 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Speech and Natural Language Processing Models for Depression Screening
Dec 26, 2024Depression is a global health concern with a critical need for increased patient screening. Speech technology offers advantages for remote screening but must perform robustly across patients. We have described two deep learning models developed for this purpose. One model is based on acoustics; the other is based on natural language processing. Both models employ transfer learning. Data from a depression-labeled corpus in which 11,000 unique users interacted with a human-machine application using conversational speech is used. Results on binary depression classification have shown that both models perform at or above AUC=0.80 on unseen data with no speaker overlap. Performance is further analyzed as a function of test subset characteristics, finding that the models are generally robust over speaker and session variables. We conclude that models based on these approaches offer promise for generalized automated depression screening.
Integrating Prosodic and Lexical Cues for Automatic Topic Segmentation
May 31, 2001We present a probabilistic model that uses both prosodic and lexical cues for the automatic segmentation of speech into topically coherent units. We propose two methods for combining lexical and prosodic information using hidden Markov models and decision trees. Lexical information is obtained from a speech recognizer, and prosodic features are extracted automatically from speech waveforms. We evaluate our approach on the Broadcast News corpus, using the DARPA-TDT evaluation metrics. Results show that the prosodic model alone is competitive with word-based segmentation methods. Furthermore, we achieve a significant reduction in error by combining the prosodic and word-based knowledge sources.
* 27 pages, 8 figures
Dialogue Act Modeling for Automatic Tagging and Recognition of Conversational Speech
Oct 26, 2000We describe a statistical approach for modeling dialogue acts in conversational speech, i.e., speech-act-like units such as Statement, Question, Backchannel, Agreement, Disagreement, and Apology. Our model detects and predicts dialogue acts based on lexical, collocational, and prosodic cues, as well as on the discourse coherence of the dialogue act sequence. The dialogue model is based on treating the discourse structure of a conversation as a hidden Markov model and the individual dialogue acts as observations emanating from the model states. Constraints on the likely sequence of dialogue acts are modeled via a dialogue act n-gram. The statistical dialogue grammar is combined with word n-grams, decision trees, and neural networks modeling the idiosyncratic lexical and prosodic manifestations of each dialogue act. We develop a probabilistic integration of speech recognition with dialogue modeling, to improve both speech recognition and dialogue act classification accuracy. Models are trained and evaluated using a large hand-labeled database of 1,155 conversations from the Switchboard corpus of spontaneous human-to-human telephone speech. We achieved good dialogue act labeling accuracy (65% based on errorful, automatically recognized words and prosody, and 71% based on word transcripts, compared to a chance baseline accuracy of 35% and human accuracy of 84%) and a small reduction in word recognition error.
* 35 pages, 5 figures. Changes in copy editing (note title spelling changed)
Prosody-Based Automatic Segmentation of Speech into Sentences and Topics
Jun 27, 2000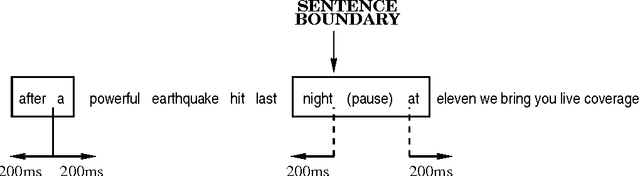
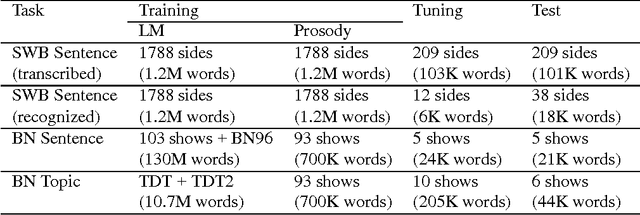
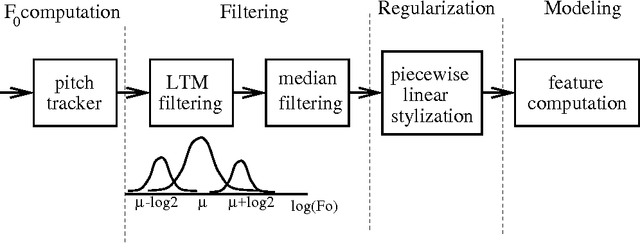
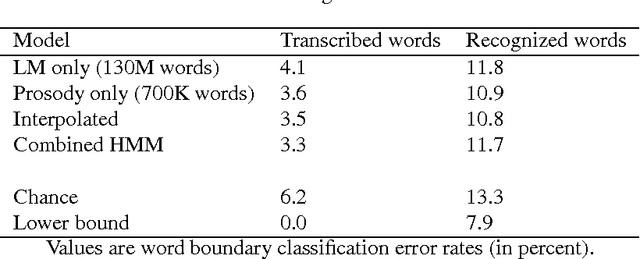
A crucial step in processing speech audio data for information extraction, topic detection, or browsing/playback is to segment the input into sentence and topic units. Speech segmentation is challenging, since the cues typically present for segmenting text (headers, paragraphs, punctuation) are absent in spoken language. We investigate the use of prosody (information gleaned from the timing and melody of speech) for these tasks. Using decision tree and hidden Markov modeling techniques, we combine prosodic cues with word-based approaches, and evaluate performance on two speech corpora, Broadcast News and Switchboard. Results show that the prosodic model alone performs on par with, or better than, word-based statistical language models -- for both true and automatically recognized words in news speech. The prosodic model achieves comparable performance with significantly less training data, and requires no hand-labeling of prosodic events. Across tasks and corpora, we obtain a significant improvement over word-only models using a probabilistic combination of prosodic and lexical information. Inspection reveals that the prosodic models capture language-independent boundary indicators described in the literature. Finally, cue usage is task and corpus dependent. For example, pause and pitch features are highly informative for segmenting news speech, whereas pause, duration and word-based cues dominate for natural conversation.
