 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Kimi Linear: An Expressive, Efficient Attention Architecture
Oct 30, 2025We introduce Kimi Linear, a hybrid linear attention architecture that, for the first time, outperforms full attention under fair comparisons across various scenarios -- including short-context, long-context, and reinforcement learning (RL) scaling regimes. At its core lies Kimi Delta Attention (KDA), an expressive linear attention module that extends Gated DeltaNet with a finer-grained gating mechanism, enabling more effective use of limited finite-state RNN memory. Our bespoke chunkwise algorithm achieves high hardware efficiency through a specialized variant of the Diagonal-Plus-Low-Rank (DPLR) transition matrices, which substantially reduces computation compared to the general DPLR formulation while remaining more consistent with the classical delta rule. We pretrain a Kimi Linear model with 3B activated parameters and 48B total parameters, based on a layerwise hybrid of KDA and Multi-Head Latent Attention (MLA). Our experiments show that with an identical training recipe, Kimi Linear outperforms full MLA with a sizeable margin across all evaluated tasks, while reducing KV cache usage by up to 75% and achieving up to 6 times decoding throughput for a 1M context. These results demonstrate that Kimi Linear can be a drop-in replacement for full attention architectures with superior performance and efficiency, including tasks with longer input and output lengths. To support further research, we open-source the KDA kernel and vLLM implementations, and release the pre-trained and instruction-tuned model checkpoints.
Kimi K2: Open Agentic Intelligence
Jul 28, 2025



We introduce Kimi K2, a Mixture-of-Experts (MoE) large language model with 32 billion activated parameters and 1 trillion total parameters. We propose the MuonClip optimizer, which improves upon Muon with a novel QK-clip technique to address training instability while enjoying the advanced token efficiency of Muon. Based on MuonClip, K2 was pre-trained on 15.5 trillion tokens with zero loss spike. During post-training, K2 undergoes a multi-stage post-training process, highlighted by a large-scale agentic data synthesis pipeline and a joint reinforcement learning (RL) stage, where the model improves its capabilities through interactions with real and synthetic environments. Kimi K2 achieves state-of-the-art performance among open-source non-thinking models, with strengths in agentic capabilities. Notably, K2 obtains 66.1 on Tau2-Bench, 76.5 on ACEBench (En), 65.8 on SWE-Bench Verified, and 47.3 on SWE-Bench Multilingual -- surpassing most open and closed-sourced baselines in non-thinking settings. It also exhibits strong capabilities in coding, mathematics, and reasoning tasks, with a score of 53.7 on LiveCodeBench v6, 49.5 on AIME 2025, 75.1 on GPQA-Diamond, and 27.1 on OJBench, all without extended thinking. These results position Kimi K2 as one of the most capable open-source large language models to date, particularly in software engineering and agentic tasks. We release our base and post-trained model checkpoints to facilitate future research and applications of agentic intelligence.
Consistent Point Orientation for Manifold Surfaces via Boundary Integration
Jul 03, 2024This paper introduces a new approach for generating globally consistent normals for point clouds sampled from manifold surfaces. Given that the generalized winding number (GWN) field generated by a point cloud with globally consistent normals is a solution to a PDE with jump boundary conditions and possesses harmonic properties, and the Dirichlet energy of the GWN field can be defined as an integral over the boundary surface, we formulate a boundary energy derived from the Dirichlet energy of the GWN. Taking as input a point cloud with randomly oriented normals, we optimize this energy to restore the global harmonicity of the GWN field, thereby recovering the globally consistent normals. Experiments show that our method outperforms state-of-the-art approaches, exhibiting enhanced robustness to noise, outliers, complex topologies, and thin structures. Our code can be found at \url{https://github.com/liuweizhou319/BIM}.
