 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeed-ASR: Understanding Diverse Speech and Contexts with LLM-based Speech Recognition
Jul 05, 2024



Modern automatic speech recognition (ASR) model is required to accurately transcribe diverse speech signals (from different domains, languages, accents, etc) given the specific contextual information in various application scenarios. Classic end-to-end models fused with extra language models perform well, but mainly in data matching scenarios and are gradually approaching a bottleneck. In this work, we introduce Seed-ASR, a large language model (LLM) based speech recognition model. Seed-ASR is developed based on the framework of audio conditioned LLM (AcLLM), leveraging the capabilities of LLMs by inputting continuous speech representations together with contextual information into the LLM. Through stage-wise large-scale training and the elicitation of context-aware capabilities in LLM, Seed-ASR demonstrates significant improvement over end-to-end models on comprehensive evaluation sets, including multiple domains, accents/dialects and languages. Additionally, Seed-ASR can be further deployed to support specific needs in various scenarios without requiring extra language models. Compared to recently released large ASR models, Seed-ASR achieves 10%-40% reduction in word (or character, for Chinese) error rates on Chinese and English public test sets, further demonstrating its powerful performance.
Conv-Transformer Transducer: Low Latency, Low Frame Rate, Streamable End-to-End Speech Recognition
Aug 13, 2020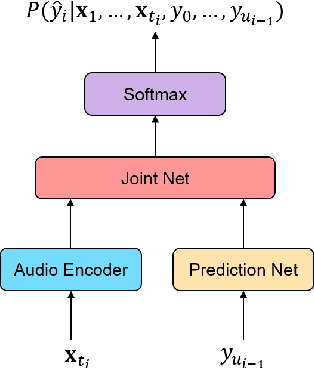
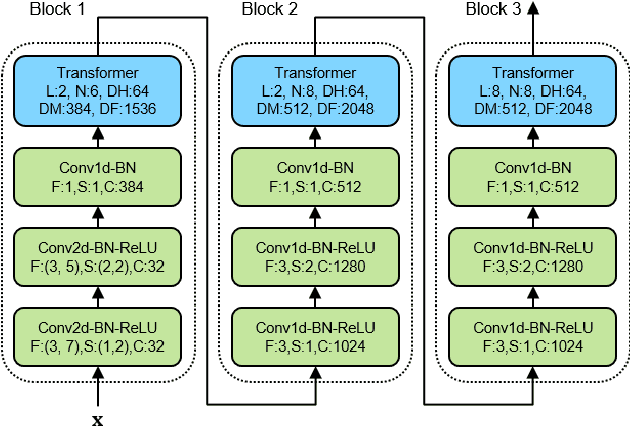
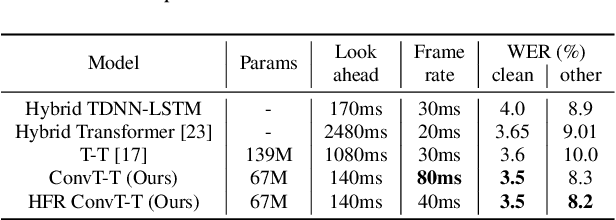
Transformer has achieved competitive performance against state-of-the-art end-to-end models in automatic speech recognition (ASR), and requires significantly less training time than RNN-based models. The original Transformer, with encoder-decoder architecture, is only suitable for offline ASR. It relies on an attention mechanism to learn alignments, and encodes input audio bidirectionally. The high computation cost of Transformer decoding also limits its use in production streaming systems. To make Transformer suitable for streaming ASR, we explore Transducer framework as a streamable way to learn alignments. For audio encoding, we apply unidirectional Transformer with interleaved convolution layers. The interleaved convolution layers are used for modeling future context which is important to performance. To reduce computation cost, we gradually downsample acoustic input, also with the interleaved convolution layers. Moreover, we limit the length of history context in self-attention to maintain constant computation cost for each decoding step. We show that this architecture, named Conv-Transformer Transducer, achieves competitive performance on LibriSpeech dataset (3.6\% WER on test-clean) without external language models. The performance is comparable to previously published streamable Transformer Transducer and strong hybrid streaming ASR systems, and is achieved with smaller look-ahead window (140~ms), fewer parameters and lower frame rate.