* 30 pages, 9 figures. To appear in Speech Communication 32(1-2), Special Issue on Accessing Information in Spoken Audio, September 2000
Can Prosody Aid the Automatic Classification of Dialog Acts in Conversational Speech?
Jun 11, 2000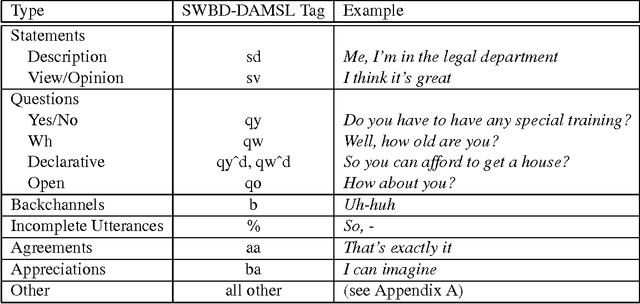
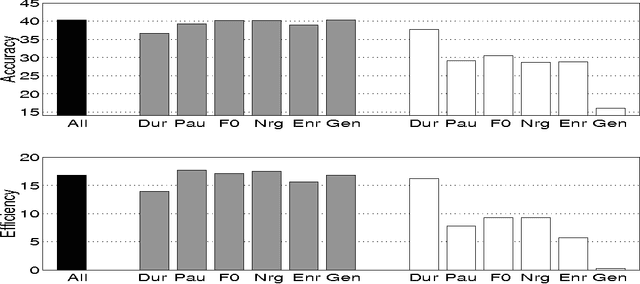

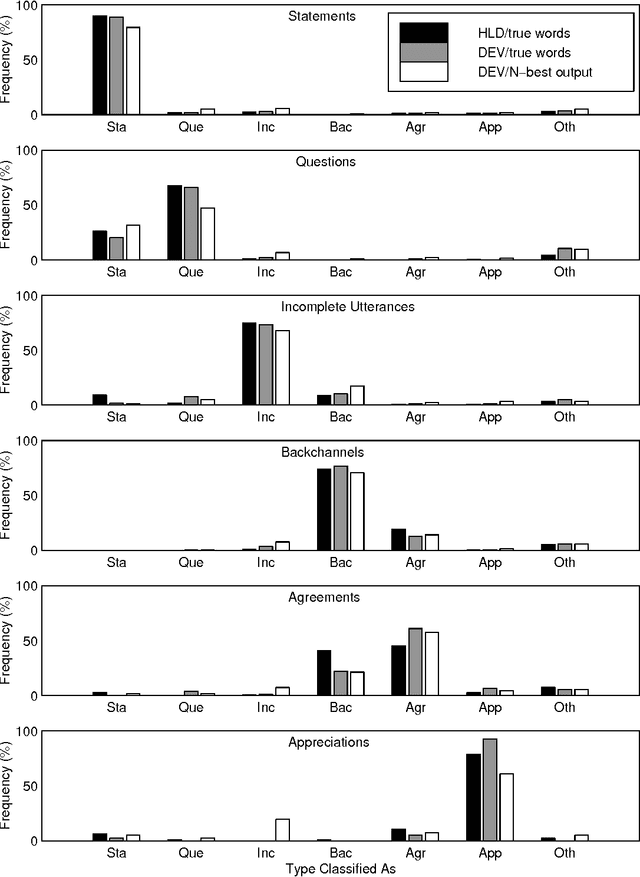
Identifying whether an utterance is a statement, question, greeting, and so forth is integral to effective automatic understanding of natural dialog. Little is known, however, about how such dialog acts (DAs) can be automatically classified in truly natural conversation. This study asks whether current approaches, which use mainly word information, could be improved by adding prosodic information. The study is based on more than 1000 conversations from the Switchboard corpus. DAs were hand-annotated, and prosodic features (duration, pause, F0, energy, and speaking rate) were automatically extracted for each DA. In training, decision trees based on these features were inferred; trees were then applied to unseen test data to evaluate performance. Performance was evaluated for prosody models alone, and after combining the prosody models with word information -- either from true words or from the output of an automatic speech recognizer. For an overall classification task, as well as three subtasks, prosody made significant contributions to classification. Feature-specific analyses further revealed that although canonical features (such as F0 for questions) were important, less obvious features could compensate if canonical features were removed. Finally, in each task, integrating the prosodic model with a DA-specific statistical language model improved performance over that of the language model alone, especially for the case of recognized words. Results suggest that DAs are redundantly marked in natural conversation, and that a variety of automatically extractable prosodic features could aid dialog processing in speech applications.
* 55 pages, 10 figures