 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixel and Feature Level Based Domain Adaption for Object Detection in Autonomous Driving
Paper and Code
Sep 30, 2018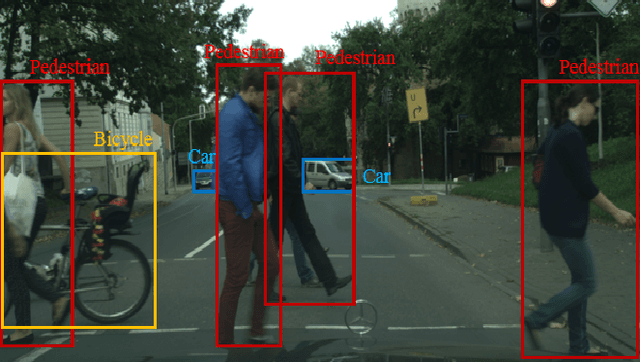
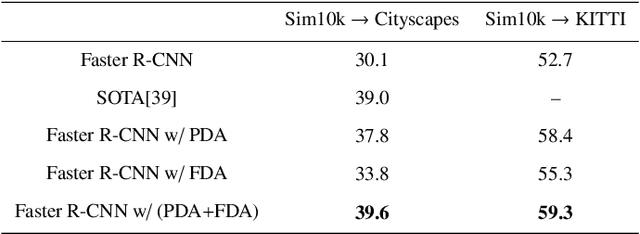
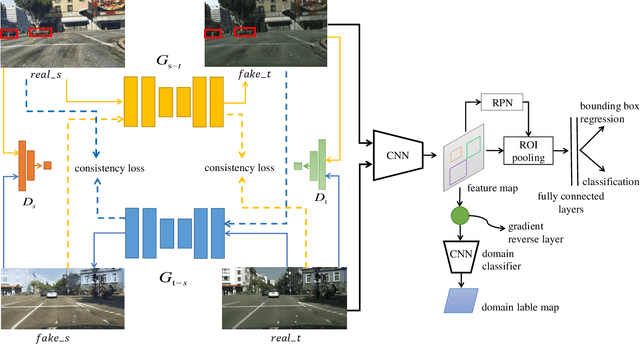
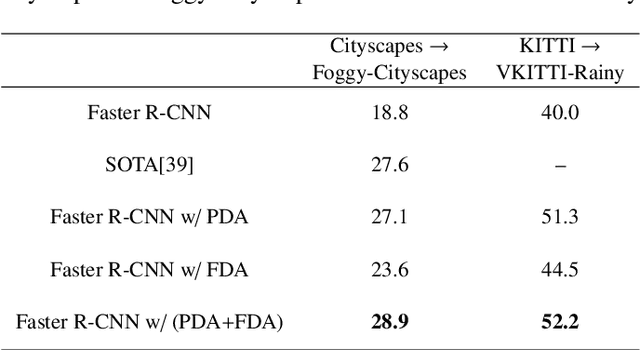
Annotating large scale datasets to train modern convolutional neural networks is prohibitively expensive and time-consuming for many real tasks. One alternative is to train the model on labeled synthetic datasets and apply it in the real scenes. However, this straightforward method often fails to generalize well mainly due to the domain bias between the synthetic and real datasets. Many unsupervised domain adaptation (UDA) methods are introduced to address this problem but most of them only focus on the simple classification task. In this paper, we present a novel UDA model to solve the more complex object detection problem in the context of autonomous driving. Our model integrates both pixel level and feature level based transformtions to fulfill the cross domain detection task and can be further trained end-to-end to pursue better performance. We employ objectives of the generative adversarial network and the cycle consistency loss for image translation in the pixel space. To address the potential semantic inconsistency problem, we propose region proposal based feature adversarial training to preserve the semantics of our target objects as well as further minimize the domain shifts. Extensive experiments are conducted on several different datasets, and the results demonstrate the robustness and superiority of our method.