 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion-Based 3D Human Pose Estimation with Multi-Hypothesis Aggregation
Mar 21, 2023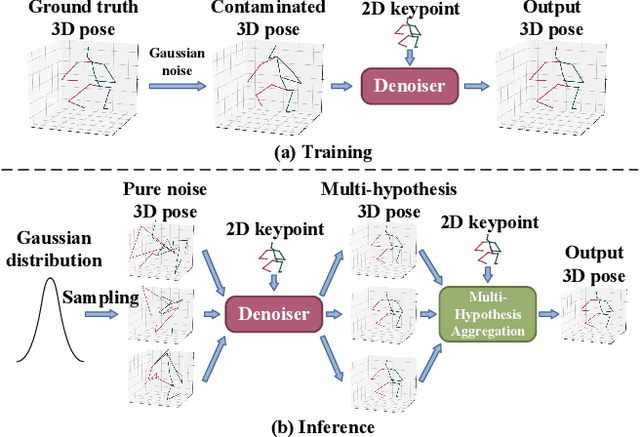
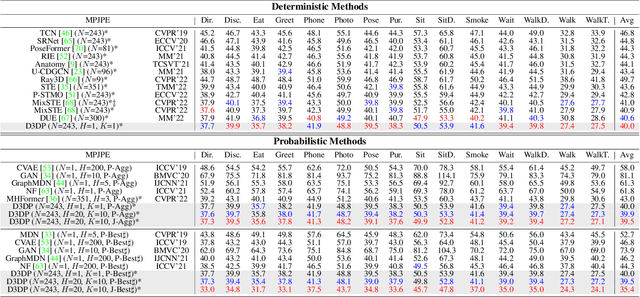

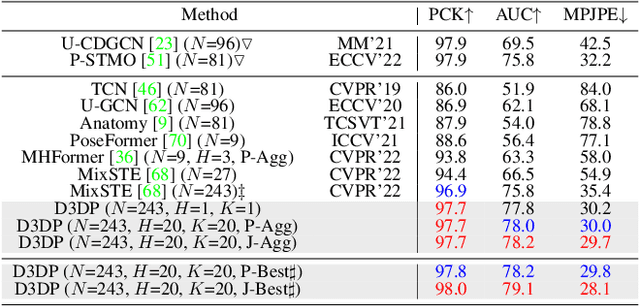
In this paper, a novel Diffusion-based 3D Pose estimation (D3DP) method with Joint-wise reProjection-based Multi-hypothesis Aggregation (JPMA) is proposed for probabilistic 3D human pose estimation. On the one hand, D3DP generates multiple possible 3D pose hypotheses for a single 2D observation. It gradually diffuses the ground truth 3D poses to a random distribution, and learns a denoiser conditioned on 2D keypoints to recover the uncontaminated 3D poses. The proposed D3DP is compatible with existing 3D pose estimators and supports users to balance efficiency and accuracy during inference through two customizable parameters. On the other hand, JPMA is proposed to assemble multiple hypotheses generated by D3DP into a single 3D pose for practical use. It reprojects 3D pose hypotheses to the 2D camera plane, selects the best hypothesis joint-by-joint based on the reprojection errors, and combines the selected joints into the final pose. The proposed JPMA conducts aggregation at the joint level and makes use of the 2D prior information, both of which have been overlooked by previous approaches. Extensive experiments on Human3.6M and MPI-INF-3DHP datasets show that our method outperforms the state-of-the-art deterministic and probabilistic approaches by 1.5% and 8.9%, respectively. Code is available at https://github.com/paTRICK-swk/D3DP.
P-STMO: Pre-Trained Spatial Temporal Many-to-One Model for 3D Human Pose Estimation
Mar 15, 2022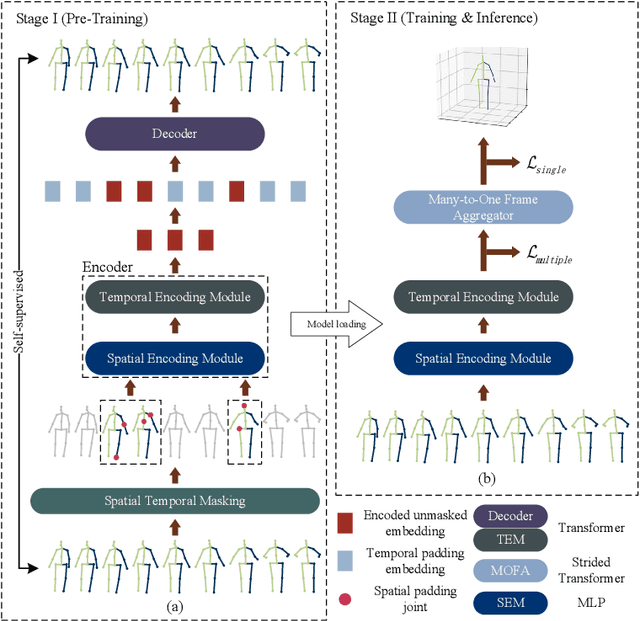
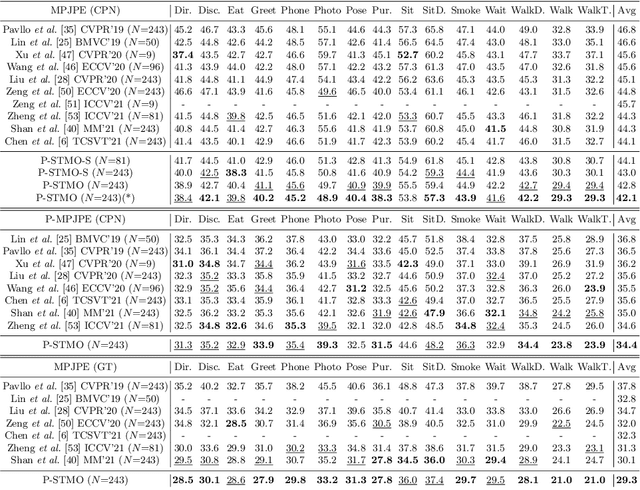

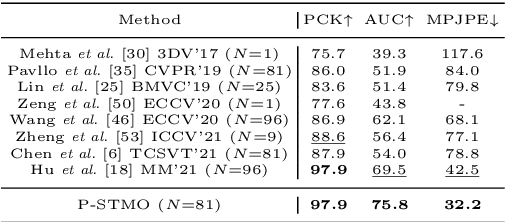
This paper introduces a novel Pre-trained Spatial Temporal Many-to-One (P-STMO) model for 2D-to-3D human pose estimation task. To reduce the difficulty of capturing spatial and temporal information, we divide this task into two stages: pre-training (Stage I) and fine-tuning (Stage II). In Stage I, a self-supervised pre-training sub-task, termed masked pose modeling, is proposed. The human joints in the input sequence are randomly masked in both spatial and temporal domains. A general form of denoising auto-encoder is exploited to recover the original 2D poses and the encoder is capable of capturing spatial and temporal dependencies in this way. In Stage II, the pre-trained encoder is loaded to STMO model and fine-tuned. The encoder is followed by