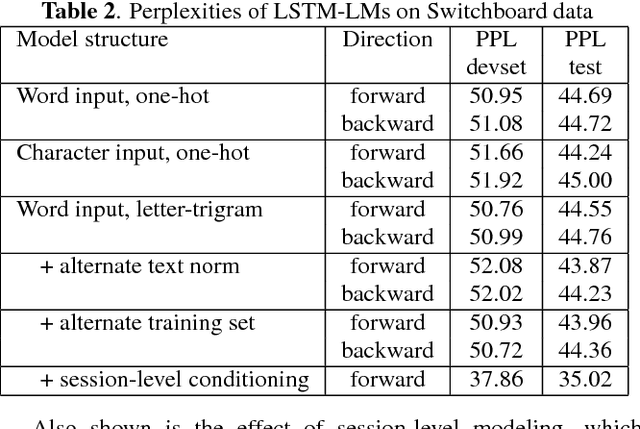
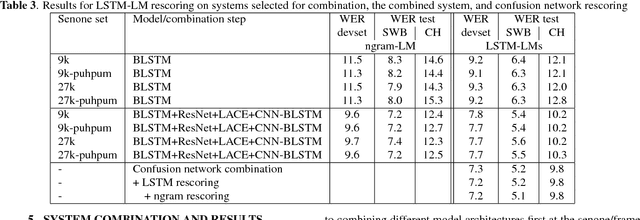
We describe the 2017 version of Microsoft's conversational speech recognition system, in which we update our 2016 system with recent developments in neural-network-based acoustic and language modeling to further advance the state of the art on the Switchboard speech recognition task. The system adds a CNN-BLSTM acoustic model to the set of model architectures we combined previously, and includes character-based and dialog session aware LSTM language models in rescoring. For system combination we adopt a two-stage approach, whereby subsets of acoustic models are first combined at the senone/frame level, followed by a word-level voting via confusion networks. We also added a confusion network rescoring step after system combination. The resulting system yields a 5.1\% word error rate on the 2000 Switchboard evaluation set.
Achieving Human Parity in Conversational Speech Recognition
Feb 17, 2017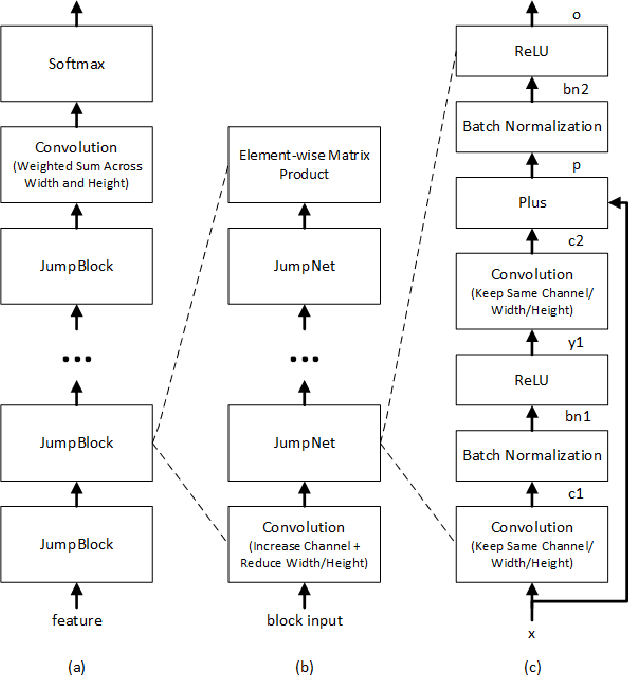
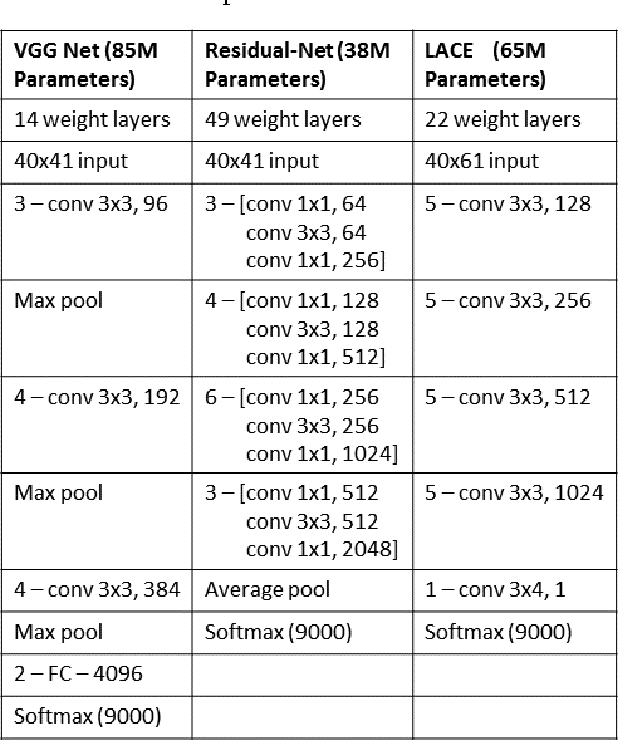
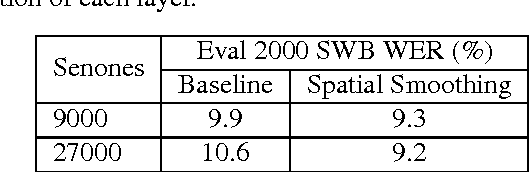
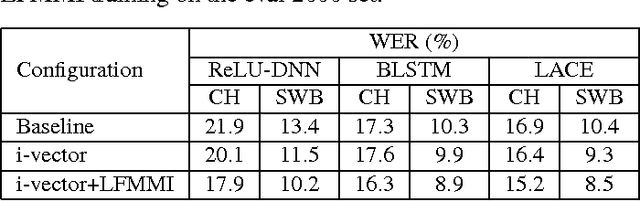
Conversational speech recognition has served as a flagship speech recognition task since the release of the Switchboard corpus in the 1990s. In this paper, we measure the human error rate on the widely used NIST 2000 test set, and find that our latest automated system has reached human parity. The error rate of professional transcribers is 5.9% for the Switchboard portion of the data, in which newly acquainted pairs of people discuss an assigned topic, and 11.3% for the CallHome portion where friends and family members have open-ended conversations. In both cases, our automated system establishes a new state of the art, and edges past the human benchmark, achieving error rates of 5.8% and 11.0%, respectively. The key to our system's performance is the use of various convolutional and LSTM acoustic model architectures, combined with a novel spatial smoothing method and lattice-free MMI acoustic training, multiple recurrent neural network language modeling approaches, and a systematic use of system combination.
Advances in All-Neural Speech Recognition
Jan 25, 2017
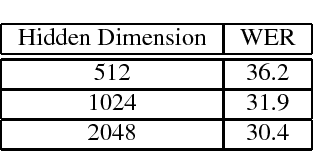


This paper advances the design of CTC-based all-neural (or end-to-end) speech recognizers. We propose a novel symbol inventory, and a novel iterated-CTC method in which a second system is used to transform a noisy initial output into a cleaner version. We present a number of stabilization and initialization methods we have found useful in training these networks. We evaluate our system on the commonly used NIST 2000 conversational telephony test set, and significantly exceed the previously published performance of similar systems, both with and without the use of an external language model and decoding technology.
