Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePACER: A Fully Push-forward-based Distributional Reinforcement Learning Algorithm
Jun 11, 2023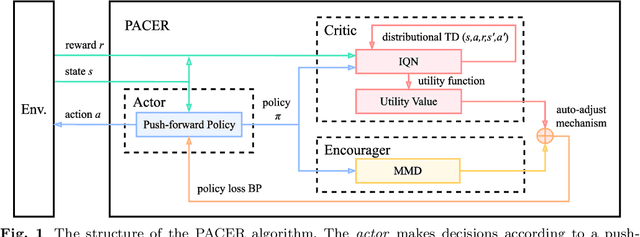
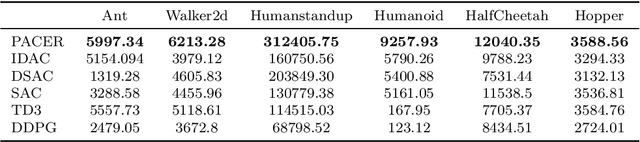
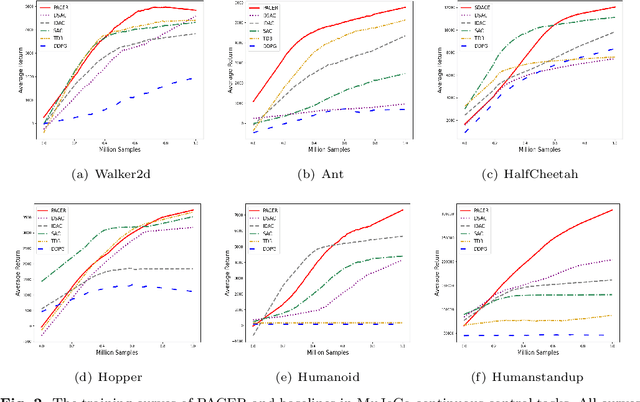

In this paper, we propose the first fully push-forward-based Distributional Reinforcement Learning algorithm, called Push-forward-based Actor-Critic EncourageR (PACER). Specifically, PACER establishes a stochastic utility value policy gradient theorem and simultaneously leverages the push-forward operator in the construction of both the actor and the critic. Moreover, based on maximum mean discrepancies (MMD), a novel sample-based encourager is designed to incentivize exploration. Experimental evaluations on various continuous control benchmarks demonstrate the superiority of our algorithm over the state-of-the-art.
Via