 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
Learning to Drive from a World Model
Apr 27, 2025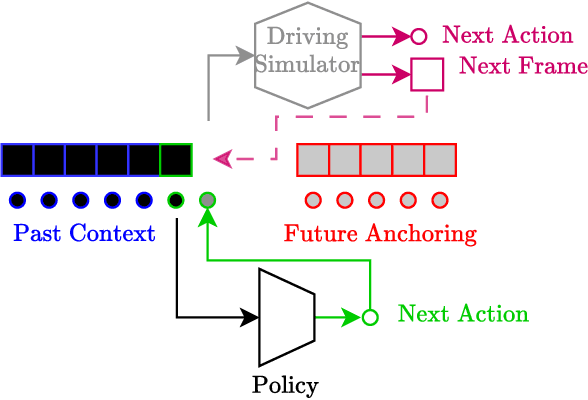

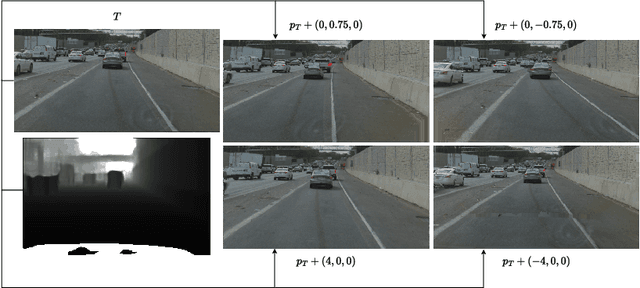

Most self-driving systems rely on hand-coded perception outputs and engineered driving rules. Learning directly from human driving data with an end-to-end method can allow for a training architecture that is simpler and scales well with compute and data. In this work, we propose an end-to-end training architecture that uses real driving data to train a driving policy in an on-policy simulator. We show two different methods of simulation, one with reprojective simulation and one with a learned world model. We show that both methods can be used to train a policy that learns driving behavior without any hand-coded driving rules. We evaluate the performance of these policies in a closed-loop simulation and when deployed in a real-world advanced driver-assistance system.
Spiking GS: Towards High-Accuracy and Low-Cost Surface Reconstruction via Spiking Neuron-based Gaussian Splatting
Oct 09, 20243D Gaussian Splatting is capable of reconstructing 3D scenes in minutes. Despite recent advances in improving surface reconstruction accuracy, the reconstructed results still exhibit bias and suffer from inefficiency in storage and training. This paper provides a different observation on the cause of the inefficiency and the reconstruction bias, which is attributed to the integration of the low-opacity parts (LOPs) of the generated Gaussians. We show that LOPs consist of Gaussians with overall low-opacity (LOGs) and the low-opacity tails (LOTs) of Gaussians. We propose Spiking GS to reduce such two types of LOPs by integrating spiking neurons into the Gaussian Splatting pipeline. Specifically, we introduce global and local full-precision integrate-and-fire spiking neurons to the opacity and representation function of flattened 3D Gaussians, respectively. Furthermore, we enhance the density control strategy with spiking neurons' thresholds and an new criterion on the scale of Gaussians. Our method can represent more accurate reconstructed surfaces at a lower cost. The code is available at \url{https://github.com/shippoT/Spiking_GS}.