a many-to-one frame aggregator to predict the 3D pose in the current frame. Especially, an MLP block is utilized as the spatial feature extractor in STMO, which yields better performance than other methods. In addition, a temporal downsampling strategy is proposed to diminish data redundancy. Extensive experiments on two benchmarks show that our method outperforms state-of-the-art methods with fewer parameters and less computational overhead. For example, our P-STMO model achieves 42.1mm MPJPE on Human3.6M dataset when using 2D poses from CPN as inputs. Meanwhile, it brings a 1.5-7.1 times speedup to state-of-the-art methods. Code is available at https://github.com/paTRICK-swk/P-STMO.
Improving Robustness and Accuracy via Relative Information Encoding in 3D Human Pose Estimation
Jul 29, 2021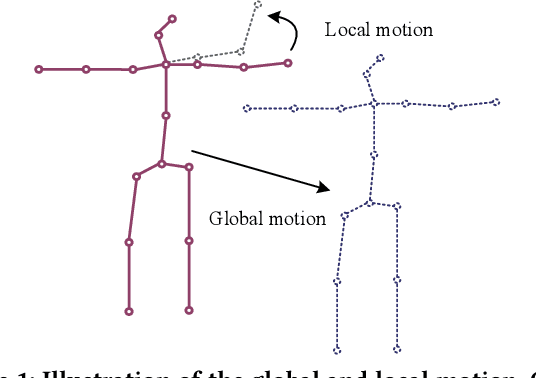
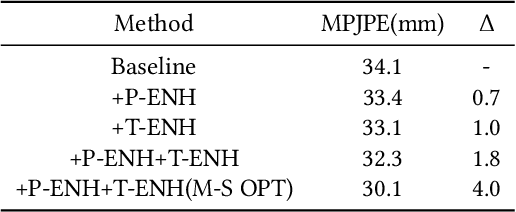
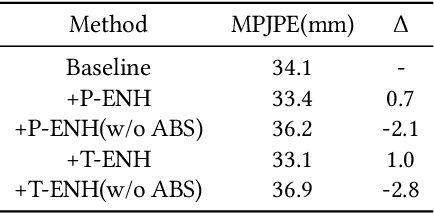
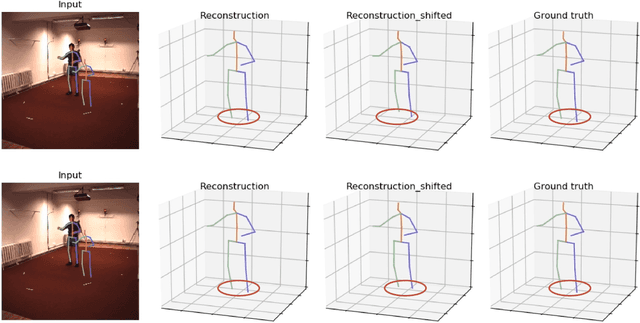
Most of the existing 3D human pose estimation approaches mainly focus on predicting 3D positional relationships between the root joint and other human joints (local motion) instead of the overall trajectory of the human body (global motion). Despite the great progress achieved by these approaches, they are not robust to global motion, and lack the ability to accurately predict local motion with a small movement range. To alleviate these two problems, we propose a relative information encoding method that yields positional and temporal enhanced representations. Firstly, we encode positional information by utilizing relative coordinates of 2D poses to enhance the consistency between the input and output distribution. The same posture with different absolute 2D positions can be mapped to a common representation. It is beneficial to resist the interference of global motion on the prediction results. Second, we encode temporal information by establishing the connection between the current pose and other poses of the same person within a period of time. More attention will be paid to the movement changes before and after the current pose, resulting in better prediction performance on local motion with a small movement range. The ablation studies validate the effectiveness of the proposed relative information encoding method. Besides, we introduce a multi-stage optimization method to the whole framework to further exploit the positional and temporal enhanced representations. Our method outperforms state-of-the-art methods on two public datasets. Code is available at https://github.com/paTRICK-swk/Pose3D-RIE.