The Microsoft 2016 Conversational Speech Recognition System
Jan 25, 2017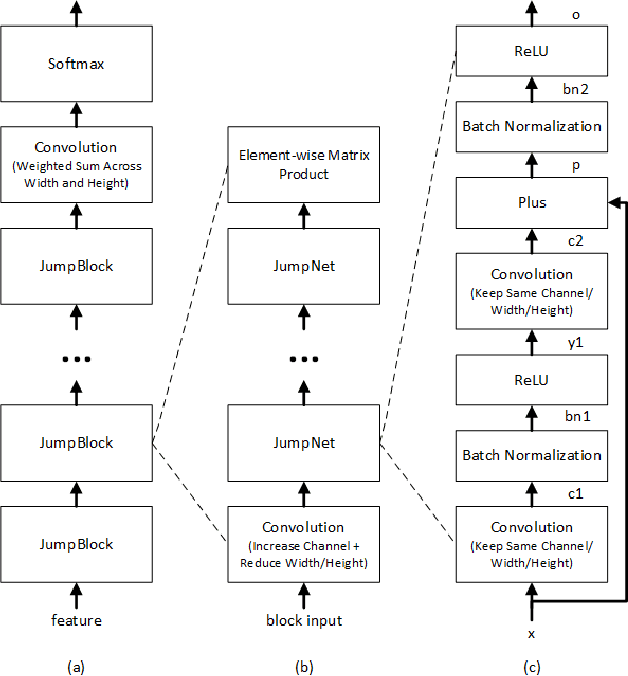
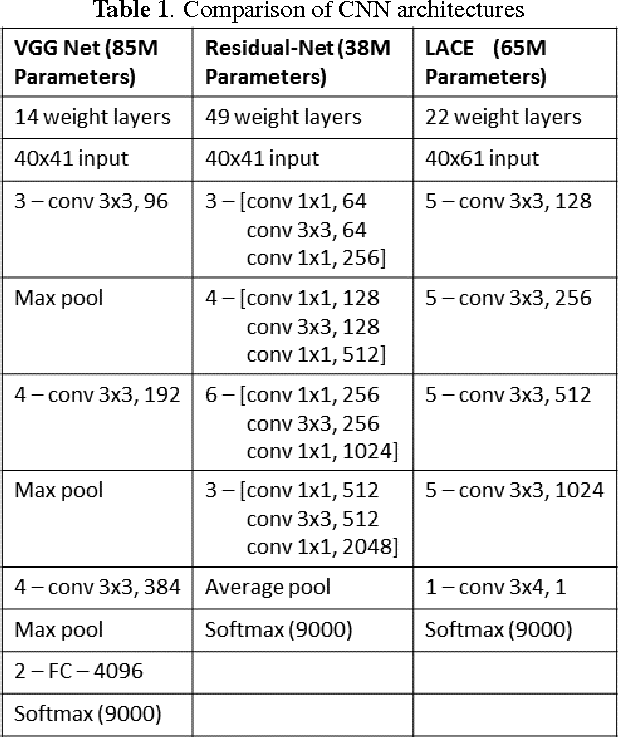
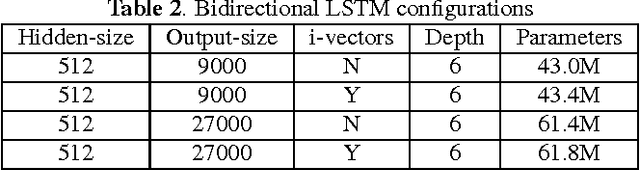
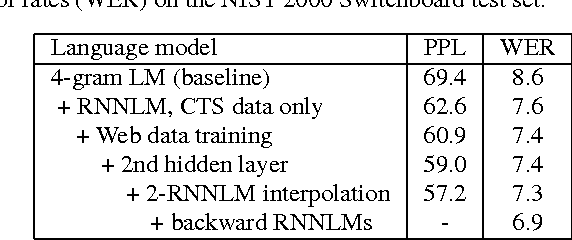
We describe Microsoft's conversational speech recognition system, in which we combine recent developments in neural-network-based acoustic and language modeling to advance the state of the art on the Switchboard recognition task. Inspired by machine learning ensemble techniques, the system uses a range of convolutional and recurrent neural networks. I-vector modeling and lattice-free MMI training provide significant gains for all acoustic model architectures. Language model rescoring with multiple forward and backward running RNNLMs, and word posterior-based system combination provide a 20% boost. The best single system uses a ResNet architecture acoustic model with RNNLM rescoring, and achieves a word error rate of 6.9% on the NIST 2000 Switchboard task. The combined system has an error rate of 6.2%, representing an improvement over previously reported results on this benchmark task.