UniDistill: A Universal Cross-Modality Knowledge Distillation Framework for 3D Object Detection in Bird's-Eye View
Mar 27, 2023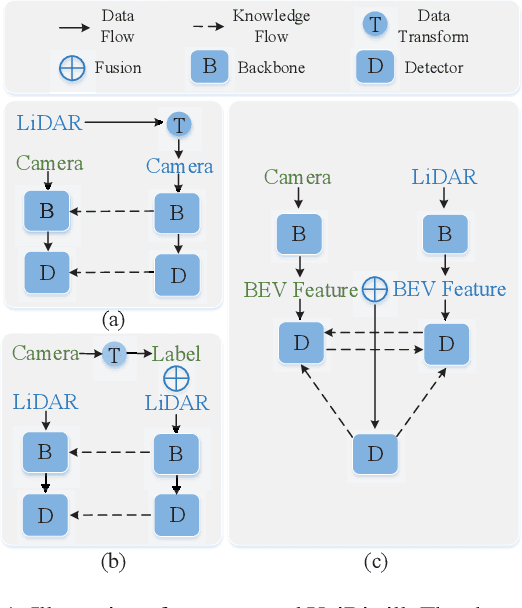
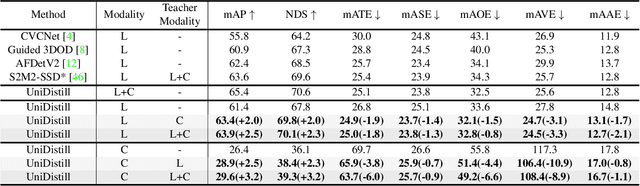
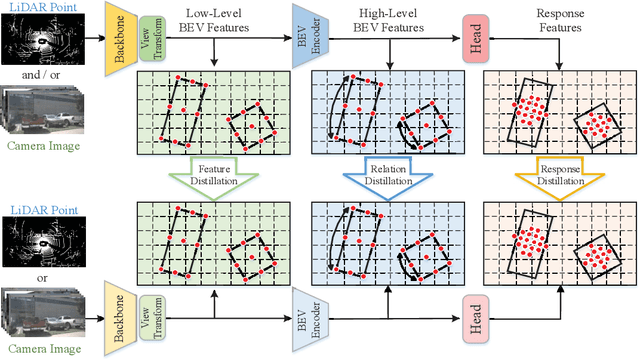
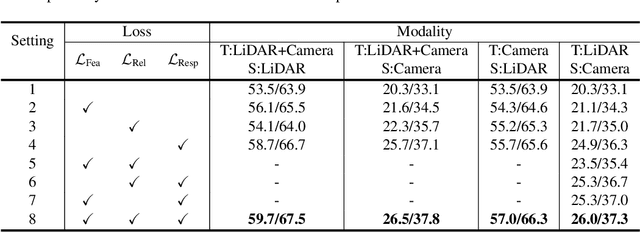
In the field of 3D object detection for autonomous driving, the sensor portfolio including multi-modality and single-modality is diverse and complex. Since the multi-modal methods have system complexity while the accuracy of single-modal ones is relatively low, how to make a tradeoff between them is difficult. In this work, we propose a universal cross-modality knowledge distillation framework (UniDistill) to improve the performance of single-modality detectors. Specifically, during training, UniDistill projects the features of both the teacher and the student detector into Bird's-Eye-View (BEV), which is a friendly representation for different modalities. Then, three distillation losses are calculated to sparsely align the foreground features, helping the student learn from the teacher without introducing additional cost during inference. Taking advantage of the similar detection paradigm of different detectors in BEV, UniDistill easily supports LiDAR-to-camera, camera-to-LiDAR, fusion-to-LiDAR and fusion-to-camera distillation paths. Furthermore, the three distillation losses can filter the effect of misaligned background information and balance between objects of different sizes, improving the distillation effectiveness. Extensive experiments on nuScenes demonstrate that UniDistill effectively improves the mAP and NDS of student detectors by 2.0%~3.2%.
OccDepth: A Depth-Aware Method for 3D Semantic Scene Completion
Feb 27, 20233D Semantic Scene Completion (SSC) can provide dense geometric and semantic scene representations, which can be applied in the field of autonomous driving and robotic systems. It is challenging to estimate the complete geometry and semantics of a scene solely from visual images, and accurate depth information is crucial for restoring 3D geometry. In this paper, we propose the first stereo SSC method named OccDepth, which fully exploits implicit depth information from stereo images (or RGBD images) to help the recovery of 3D geometric structures. The Stereo Soft Feature Assignment (Stereo-SFA) module is proposed to better fuse 3D depth-aware features by implicitly learning the correlation between stereo images. In particular, when the input are RGBD image, a virtual stereo images can be generated through original RGB image and depth map. Besides, the Occupancy Aware Depth (OAD) module is used to obtain geometry-aware 3D features by knowledge distillation using pre-trained depth models. In addition, a reformed TartanAir benchmark, named SemanticTartanAir, is provided in this paper for further testing our OccDepth method on SSC task. Compared with the state-of-the-art RGB-inferred SSC method, extensive experiments on SemanticKITTI show that our OccDepth method achieves superior performance with improving +4.82% mIoU, of which +2.49% mIoU comes from stereo images and +2.33% mIoU comes from our proposed depth-aware method. Our code and trained models are available at https://github.com/megvii-research/OccDepth.