 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Prompt to Graph: Comparing LLM-Based Information Extraction Strategies in Domain-Specific Ontology Development
Jan 31, 2026Ontologies are essential for structuring domain knowledge, improving accessibility, sharing, and reuse. However, traditional ontology construction relies on manual annotation and conventional natural language processing (NLP) techniques, making the process labour-intensive and costly, especially in specialised fields like casting manufacturing. The rise of Large Language Models (LLMs) offers new possibilities for automating knowledge extraction. This study investigates three LLM-based approaches, including pre-trained LLM-driven method, in-context learning (ICL) method and fine-tuning method to extract terms and relations from domain-specific texts using limited data. We compare their performances and use the best-performing method to build a casting ontology that validated by domian expert.
Pixel and Feature Level Based Domain Adaption for Object Detection in Autonomous Driving
Sep 30, 2018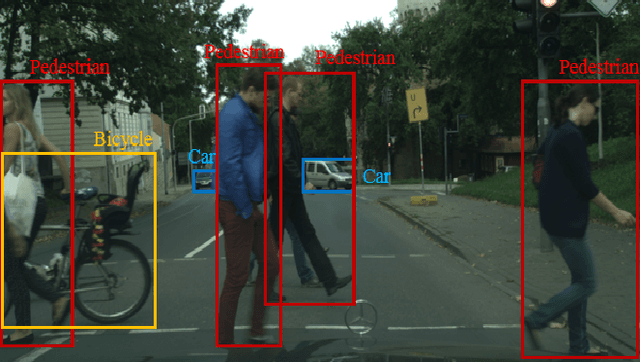
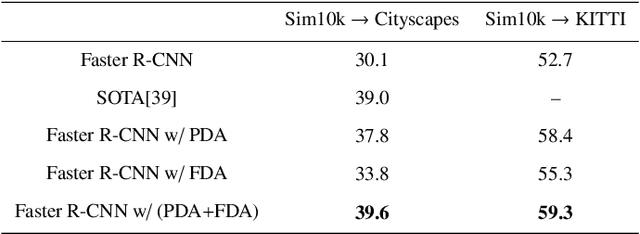
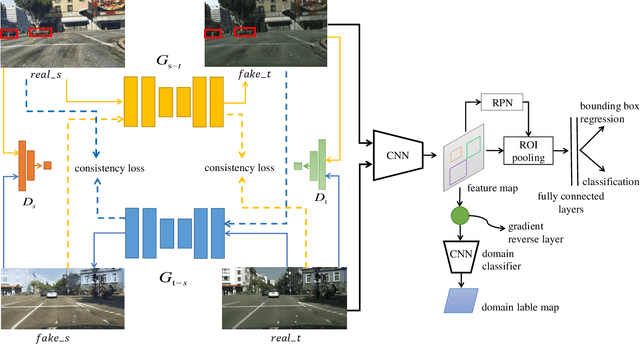
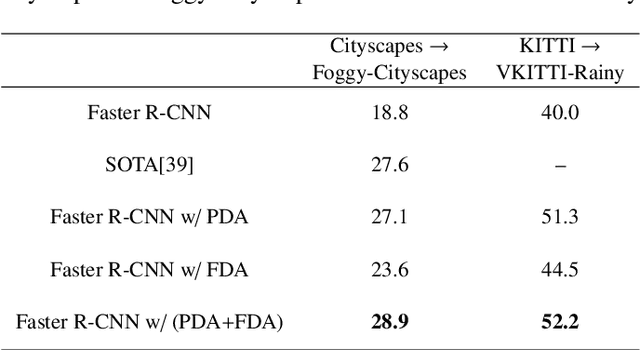
Annotating large scale datasets to train modern convolutional neural networks is prohibitively expensive and time-consuming for many real tasks. One alternative is to train the model on labeled synthetic datasets and apply it in the real scenes. However, this straightforward method often fails to generalize well mainly due to the domain bias between the synthetic and real datasets. Many unsupervised domain adaptation (UDA) methods are introduced to address this problem but most of them only focus on the simple classification task. In this paper, we present a novel UDA model to solve the more complex object detection problem in the context of autonomous driving. Our model integrates both pixel level and feature level based transformtions to fulfill the cross domain detection task and can be further trained end-to-end to pursue better performance. We employ objectives of the generative adversarial network and the cycle consistency loss for image translation in the pixel space. To address the potential semantic inconsistency problem, we propose region proposal based feature adversarial training to preserve the semantics of our target objects as well as further minimize the domain shifts. Extensive experiments are conducted on several different datasets, and the results demonstrate the robustness and superiority of our method.
Tree-Structured Reinforcement Learning for Sequential Object Localization
Mar 08, 2017



Existing object proposal algorithms usually search for possible object regions over multiple locations and scales separately, which ignore the interdependency among different objects and deviate from the human perception procedure. To incorporate global interdependency between objects into object localization, we propose an effective Tree-structured Reinforcement Learning (Tree-RL) approach to sequentially search for objects by fully exploiting both the current observation and historical search paths. The Tree-RL approach learns multiple searching policies through maximizing the long-term reward that reflects localization accuracies over all the objects. Starting with taking the entire image as a proposal, the Tree-RL approach allows the agent to sequentially discover multiple objects via a tree-structured traversing scheme. Allowing multiple near-optimal policies, Tree-RL offers more diversity in search paths and is able to find multiple objects with a single feed-forward pass. Therefore, Tree-RL can better cover different objects with various scales which is quite appealing in the context of object proposal. Experiments on PASCAL VOC 2007 and 2012 validate the effectiveness of the Tree-RL, which can achieve comparable recalls with current object proposal algorithms via much fewer candidate windows.
* Advances in Neural Information Processing Systems 2016
Scale-aware Pixel-wise Object Proposal Networks
Jul 23, 2016



Object proposal is essential for current state-of-the-art object detection pipelines. However, the existing proposal methods generally fail in producing results with satisfying localization accuracy. The case is even worse for small objects which however are quite common in practice. In this paper we propose a novel Scale-aware Pixel-wise Object Proposal (SPOP) network to tackle the challenges. The SPOP network can generate proposals with high recall rate and average best overlap (ABO), even for small objects. In particular, in order to improve the localization accuracy, a fully convolutional network is employed which predicts locations of object proposals for each pixel. The produced ensemble of pixel-wise object proposals enhances the chance of hitting the object significantly without incurring heavy extra computational cost. To solve the challenge of localizing objects at small scale, two localization networks which are specialized for localizing objects with different scales are introduced, following the divide-and-conquer philosophy. Location outputs of these two networks are then adaptively combined to generate the final proposals by a large-/small-size weighting network. Extensive evaluations on PASCAL VOC 2007 show the SPOP network is superior over the state-of-the-art models. The high-quality proposals from SPOP network also significantly improve the mean average precision (mAP) of object detection with Fast-RCNN framework. Finally, the SPOP network (trained on PASCAL VOC) shows great generalization performance when testing it on ILSVRC 2013 validation set.