 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Sequence Modeling for Safe Reinforcement Learning
Feb 09, 2026Offline safe reinforcement learning (RL) aims to learn policies from a fixed dataset while maximizing performance under cumulative cost constraints. In practice, deployment requirements often vary across scenarios, necessitating a single policy that can adapt zero-shot to different cost thresholds. However, most existing offline safe RL methods are trained under a pre-specified threshold, yielding policies with limited generalization and deployment flexibility across cost thresholds. Motivated by recent progress in conditional sequence modeling (CSM), which enables flexible goal-conditioned control by specifying target returns, we propose RCDT, a CSM-based method that supports zero-shot deployment across multiple cost thresholds within a single trained policy. RCDT is the first CSM-based offline safe RL algorithm that integrates a Lagrangian-style cost penalty with an auto-adaptive penalty coefficient. To avoid overly conservative behavior and achieve a more favorable return--cost trade-off, a reward--cost-aware trajectory reweighting mechanism and Q-value regularization are further incorporated. Extensive experiments on the DSRL benchmark demonstrate that RCDT consistently improves return--cost trade-offs over representative baselines, advancing the state-of-the-art in offline safe RL.
Towards Optimal Randomized Strategies in Adversarial Example Game
Jun 29, 2023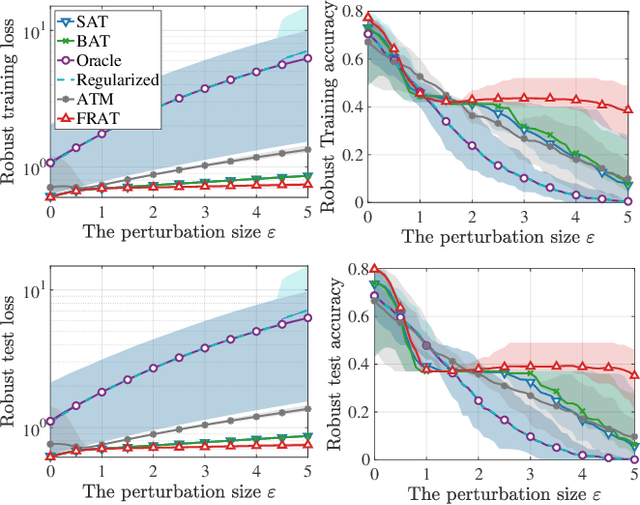
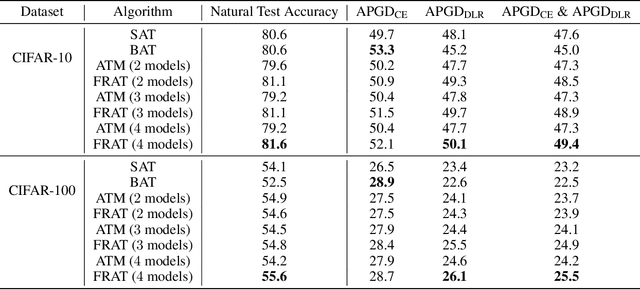
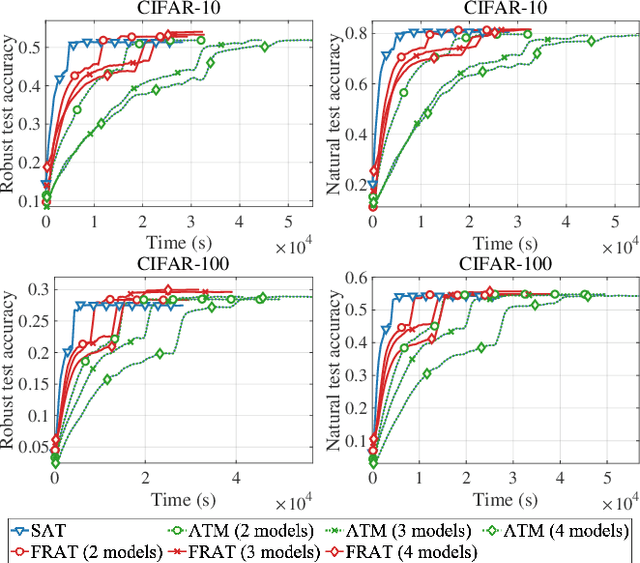
The vulnerability of deep neural network models to adversarial example attacks is a practical challenge in many artificial intelligence applications. A recent line of work shows that the use of randomization in adversarial training is the key to find optimal strategies against adversarial example attacks. However, in a fully randomized setting where both the defender and the attacker can use randomized strategies, there are no efficient algorithm for finding such an optimal strategy. To fill the gap, we propose the first algorithm of its kind, called FRAT, which models the problem with a new infinite-dimensional continuous-time flow on probability distribution spaces. FRAT maintains a lightweight mixture of models for the defender, with flexibility to efficiently update mixing weights and model parameters at each iteration. Furthermore, FRAT utilizes lightweight sampling subroutines to construct a random strategy for the attacker. We prove that the continuous-time limit of FRAT converges to a mixed Nash equilibria in a zero-sum game formed by a defender and an attacker. Experimental results also demonstrate the efficiency of FRAT on CIFAR-10 and CIFAR-100 datasets.
PACER: A Fully Push-forward-based Distributional Reinforcement Learning Algorithm
Jun 11, 2023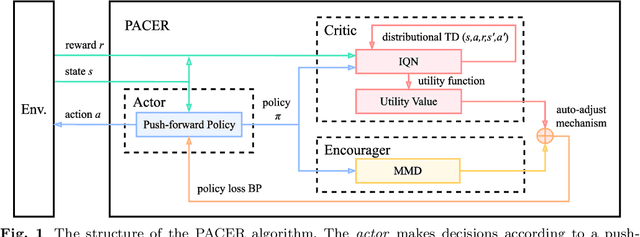
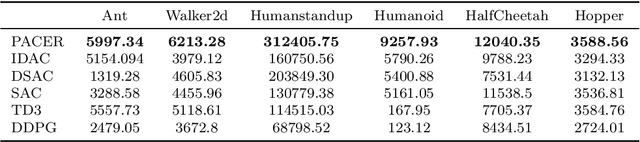
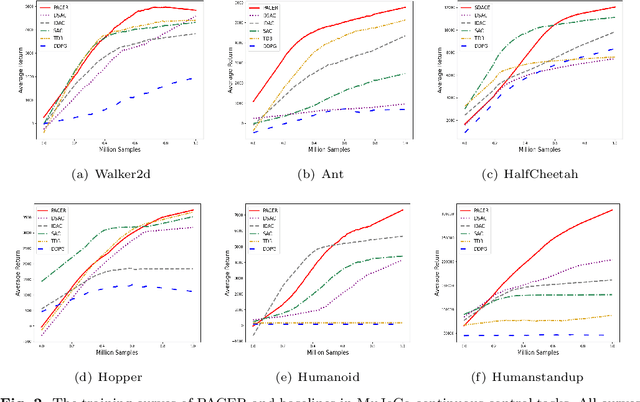

In this paper, we propose the first fully push-forward-based Distributional Reinforcement Learning algorithm, called Push-forward-based Actor-Critic EncourageR (PACER). Specifically, PACER establishes a stochastic utility value policy gradient theorem and simultaneously leverages the push-forward operator in the construction of both the actor and the critic. Moreover, based on maximum mean discrepancies (MMD), a novel sample-based encourager is designed to incentivize exploration. Experimental evaluations on various continuous control benchmarks demonstrate the superiority of our algorithm over the state-of-the-art.