 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEAP-GP: Mitigating Saturation Effect in Gradient-based Automated Circuit Identification
Feb 07, 2025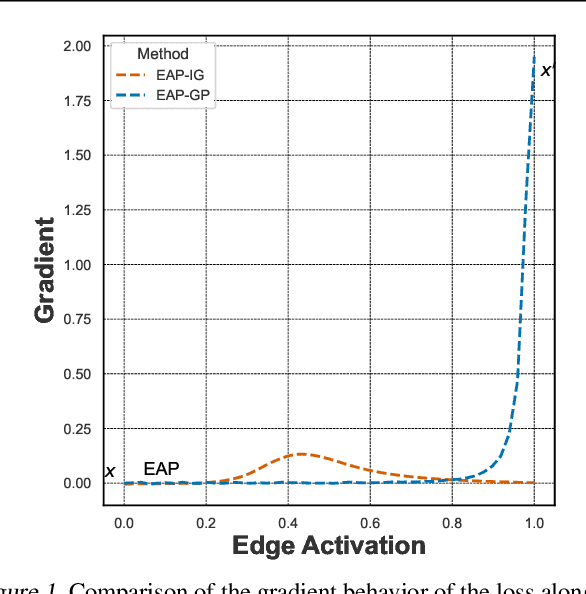

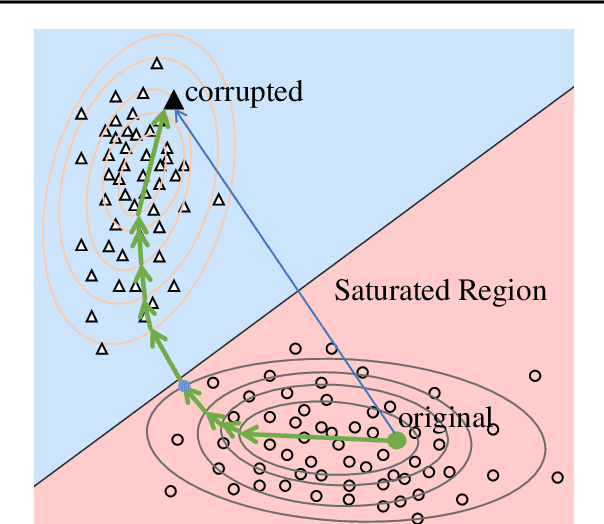

Understanding the internal mechanisms of transformer-based language models remains challenging. Mechanistic interpretability based on circuit discovery aims to reverse engineer neural networks by analyzing their internal processes at the level of computational subgraphs. In this paper, we revisit existing gradient-based circuit identification methods and find that their performance is either affected by the zero-gradient problem or saturation effects, where edge attribution scores become insensitive to input changes, resulting in noisy and unreliable attribution evaluations for circuit components. To address the saturation effect, we propose Edge Attribution Patching with GradPath (EAP-GP), EAP-GP introduces an integration path, starting from the input and adaptively following the direction of the difference between the gradients of corrupted and clean inputs to avoid the saturated region. This approach enhances attribution reliability and improves the faithfulness of circuit identification. We evaluate EAP-GP on 6 datasets using GPT-2 Small, GPT-2 Medium, and GPT-2 XL. Experimental results demonstrate that EAP-GP outperforms existing methods in circuit faithfulness, achieving improvements up to 17.7%. Comparisons with manually annotated ground-truth circuits demonstrate that EAP-GP achieves precision and recall comparable to or better than previous approaches, highlighting its effectiveness in identifying accurate circuits.