 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExamining the Behavior of LLM Architectures Within the Framework of Standardized National Exams in Brazil
Aug 09, 2024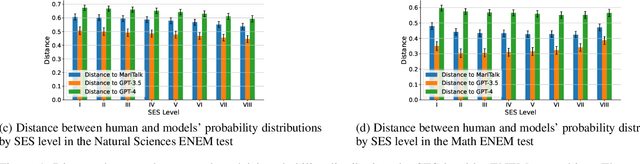
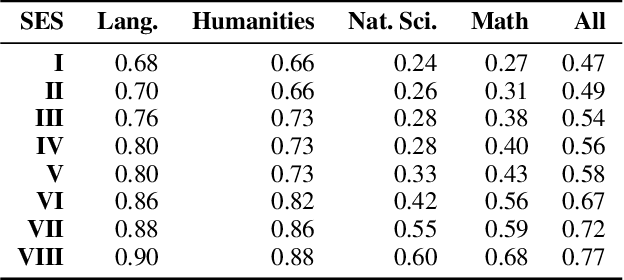


The Exame Nacional do Ensino M\'edio (ENEM) is a pivotal test for Brazilian students, required for admission to a significant number of universities in Brazil. The test consists of four objective high-school level tests on Math, Humanities, Natural Sciences and Languages, and one writing essay. Students' answers to the test and to the accompanying socioeconomic status questionnaire are made public every year (albeit anonymized) due to transparency policies from the Brazilian Government. In the context of large language models (LLMs), these data lend themselves nicely to comparing different groups of humans with AI, as we can have access to human and machine answer distributions. We leverage these characteristics of the ENEM dataset and compare GPT-3.5 and 4, and MariTalk, a model trained using Portuguese data, to humans, aiming to ascertain how their answers relate to real societal groups and what that may reveal about the model biases. We divide the human groups by using socioeconomic status (SES), and compare their answer distribution with LLMs for each question and for the essay. We find no significant biases when comparing LLM performance to humans on the multiple-choice Brazilian Portuguese tests, as the distance between model and human answers is mostly determined by the human accuracy. A similar conclusion is found by looking at the generated text as, when analyzing the essays, we observe that human and LLM essays differ in a few key factors, one being the choice of words where model essays were easily separable from human ones. The texts also differ syntactically, with LLM generated essays exhibiting, on average, smaller sentences and less thought units, among other differences. These results suggest that, for Brazilian Portuguese in the ENEM context, LLM outputs represent no group of humans, being significantly different from the answers from Brazilian students across all tests.
Automatic Diagnosis of the Short-Duration 12-Lead ECG using a Deep Neural Network: the CODE Study
Apr 02, 2019
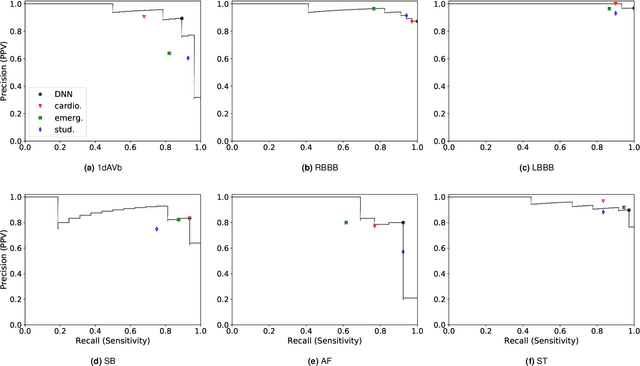

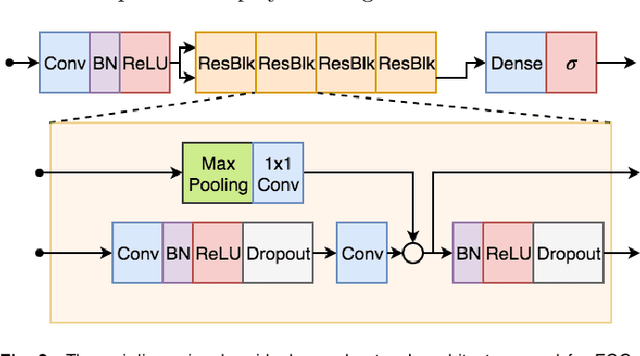
We present a Deep Neural Network (DNN) model for predicting electrocardiogram (ECG) abnormalities in short-duration 12-lead ECG recordings. The analysis of the digital ECG obtained in a clinical setting can provide a full evaluation of the cardiac electrical activity and have not been studied in an end-to-end machine learning scenario. Using the database of the Telehealth Network of Minas Gerais, under the scope of the CODE (Clinical Outcomes in Digital Electrocardiology) study, we built a novel dataset with more than 2 million ECG tracings, orders of magnitude larger than those used in previous studies. Moreover, our dataset is more realistic, as it consists of 12-lead ECGs recorded during standard in-clinic exams. Using this data, we trained a residual neural network with 9 convolutional layers to map ECG signals with a duration of 7 to 10 seconds into 6 different classes of ECG abnormalities. High-performance measures were obtained for all ECG abnormalities, with F1 scores above $80\%$ and specificity indexes over $99\%$. We compare the performance with cardiology and emergency resident medical doctors as well as medical students and, considering the F1 score, the DNN matches or outperforms the medical residents and students for all abnormalities. These results indicate that end-to-end automatic ECG analysis based on DNNs, previously used only in a single-lead setup, generalizes well to the 12-lead ECG. This is an important result in that it takes this technology much closer to standard clinical practice.
