 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoubly Adaptive Social Learning
Apr 24, 2025In social learning, a network of agents assigns probability scores (beliefs) to some hypotheses of interest, which rule the generation of local streaming data observed by each agent. Belief formation takes place by means of an iterative two-step procedure where: i) the agents update locally their beliefs by using some likelihood model; and ii) the updated beliefs are combined with the beliefs of the neighboring agents, using a pooling rule. This procedure can fail to perform well in the presence of dynamic drifts, leading the agents to incorrect decision making. Here, we focus on the fully online setting where both the true hypothesis and the likelihood models can change over time. We propose the doubly adaptive social learning ($\text{A}^2\text{SL}$) strategy, which infuses social learning with the necessary adaptation capabilities. This goal is achieved by exploiting two adaptation stages: i) a stochastic gradient descent update to learn and track the drifts in the decision model; ii) and an adaptive belief update to track the true hypothesis changing over time. These stages are controlled by two adaptation parameters that govern the evolution of the error probability for each agent. We show that all agents learn consistently for sufficiently small adaptation parameters, in the sense that they ultimately place all their belief mass on the true hypothesis. In particular, the probability of choosing the wrong hypothesis converges to values on the order of the adaptation parameters. The theoretical analysis is illustrated both on synthetic data and by applying the $\text{A}^2\text{SL}$ strategy to a social learning problem in the online setting using real data.
Non-Asymptotic Performance of Social Machine Learning Under Limited Data
Jun 15, 2023This paper studies the probability of error associated with the social machine learning framework, which involves an independent training phase followed by a cooperative decision-making phase over a graph. This framework addresses the problem of classifying a stream of unlabeled data in a distributed manner. We consider two kinds of classification tasks with limited observations in the prediction phase, namely, the statistical classification task and the single-sample classification task. For each task, we describe the distributed learning rule and analyze the probability of error accordingly. To do so, we first introduce a stronger consistent training condition that involves the margin distributions generated by the trained classifiers. Based on this condition, we derive an upper bound on the probability of error for both tasks, which depends on the statistical properties of the data and the combination policy used to combine the distributed classifiers. For the statistical classification problem, we employ the geometric social learning rule and conduct a non-asymptotic performance analysis. An exponential decay of the probability of error with respect to the number of unlabeled samples is observed in the upper bound. For the single-sample classification task, a distributed learning rule that functions as an ensemble classifier is constructed. An upper bound on the probability of error of this ensemble classifier is established.
Memory-Aware Social Learning under Partial Information Sharing
Jan 25, 2023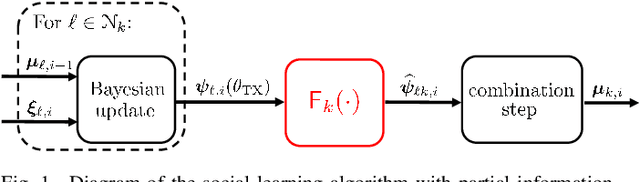
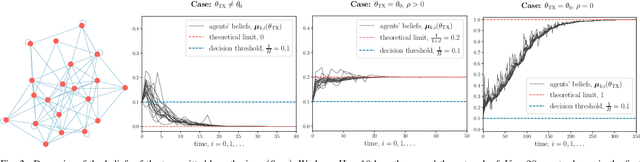
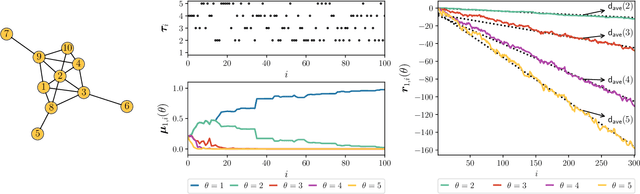
This work examines a social learning problem, where dispersed agents connected through a network topology interact locally to form their opinions (beliefs) as regards certain hypotheses of interest. These opinions evolve over time, since the agents collect observations from the environment, and update their current beliefs by accounting for: their past beliefs, the innovation contained in the new data, and the beliefs received from the neighbors. The distinguishing feature of the present work is that agents are constrained to share opinions regarding only a single hypothesis. We devise a novel learning strategy where each agent forms a valid belief by completing the partial beliefs received from its neighbors. This completion is performed by exploiting the knowledge accumulated in the past beliefs, thanks to a principled memory-aware rule inspired by a Bayesian criterion. The analysis allows us to characterize the role of memory in social learning under partial information sharing, revealing novel and nontrivial learning dynamics. Surprisingly, we establish that the standard classification rule based on selecting the maximum belief is not optimal under partial information sharing, while there exists a consistent threshold-based decision rule that allows each agent to classify correctly the hypothesis of interest. We also show that the proposed strategy outperforms previously considered schemes, highlighting that the introduction of memory in the social learning algorithm is critical to overcome the limitations arising from sharing partial information.
