 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExamining the Behavior of LLM Architectures Within the Framework of Standardized National Exams in Brazil
Aug 09, 2024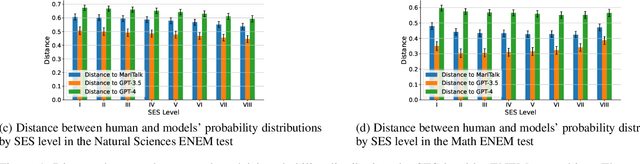
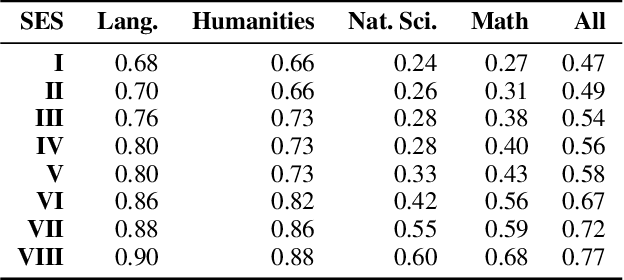


The Exame Nacional do Ensino M\'edio (ENEM) is a pivotal test for Brazilian students, required for admission to a significant number of universities in Brazil. The test consists of four objective high-school level tests on Math, Humanities, Natural Sciences and Languages, and one writing essay. Students' answers to the test and to the accompanying socioeconomic status questionnaire are made public every year (albeit anonymized) due to transparency policies from the Brazilian Government. In the context of large language models (LLMs), these data lend themselves nicely to comparing different groups of humans with AI, as we can have access to human and machine answer distributions. We leverage these characteristics of the ENEM dataset and compare GPT-3.5 and 4, and MariTalk, a model trained using Portuguese data, to humans, aiming to ascertain how their answers relate to real societal groups and what that may reveal about the model biases. We divide the human groups by using socioeconomic status (SES), and compare their answer distribution with LLMs for each question and for the essay. We find no significant biases when comparing LLM performance to humans on the multiple-choice Brazilian Portuguese tests, as the distance between model and human answers is mostly determined by the human accuracy. A similar conclusion is found by looking at the generated text as, when analyzing the essays, we observe that human and LLM essays differ in a few key factors, one being the choice of words where model essays were easily separable from human ones. The texts also differ syntactically, with LLM generated essays exhibiting, on average, smaller sentences and less thought units, among other differences. These results suggest that, for Brazilian Portuguese in the ENEM context, LLM outputs represent no group of humans, being significantly different from the answers from Brazilian students across all tests.
Characterizing the public perception of WhatsApp through the lens of media
Aug 17, 2018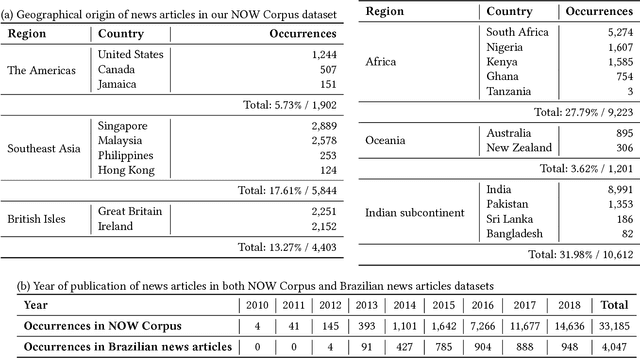
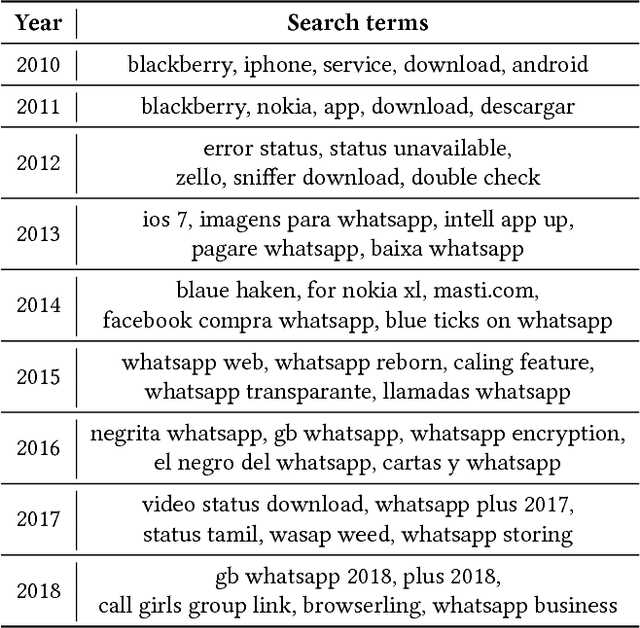
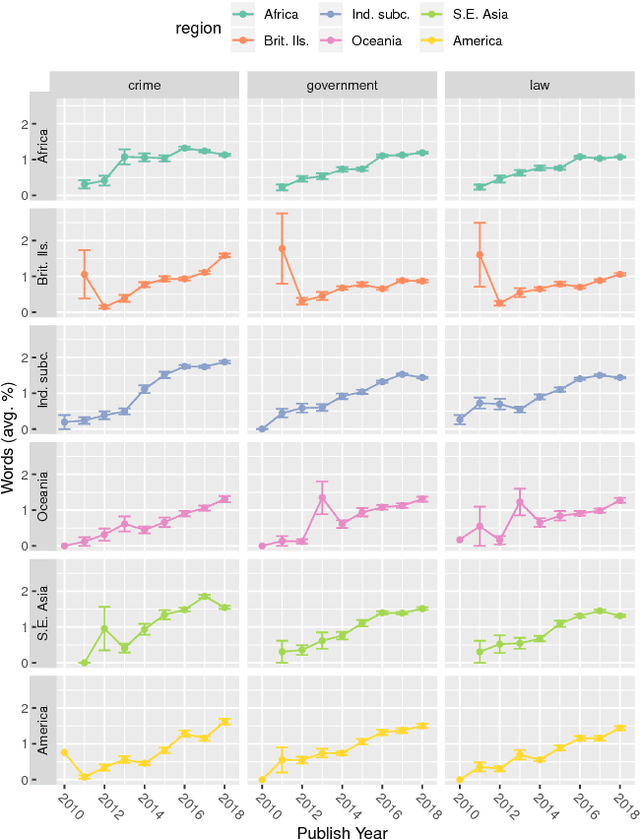