Automatic Diagnosis of Short-Duration 12-Lead ECG using a Deep Convolutional Network
Nov 28, 2018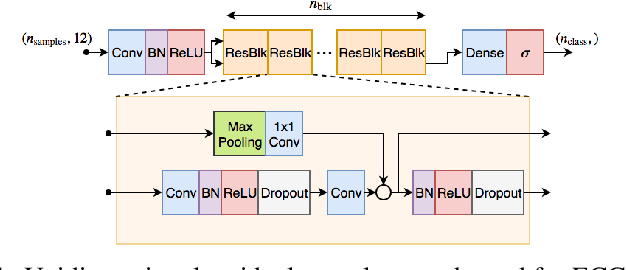
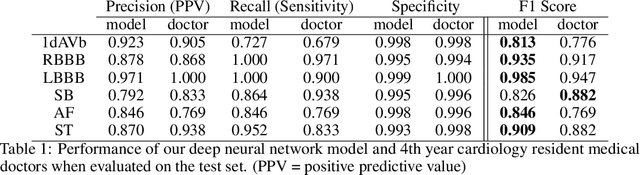
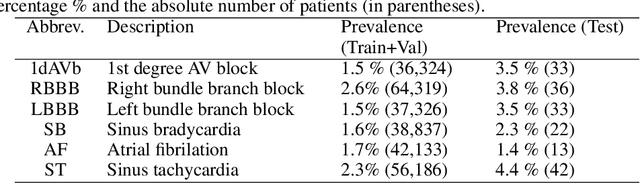
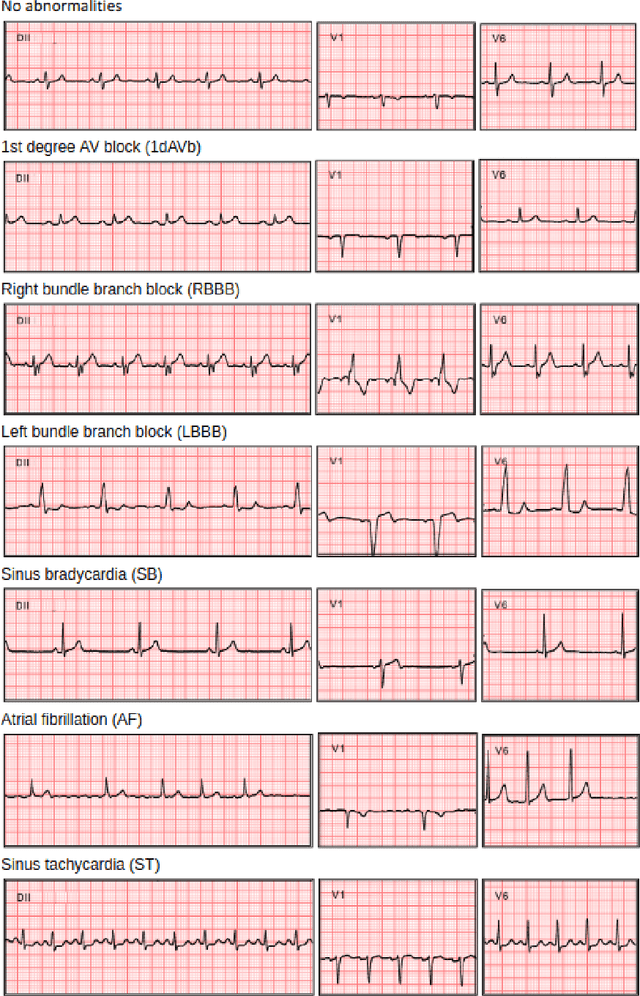
We present a model for predicting electrocardiogram (ECG) abnormalities in short-duration 12-lead ECG signals which outperformed medical doctors on the 4th year of their cardiology residency. Such exams can provide a full evaluation of heart activity and have not been studied in previous end-to-end machine learning papers. Using the database of a large telehealth network, we built a novel dataset with more than 2 million ECG tracings, orders of magnitude larger than those used in previous studies. Moreover, our dataset is more realistic, as it consist of 12-lead ECGs recorded during standard in-clinics exams. Using this data, we trained a residual neural network with 9 convolutional layers to map 7 to 10 second ECG signals to 6 classes of ECG abnormalities. Future work should extend these results to cover a large range of ECG abnormalities, which could improve the accessibility of this diagnostic tool and avoid wrong diagnosis from medical doctors.