Distributed Bayesian Learning of Dynamic States
Dec 05, 2022



This work studies networked agents cooperating to track a dynamical state of nature under partial information. The proposed algorithm is a distributed Bayesian filtering algorithm for finite-state hidden Markov models (HMMs). It can be used for sequential state estimation tasks, as well as for modeling opinion formation over social networks under dynamic environments. We show that the disagreement with the optimal centralized solution is asymptotically bounded for the class of geometrically ergodic state transition models, which includes rapidly changing models. We also derive recursions for calculating the probability of error and establish convergence under Gaussian observation models. Simulations are provided to illustrate the theory and to compare against alternative approaches.
Dencentralized learning in the presence of low-rank noise
Mar 18, 2022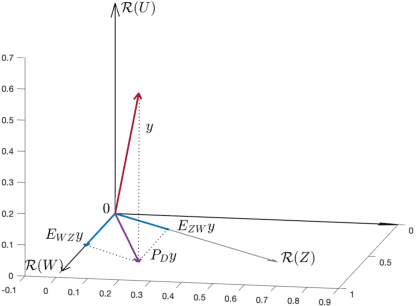
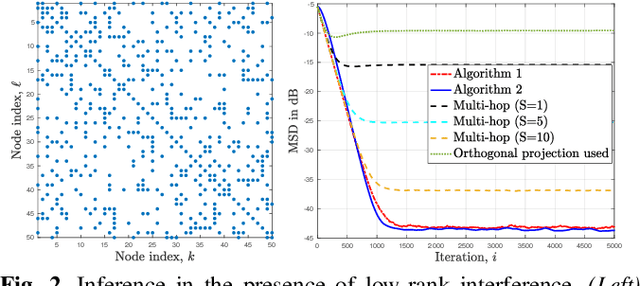
Observations collected by agents in a network may be unreliable due to observation noise or interference. This paper proposes a distributed algorithm that allows each node to improve the reliability of its own observation by relying solely on local computations and interactions with immediate neighbors, assuming that the field (graph signal) monitored by the network lies in a low-dimensional subspace and that a low-rank noise is present in addition to the usual full-rank noise. While oblique projections can be used to project measurements onto a low-rank subspace along a direction that is oblique to the subspace, the resulting solution is not distributed. Starting from the centralized solution, we propose an algorithm that performs the oblique projection of the overall set of observations onto the signal subspace in an iterative and distributed manner. We then show how the oblique projection framework can be extended to handle distributed learning and adaptation problems over networks.
Optimal Aggregation Strategies for Social Learning over Graphs
Mar 14, 2022
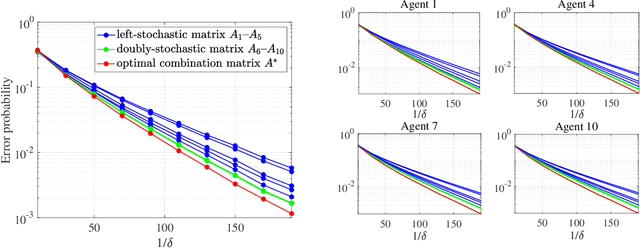

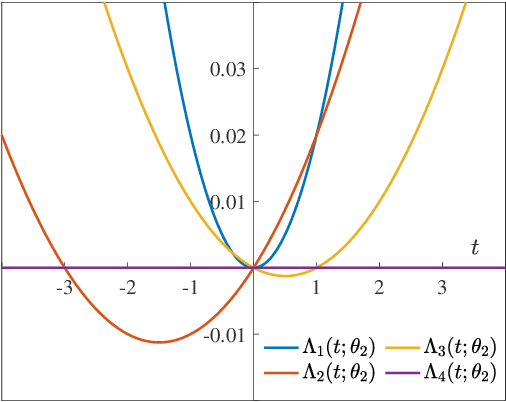
Adaptive social learning is a useful tool for studying distributed decision-making problems over graphs. This paper investigates the effect of combination policies on the performance of adaptive social learning strategies. Using large-deviation analysis, it first derives a bound on the probability of error and characterizes the optimal selection for the Perron eigenvectors of the combination policies. It subsequently studies the effect of the combination policy on the transient behavior of the learning strategy by estimating the adaptation time in the small signal-to-noise ratio regime. In the process, it is discovered that, interestingly, the influence of the combination policy on the transient behavior is insignificant, and thus it is more critical to employ policies that enhance the steady-state performance. The theoretical conclusions are illustrated by means of computer simulations.
