 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText classification with pixel embedding
Nov 14, 2019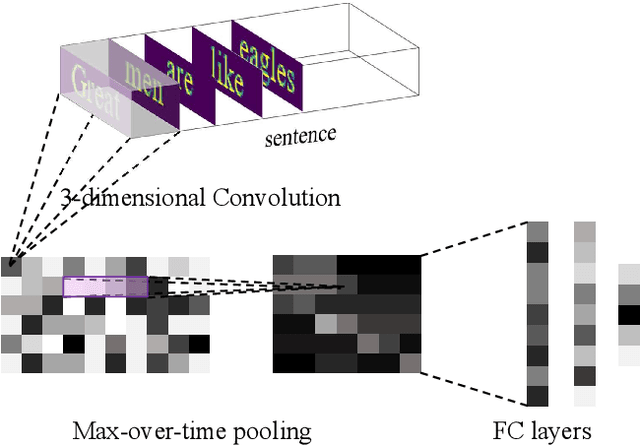
We propose a novel framework to understand the text by converting sentences or articles into video-like 3-dimensional tensors. Each frame, corresponding to a slice of the tensor, is a word image that is rendered by the word's shape. The length of the tensor equals to the number of words in the sentence or article. The proposed transformation from the text to a 3-dimensional tensor makes it very convenient to implement an $n$-gram model with convolutional neural networks for text analysis. Concretely, we impose a 3-dimensional convolutional kernel on the 3-dimensional text tensor. The first two dimensions of the convolutional kernel size equal the size of the word image and the last dimension of the kernel size is $n$. That is, every time when we slide the 3-dimensional kernel over a word sequence, the convolution covers $n$ word images and outputs a scalar. By iterating this process continuously for each $n$-gram along with the sentence or article with multiple kernels, we obtain a 2-dimensional feature map. A subsequent 1-dimensional max-over-time pooling is applied to this feature map, and three fully-connected layers are used for conducting text classification finally. Experiments of several text classification datasets demonstrate surprisingly superior performances using the proposed model in comparison with existing methods.
Product Image Recognition with Guidance Learning and Noisy Supervision
Jul 26, 2019


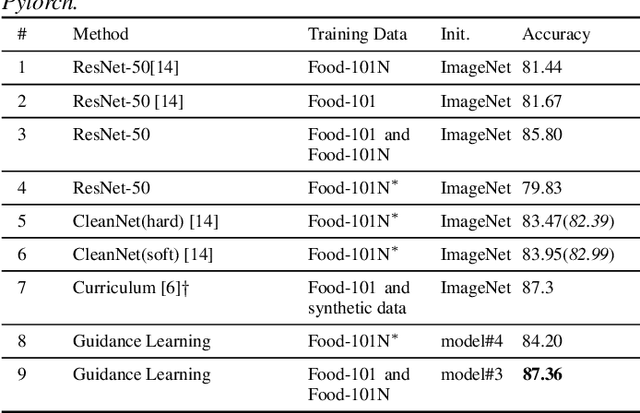
This paper considers recognizing products from daily photos, which is an important problem in real-world applications but also challenging due to background clutters, category diversities, noisy labels, etc. We address this problem by two contributions. First, we introduce a novel large-scale product image dataset, termed as Product-90. Instead of collecting product images by labor-and time-intensive image capturing, we take advantage of the web and download images from the reviews of several e-commerce websites where the images are casually captured by consumers. Labels are assigned automatically by the categories of e-commerce websites. Totally the Product-90 consists of more than 140K images with 90 categories. Due to the fact that consumers may upload unrelated images, it is inevitable that our Product-90 introduces noisy labels. As the second contribution, we develop a simple yet efficient \textit{guidance learning} (GL) method for training convolutional neural networks (CNNs) with noisy supervision. The GL method first trains an initial teacher network with the full noisy dataset, and then trains a target/student network with both large-scale noisy set and small manually-verified clean set in a multi-task manner. Specifically, in the stage of student network training, the large-scale noisy data is supervised by its guidance knowledge which is the combination of its given noisy label and the soften label from the teacher network. We conduct extensive experiments on our Products-90 and public datasets, namely Food101, Food-101N, and Clothing1M. Our guidance learning method achieves performance superior to state-of-the-art methods on these datasets.
Object-Scene Convolutional Neural Networks for Event Recognition in Images
May 02, 2015
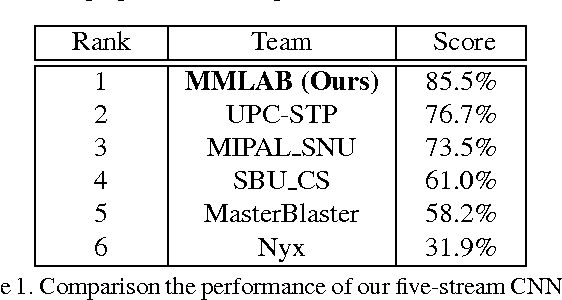

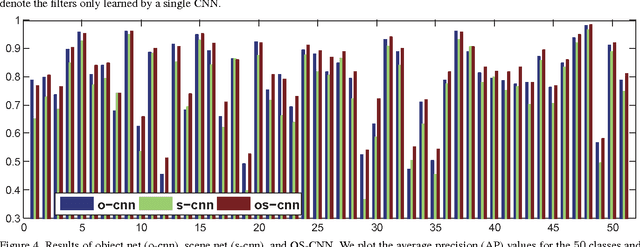
Event recognition from still images is of great importance for image understanding. However, compared with event recognition in videos, there are much fewer research works on event recognition in images. This paper addresses the issue of event recognition from images and proposes an effective method with deep neural networks. Specifically, we design a new architecture, called Object-Scene Convolutional Neural Network (OS-CNN). This architecture is decomposed into object net and scene net, which extract useful information for event understanding from the perspective of objects and scene context, respectively. Meanwhile, we investigate different network architectures for OS-CNN design, and adapt the deep (AlexNet) and very-deep (GoogLeNet) networks to the task of event recognition. Furthermore, we find that the deep and very-deep networks are complementary to each other. Finally, based on the proposed OS-CNN and comparative study of different network architectures, we come up with a solution of five-stream CNN for the track of cultural event recognition at the ChaLearn Looking at People (LAP) challenge 2015. Our method obtains the performance of 85.5% and ranks the $1^{st}$ place in this challenge.