Characterizing the public perception of WhatsApp through the lens of media
Aug 17, 2018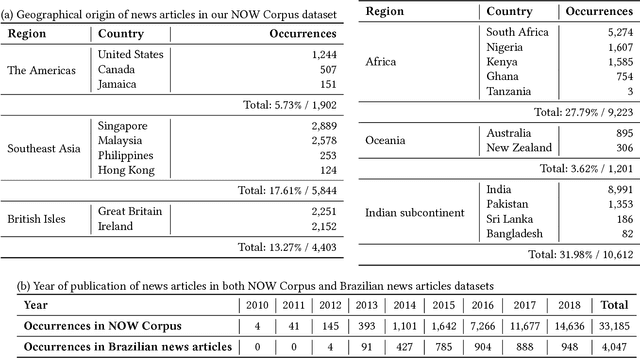
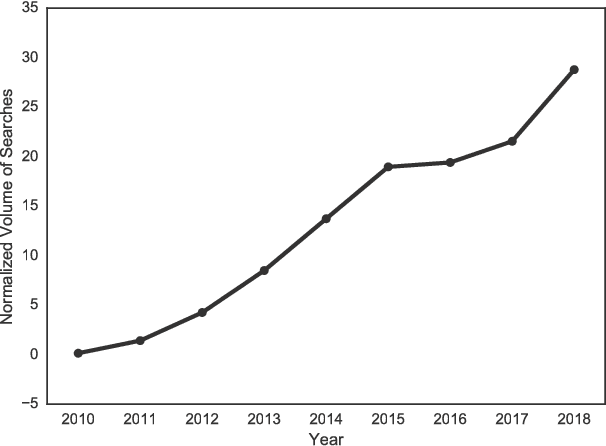
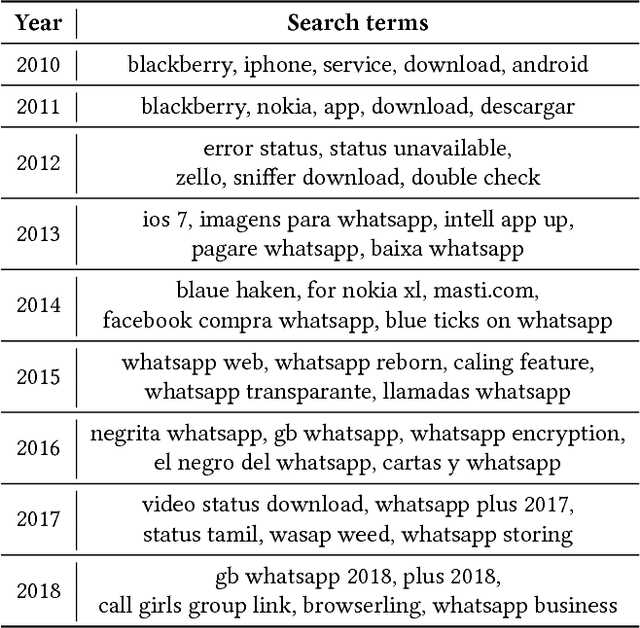
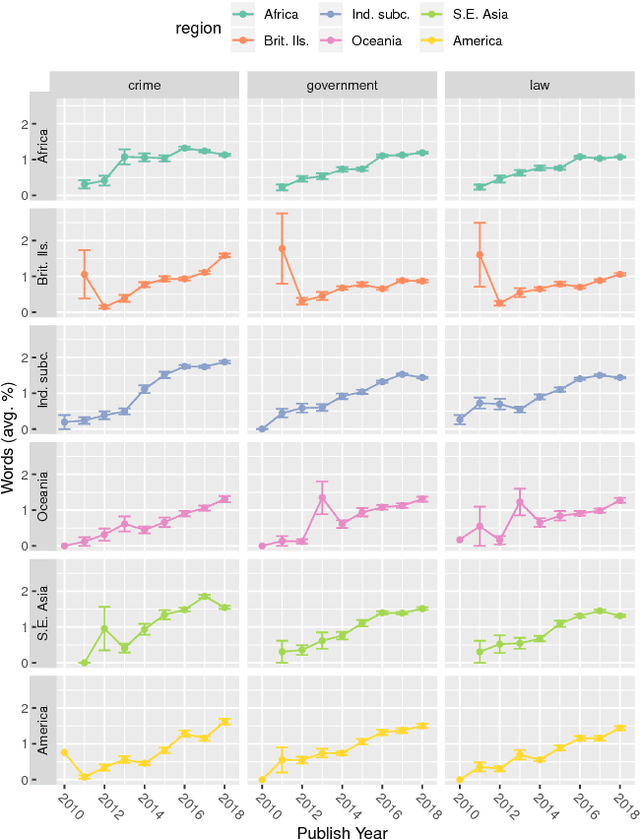
WhatsApp is, as of 2018, a significant component of the global information and communication infrastructure, especially in developing countries. However, probably due to its strong end-to-end encryption, WhatsApp became an attractive place for the dissemination of misinformation, extremism and other forms of undesirable behavior. In this paper, we investigate the public perception of WhatsApp through the lens of media. We analyze two large datasets of news and show the kind of content that is being associated with WhatsApp in different regions of the world and over time. Our analyses include the examination of named entities, general vocabulary, and topics addressed in news articles that mention WhatsApp, as well as the polarity of these texts. Among other results, we demonstrate that the vocabulary and topics around the term "whatsapp" in the media have been changing over the years and in 2018 concentrate on matters related to misinformation, politics and criminal scams. More generally, our findings are useful to understand the impact that tools like WhatsApp play in the contemporary society and how they are seen by the communities themselves.
