 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTawPipe: Topology-Aware Weight Pipeline Parallelism for Accelerating Long-Context Large Models Training
Nov 12, 2025Training large language models (LLMs) is fundamentally constrained by limited device memory and costly inter-device communication. Although pipeline parallelism alleviates memory pressure by partitioning models across devices, it incurs activation communication overhead that scales linearly with sequence length, limiting efficiency in long-context training. Recent weight-passing approaches (e.g., WeiPipe) mitigate this by transmitting model weights instead of activations, but suffer from redundant peer-to-peer (P2P) transfers and underutilized intra-node bandwidth. We propose TawPipe--topology-aware weight pipeline parallelism, which exploits hierarchical bandwidth in distributed clusters for improved communication efficiency. TawPipe: (i) groups devices based on topology to optimize intra-node collective and inter-node P2P communication; (ii) assigns each device a fixed shard of model weights and gradients, avoiding redundant transfers; and (iii) overlaps communication with computation to hide latency. Unlike global collective operations used in fully sharded data parallelism (FSDP), TawPipe confines most communication within node boundaries, significantly reducing cross-node traffic. Extensive experiments on up to 24 GPUs with LLaMA-style models show that TawPipe achieves superior throughput and scalability compared to state-of-the-art baselines.
BitPipe: Bidirectional Interleaved Pipeline Parallelism for Accelerating Large Models Training
Oct 25, 2024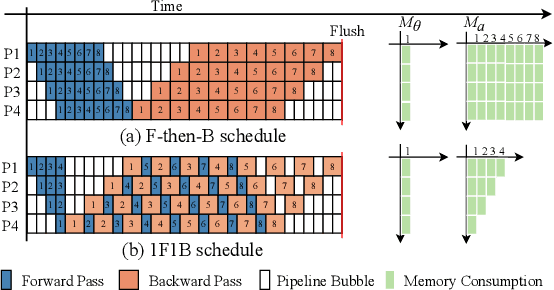
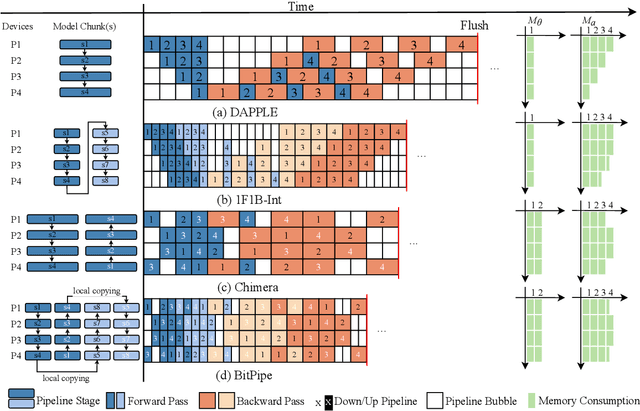

With the increasing scale of models, the need for efficient distributed training has become increasingly urgent. Recently, many synchronous pipeline parallelism approaches have been proposed to improve training throughput. However, these approaches still suffer from two major issues, i.e., pipeline bubbles caused by periodic flushing and extra communication due to the increasing number of pipeline stages. To this end, we propose BitPipe, a bidirectional interleaved pipeline parallelism for accelerating large models training. Specifically, a hybrid scheme of fusing interleaved pipelines with bidirectional pipelines is proposed to reduce the computational time of each single micro-batch and multiply the number of devices executing simultaneously. A V-shaped schedule with eager gradient synchronization is introduced to reduce and overlap the communication between devices. Experiments conducted on up to 32 GPUs show that BitPipe improves the training throughput of GPT-style and BERT-style models by 1.05x-1.28x compared to the state-of-the-art synchronous approaches. The code of our implementation is available at https://github.com/wuhouming/BitPipe.
ABS-SGD: A Delayed Synchronous Stochastic Gradient Descent Algorithm with Adaptive Batch Size for Heterogeneous GPU Clusters
Aug 29, 2023As the size of models and datasets grows, it has become increasingly common to train models in parallel. However, existing distributed stochastic gradient descent (SGD) algorithms suffer from insufficient utilization of computational resources and poor convergence in heterogeneous clusters. In this paper, we propose a delayed synchronous SGD algorithm with adaptive batch size (ABS-SGD) for heterogeneous GPU clusters. In ABS-SGD, workers perform global synchronization to accumulate delayed gradients and use the accumulated delayed gradients to update parameters. While workers are performing global synchronization for delayed gradients, they perform the computation of the next batch without specifying batch size in advance, which lasts until the next global synchronization starts, realizing the full utilization of computational resources. Since the gradient delay is only one iteration, the stale gradient problem can be alleviated. We theoretically prove the convergence of ABS-SGD in heterogeneous clusters. Extensive experiments in three types of heterogeneous clusters demonstrate that ABS-SGD can make full use of computational resources and accelerate model convergence: When training ResNet18 network with 4 workers, ABS-SGD increases the convergence speed by 1.30x on average compared with the best baseline algorithm.