Random Information Sharing over Social Networks
Mar 04, 2022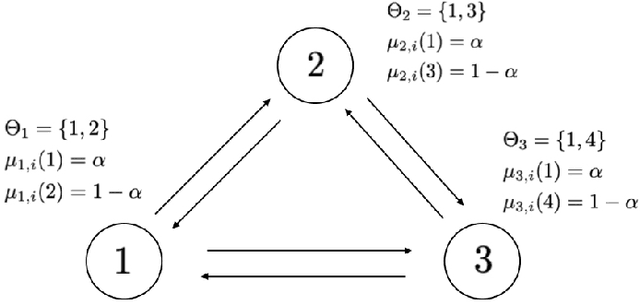
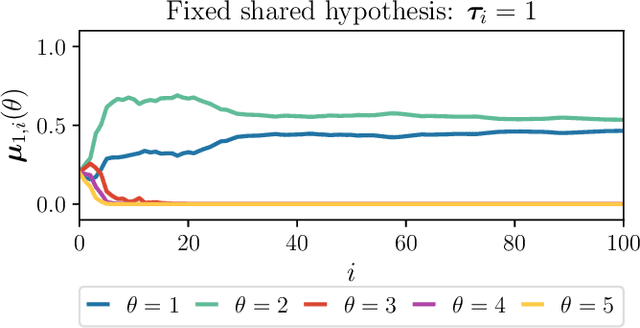

This work studies the learning process over social networks under partial and random information sharing. In traditional social learning, agents exchange full information with each other while trying to infer the true state of nature. We study the case where agents share information about only one hypothesis, i.e., the trending topic, which can be randomly changing at every iteration. We show that agents can learn the true hypothesis even if they do not discuss it, at rates comparable to traditional social learning. We also show that using one's own belief as a prior for estimating the neighbors' non-transmitted components might create opinion clusters that prevent learning with full confidence. This practice however avoids the complete rejection of the truth.
Learning from Heterogeneous Data Based on Social Interactions over Graphs
Dec 17, 2021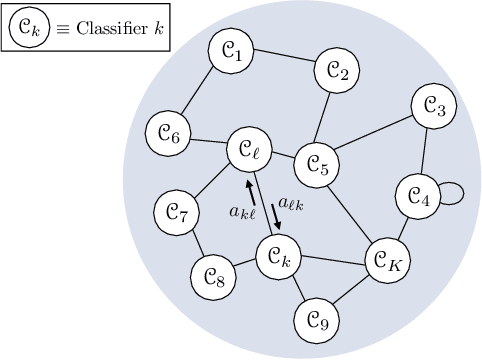
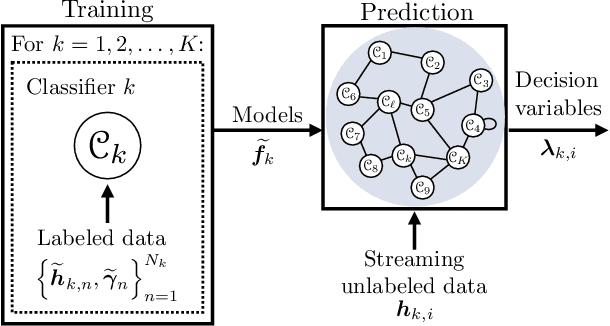
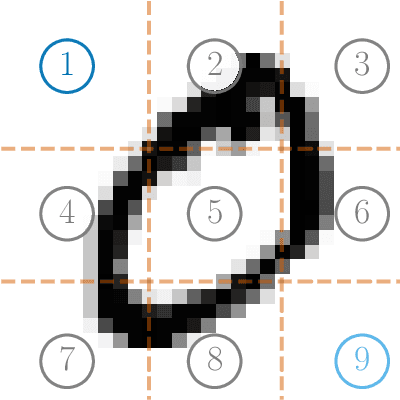
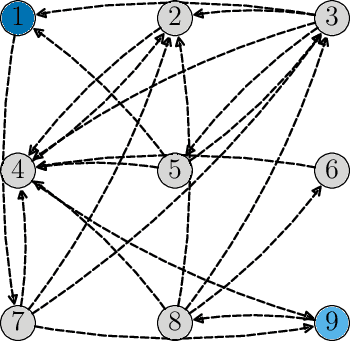
This work proposes a decentralized architecture, where individual agents aim at solving a classification problem while observing streaming features of different dimensions and arising from possibly different distributions. In the context of social learning, several useful strategies have been developed, which solve decision making problems through local cooperation across distributed agents and allow them to learn from streaming data. However, traditional social learning strategies rely on the fundamental assumption that each agent has significant prior knowledge of the underlying distribution of the observations. In this work we overcome this issue by introducing a machine learning framework that exploits social interactions over a graph, leading to a fully data-driven solution to the distributed classification problem. In the proposed social machine learning (SML) strategy, two phases are present: in the training phase, classifiers are independently trained to generate a belief over a set of hypotheses using a finite number of training samples; in the prediction phase, classifiers evaluate streaming unlabeled observations and share their instantaneous beliefs with neighboring classifiers. We show that the SML strategy enables the agents to learn consistently under this highly-heterogeneous setting and allows the network to continue learning even during the prediction phase when it is deciding on unlabeled samples. The prediction decisions are used to continually improve performance thereafter in a manner that is markedly different from most existing static classification schemes where, following training, the decisions on unlabeled data are not re-used to improve future performance.