Complexity-Aware Assignment of Latent Values in Discriminative Models for Accurate Gesture Recognition
Apr 01, 2017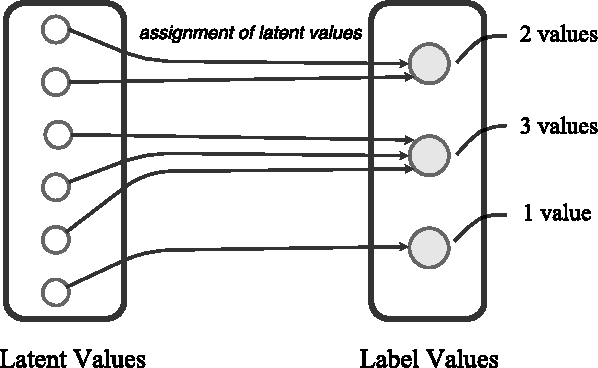
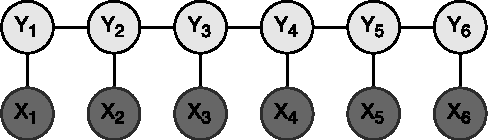
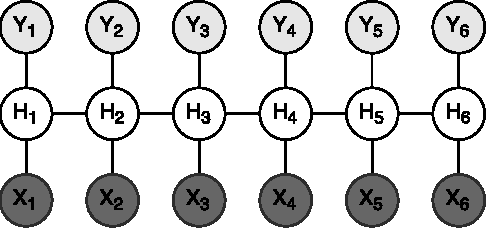
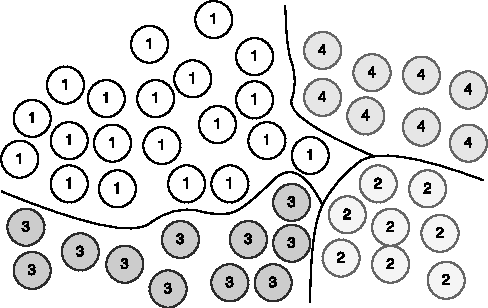
Many of the state-of-the-art algorithms for gesture recognition are based on Conditional Random Fields (CRFs). Successful approaches, such as the Latent-Dynamic CRFs, extend the CRF by incorporating latent variables, whose values are mapped to the values of the labels. In this paper we propose a novel methodology to set the latent values according to the gesture complexity. We use an heuristic that iterates through the samples associated with each label value, stimating their complexity. We then use it to assign the latent values to the label values. We evaluate our method on the task of recognizing human gestures from video streams. The experiments were performed in binary datasets, generated by grouping different labels. Our results demonstrate that our approach outperforms the arbitrary one in many cases, increasing the accuracy by up to 10%.