Integrating Prosodic and Lexical Cues for Automatic Topic Segmentation
May 31, 2001We present a probabilistic model that uses both prosodic and lexical cues for the automatic segmentation of speech into topically coherent units. We propose two methods for combining lexical and prosodic information using hidden Markov models and decision trees. Lexical information is obtained from a speech recognizer, and prosodic features are extracted automatically from speech waveforms. We evaluate our approach on the Broadcast News corpus, using the DARPA-TDT evaluation metrics. Results show that the prosodic model alone is competitive with word-based segmentation methods. Furthermore, we achieve a significant reduction in error by combining the prosodic and word-based knowledge sources.
* 27 pages, 8 figures
Dialogue Act Modeling for Automatic Tagging and Recognition of Conversational Speech
Oct 26, 2000We describe a statistical approach for modeling dialogue acts in conversational speech, i.e., speech-act-like units such as Statement, Question, Backchannel, Agreement, Disagreement, and Apology. Our model detects and predicts dialogue acts based on lexical, collocational, and prosodic cues, as well as on the discourse coherence of the dialogue act sequence. The dialogue model is based on treating the discourse structure of a conversation as a hidden Markov model and the individual dialogue acts as observations emanating from the model states. Constraints on the likely sequence of dialogue acts are modeled via a dialogue act n-gram. The statistical dialogue grammar is combined with word n-grams, decision trees, and neural networks modeling the idiosyncratic lexical and prosodic manifestations of each dialogue act. We develop a probabilistic integration of speech recognition with dialogue modeling, to improve both speech recognition and dialogue act classification accuracy. Models are trained and evaluated using a large hand-labeled database of 1,155 conversations from the Switchboard corpus of spontaneous human-to-human telephone speech. We achieved good dialogue act labeling accuracy (65% based on errorful, automatically recognized words and prosody, and 71% based on word transcripts, compared to a chance baseline accuracy of 35% and human accuracy of 84%) and a small reduction in word recognition error.
* 35 pages, 5 figures. Changes in copy editing (note title spelling changed)
Finding consensus in speech recognition: word error minimization and other applications of confusion networks
Oct 07, 2000
We describe a new framework for distilling information from word lattices to improve the accuracy of speech recognition and obtain a more perspicuous representation of a set of alternative hypotheses. In the standard MAP decoding approach the recognizer outputs the string of words corresponding to the path with the highest posterior probability given the acoustics and a language model. However, even given optimal models, the MAP decoder does not necessarily minimize the commonly used performance metric, word error rate (WER). We describe a method for explicitly minimizing WER by extracting word hypotheses with the highest posterior probabilities from word lattices. We change the standard problem formulation by replacing global search over a large set of sentence hypotheses with local search over a small set of word candidates. In addition to improving the accuracy of the recognizer, our method produces a new representation of the set of candidate hypotheses that specifies the sequence of word-level confusions in a compact lattice format. We study the properties of confusion networks and examine their use for other tasks, such as lattice compression, word spotting, confidence annotation, and reevaluation of recognition hypotheses using higher-level knowledge sources.