Hidden Markov Modeling over Graphs
Nov 26, 2021
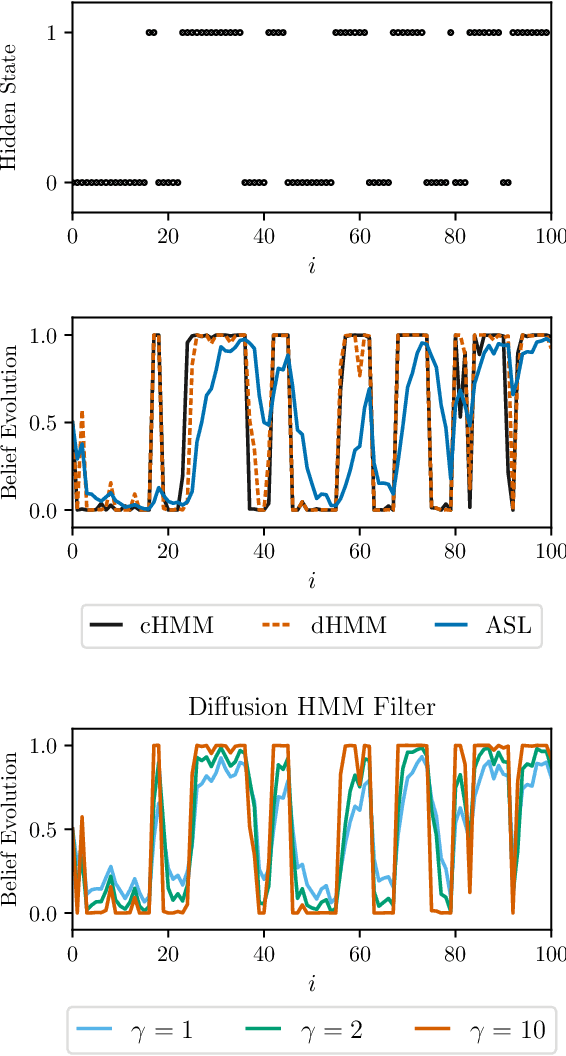
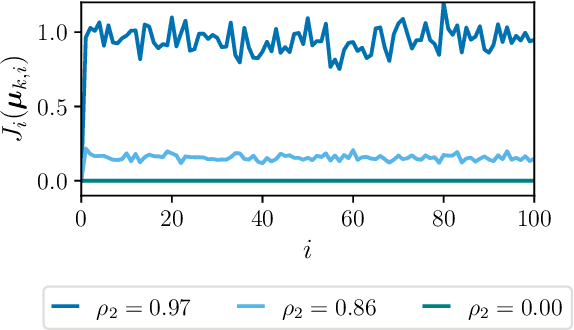
This work proposes a multi-agent filtering algorithm over graphs for finite-state hidden Markov models (HMMs), which can be used for sequential state estimation or for tracking opinion formation over dynamic social networks. We show that the difference from the optimal centralized Bayesian solution is asymptotically bounded for geometrically ergodic transition models. Experiments illustrate the theoretical findings and in particular, demonstrate the superior performance of the proposed algorithm compared to a state-of-the-art social learning algorithm.
Network Classifiers Based on Social Learning
Oct 23, 2020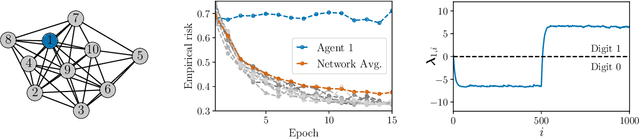
This work proposes a new way of combining independently trained classifiers over space and time. Combination over space means that the outputs of spatially distributed classifiers are aggregated. Combination over time means that the classifiers respond to streaming data during testing and continue to improve their performance even during this phase. By doing so, the proposed architecture is able to improve prediction performance over time with unlabeled data. Inspired by social learning algorithms, which require prior knowledge of the observations distribution, we propose a Social Machine Learning (SML) paradigm that is able to exploit the imperfect models generated during the learning phase. We show that this strategy results in consistent learning with high probability, and it yields a robust structure against poorly trained classifiers. Simulations with an ensemble of feedforward neural networks are provided to illustrate the theoretical results.