 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Prosodic and Lexical Cues for Automatic Topic Segmentation
May 31, 2001We present a probabilistic model that uses both prosodic and lexical cues for the automatic segmentation of speech into topically coherent units. We propose two methods for combining lexical and prosodic information using hidden Markov models and decision trees. Lexical information is obtained from a speech recognizer, and prosodic features are extracted automatically from speech waveforms. We evaluate our approach on the Broadcast News corpus, using the DARPA-TDT evaluation metrics. Results show that the prosodic model alone is competitive with word-based segmentation methods. Furthermore, we achieve a significant reduction in error by combining the prosodic and word-based knowledge sources.
* 27 pages, 8 figures
Prosody-Based Automatic Segmentation of Speech into Sentences and Topics
Jun 27, 2000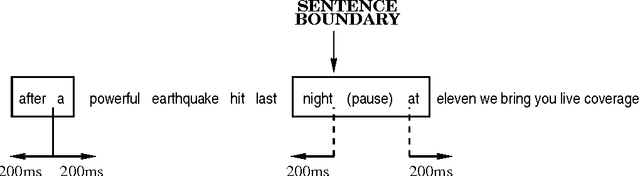
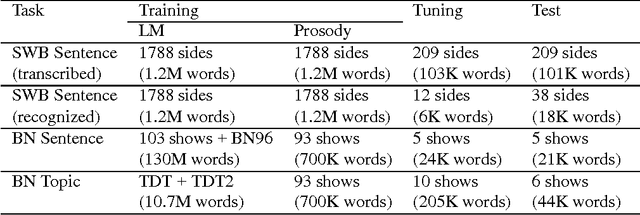
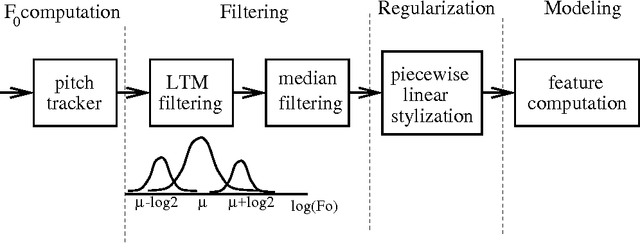
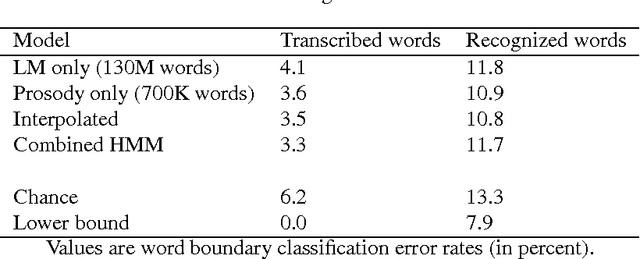
A crucial step in processing speech audio data for information extraction, topic detection, or browsing/playback is to segment the input into sentence and topic units. Speech segmentation is challenging, since the cues typically present for segmenting text (headers, paragraphs, punctuation) are absent in spoken language. We investigate the use of prosody (information gleaned from the timing and melody of speech) for these tasks. Using decision tree and hidden Markov modeling techniques, we combine prosodic cues with word-based approaches, and evaluate performance on two speech corpora, Broadcast News and Switchboard. Results show that the prosodic model alone performs on par with, or better than, word-based statistical language models -- for both true and automatically recognized words in news speech. The prosodic model achieves comparable performance with significantly less training data, and requires no hand-labeling of prosodic events. Across tasks and corpora, we obtain a significant improvement over word-only models using a probabilistic combination of prosodic and lexical information. Inspection reveals that the prosodic models capture language-independent boundary indicators described in the literature. Finally, cue usage is task and corpus dependent. For example, pause and pitch features are highly informative for segmenting news speech, whereas pause, duration and word-based cues dominate for natural conversation.
* 30 pages, 9 figures. To appear in Speech Communication 32(1-2), Special Issue on Accessing Information in Spoken Audio, September 2000