* 35 pages, 8 figures
Prosody-Based Automatic Segmentation of Speech into Sentences and Topics
Jun 27, 2000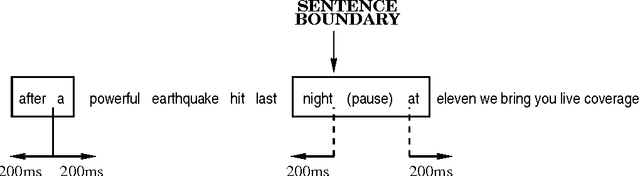
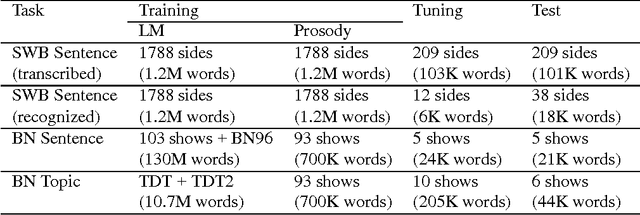
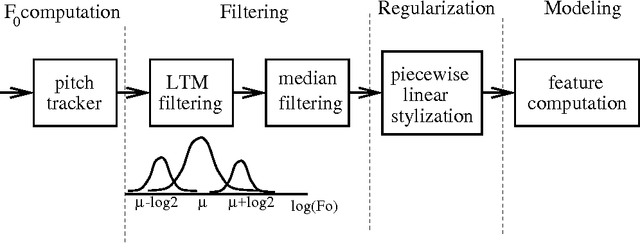
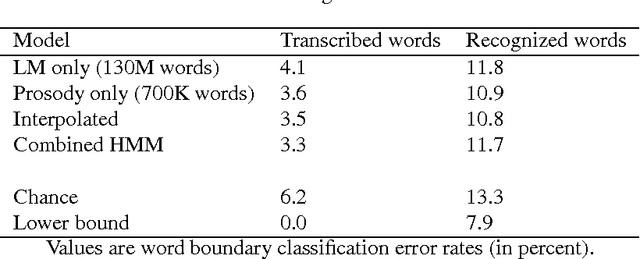
A crucial step in processing speech audio data for information extraction, topic detection, or browsing/playback is to segment the input into sentence and topic units. Speech segmentation is challenging, since the cues typically present for segmenting text (headers, paragraphs, punctuation) are absent in spoken language. We investigate the use of prosody (information gleaned from the timing and melody of speech) for these tasks. Using decision tree and hidden Markov modeling techniques, we combine prosodic cues with word-based approaches, and evaluate performance on two speech corpora, Broadcast News and Switchboard. Results show that the prosodic model alone performs on par with, or better than, word-based statistical language models -- for both true and automatically recognized words in news speech. The prosodic model achieves comparable performance with significantly less training data, and requires no hand-labeling of prosodic events. Across tasks and corpora, we obtain a significant improvement over word-only models using a probabilistic combination of prosodic and lexical information. Inspection reveals that the prosodic models capture language-independent boundary indicators described in the literature. Finally, cue usage is task and corpus dependent. For example, pause and pitch features are highly informative for segmenting news speech, whereas pause, duration and word-based cues dominate for natural conversation.
* 30 pages, 9 figures. To appear in Speech Communication 32(1-2), Special Issue on Accessing Information in Spoken Audio, September 2000
Entropy-based Pruning of Backoff Language Models
Jun 11, 2000



A criterion for pruning parameters from N-gram backoff language models is developed, based on the relative entropy between the original and the pruned model. It is shown that the relative entropy resulting from pruning a single N-gram can be computed exactly and efficiently for backoff models. The relative entropy measure can be expressed as a relative change in training set perplexity. This leads to a simple pruning criterion whereby all N-grams that change perplexity by less than a threshold are removed from the model. Experiments show that a production-quality Hub4 LM can be reduced to 26% its original size without increasing recognition error. We also compare the approach to a heuristic pruning criterion by Seymore and Rosenfeld (1996), and show that their approach can be interpreted as an approximation to the relative entropy criterion. Experimentally, both approaches select similar sets of N-grams (about 85% overlap), with the exact relative entropy criterion giving marginally better performance.
* 5 pages. Typos in published version fixed
Can Prosody Aid the Automatic Classification of Dialog Acts in Conversational Speech?
