 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Code in the Wild: Measuring Security Risks and Ecosystem Shifts of AI-Generated Code in Modern Software
Dec 21, 2025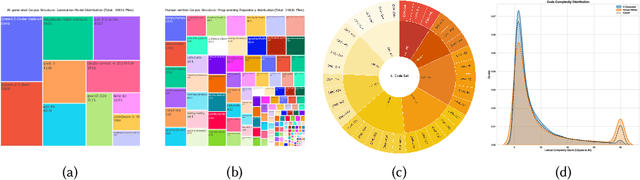
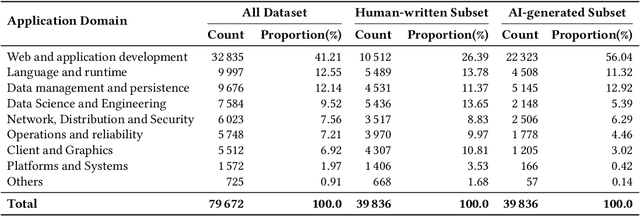
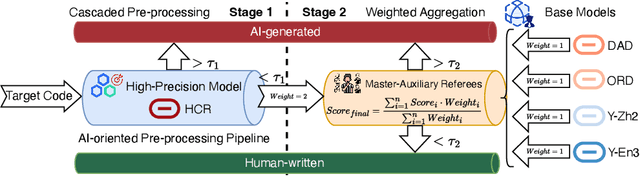
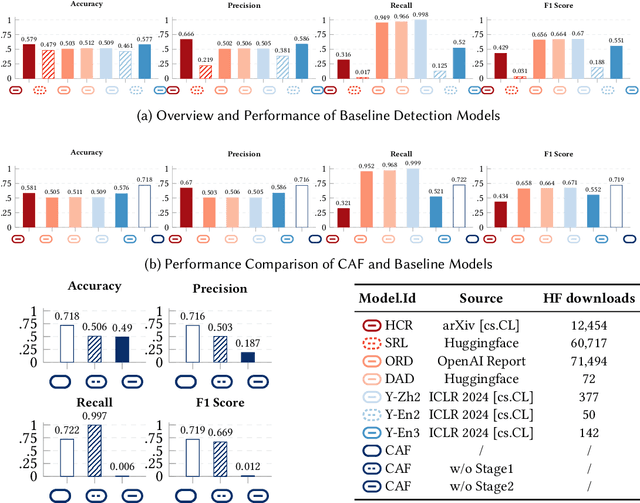
Large language models (LLMs) for code generation are becoming integral to modern software development, but their real-world prevalence and security impact remain poorly understood. We present the first large-scale empirical study of AI-generated code (AIGCode) in the wild. We build a high-precision detection pipeline and a representative benchmark to distinguish AIGCode from human-written code, and apply them to (i) development commits from the top 1,000 GitHub repositories (2022-2025) and (ii) 7,000+ recent CVE-linked code changes. This lets us label commits, files, and functions along a human/AI axis and trace how AIGCode moves through projects and vulnerability life cycles. Our measurements show three ecological patterns. First, AIGCode is already a substantial fraction of new code, but adoption is structured: AI concentrates in glue code, tests, refactoring, documentation, and other boilerplate, while core logic and security-critical configurations remain mostly human-written. Second, adoption has security consequences: some CWE families are overrepresented in AI-tagged code, and near-identical insecure templates recur across unrelated projects, suggesting "AI-induced vulnerabilities" propagated by shared models rather than shared maintainers. Third, in human-AI edit chains, AI introduces high-throughput changes while humans act as security gatekeepers; when review is shallow, AI-introduced defects persist longer, remain exposed on network-accessible surfaces, and spread to more files and repositories. We will open-source the complete dataset and release analysis artifacts and fine-grained documentation of our methodology and findings.
BitPipe: Bidirectional Interleaved Pipeline Parallelism for Accelerating Large Models Training
Oct 25, 2024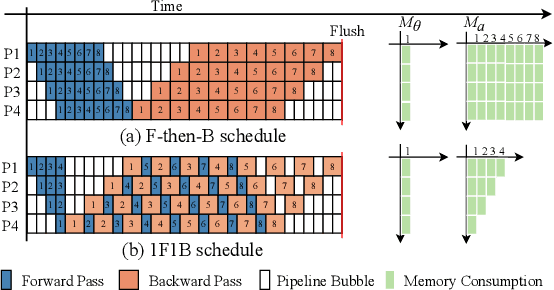
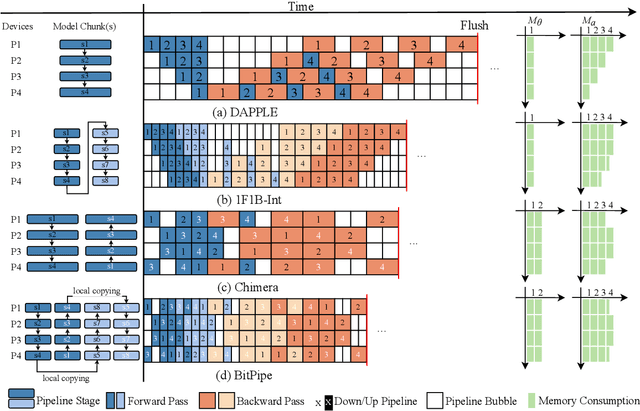

With the increasing scale of models, the need for efficient distributed training has become increasingly urgent. Recently, many synchronous pipeline parallelism approaches have been proposed to improve training throughput. However, these approaches still suffer from two major issues, i.e., pipeline bubbles caused by periodic flushing and extra communication due to the increasing number of pipeline stages. To this end, we propose BitPipe, a bidirectional interleaved pipeline parallelism for accelerating large models training. Specifically, a hybrid scheme of fusing interleaved pipelines with bidirectional pipelines is proposed to reduce the computational time of each single micro-batch and multiply the number of devices executing simultaneously. A V-shaped schedule with eager gradient synchronization is introduced to reduce and overlap the communication between devices. Experiments conducted on up to 32 GPUs show that BitPipe improves the training throughput of GPT-style and BERT-style models by 1.05x-1.28x compared to the state-of-the-art synchronous approaches. The code of our implementation is available at https://github.com/wuhouming/BitPipe.