WhatsApp is, as of 2018, a significant component of the global information and communication infrastructure, especially in developing countries. However, probably due to its strong end-to-end encryption, WhatsApp became an attractive place for the dissemination of misinformation, extremism and other forms of undesirable behavior. In this paper, we investigate the public perception of WhatsApp through the lens of media. We analyze two large datasets of news and show the kind of content that is being associated with WhatsApp in different regions of the world and over time. Our analyses include the examination of named entities, general vocabulary, and topics addressed in news articles that mention WhatsApp, as well as the polarity of these texts. Among other results, we demonstrate that the vocabulary and topics around the term "whatsapp" in the media have been changing over the years and in 2018 concentrate on matters related to misinformation, politics and criminal scams. More generally, our findings are useful to understand the impact that tools like WhatsApp play in the contemporary society and how they are seen by the communities themselves.
Fake news as we feel it: perception and conceptualization of the term "fake news" in the media
Jul 18, 2018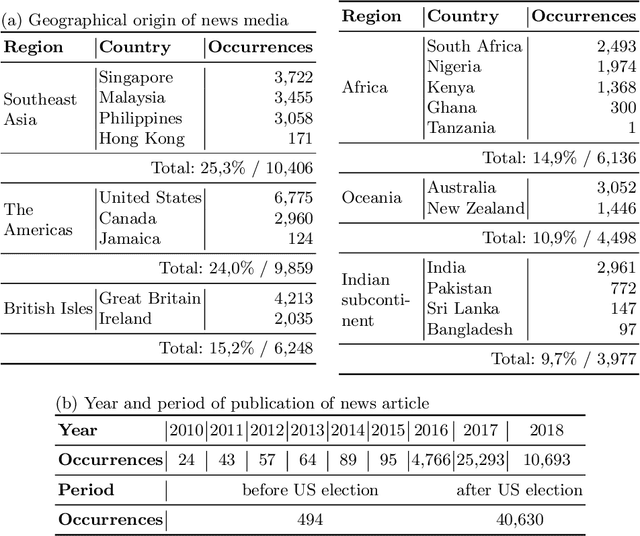
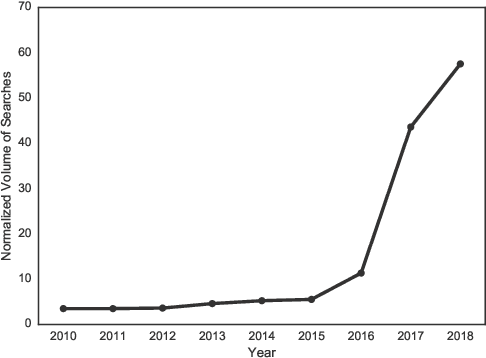
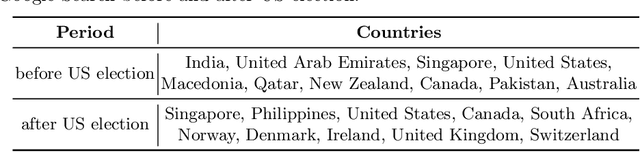

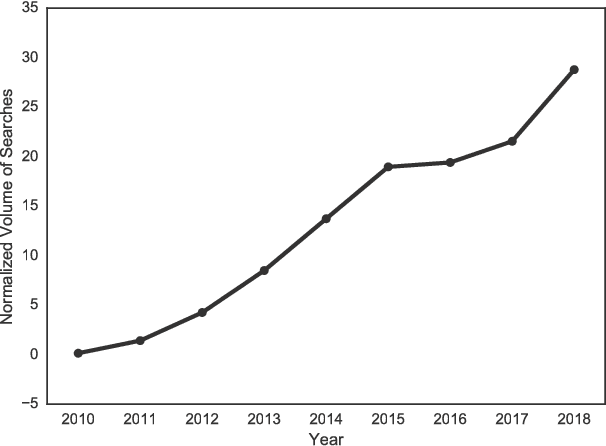
In this article, we quantitatively analyze how the term "fake news" is being shaped in news media in recent years. We study the perception and the conceptualization of this term in the traditional media using eight years of data collected from news outlets based in 20 countries. Our results not only corroborate previous indications of a high increase in the usage of the expression "fake news", but also show contextual changes around this expression after the United States presidential election of 2016. Among other results, we found changes in the related vocabulary, in the mentioned entities, in the surrounding topics and in the contextual polarity around the term "fake news", suggesting that this expression underwent a change in perception and conceptualization after 2016. These outcomes expand the understandings on the usage of the term "fake news", helping to comprehend and more accurately characterize this relevant social phenomenon linked to misinformation and manipulation.