Jun 11, 2000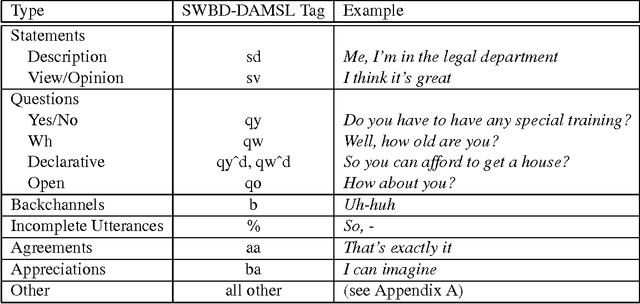
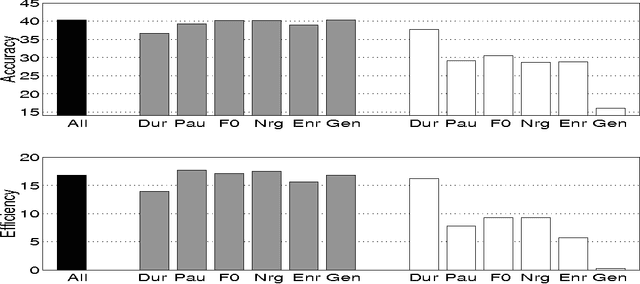

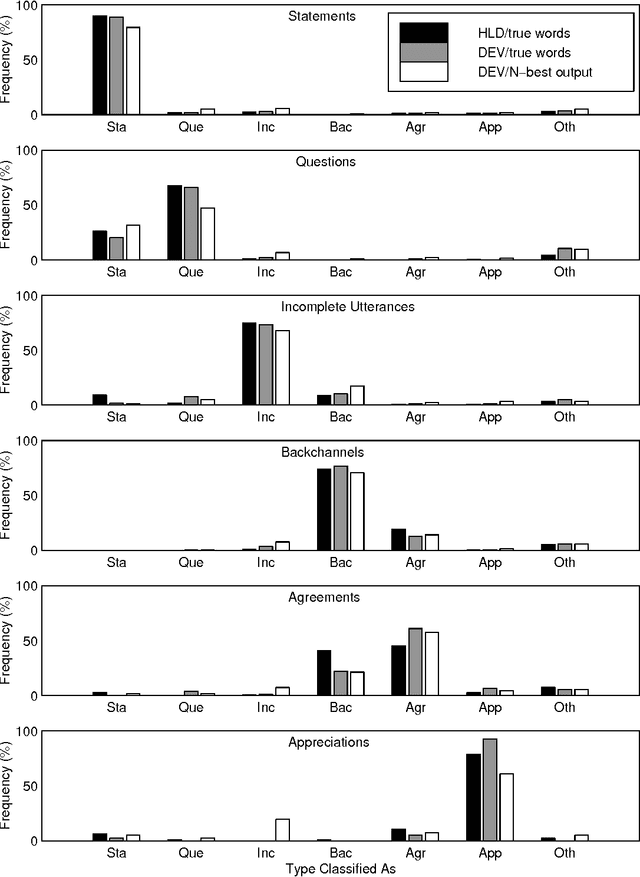
Identifying whether an utterance is a statement, question, greeting, and so forth is integral to effective automatic understanding of natural dialog. Little is known, however, about how such dialog acts (DAs) can be automatically classified in truly natural conversation. This study asks whether current approaches, which use mainly word information, could be improved by adding prosodic information. The study is based on more than 1000 conversations from the Switchboard corpus. DAs were hand-annotated, and prosodic features (duration, pause, F0, energy, and speaking rate) were automatically extracted for each DA. In training, decision trees based on these features were inferred; trees were then applied to unseen test data to evaluate performance. Performance was evaluated for prosody models alone, and after combining the prosody models with word information -- either from true words or from the output of an automatic speech recognizer. For an overall classification task, as well as three subtasks, prosody made significant contributions to classification. Feature-specific analyses further revealed that although canonical features (such as F0 for questions) were important, less obvious features could compensate if canonical features were removed. Finally, in each task, integrating the prosodic model with a DA-specific statistical language model improved performance over that of the language model alone, especially for the case of recognized words. Results suggest that DAs are redundantly marked in natural conversation, and that a variety of automatically extractable prosodic features could aid dialog processing in speech applications.
* 55 pages, 10 figures