 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Aggregation Strategies for Social Learning over Graphs
Paper and Code
Mar 14, 2022
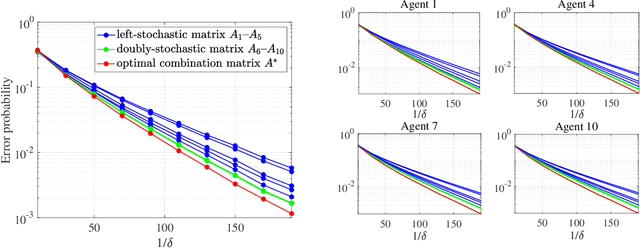

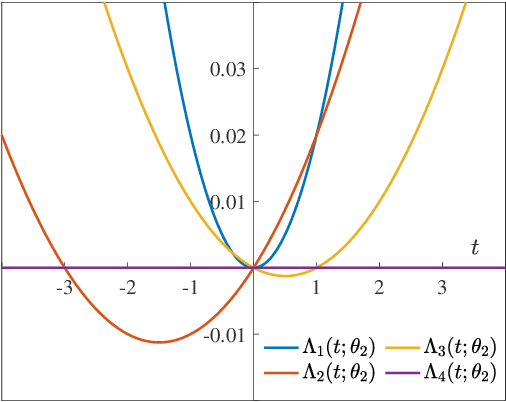
Adaptive social learning is a useful tool for studying distributed decision-making problems over graphs. This paper investigates the effect of combination policies on the performance of adaptive social learning strategies. Using large-deviation analysis, it first derives a bound on the probability of error and characterizes the optimal selection for the Perron eigenvectors of the combination policies. It subsequently studies the effect of the combination policy on the transient behavior of the learning strategy by estimating the adaptation time in the small signal-to-noise ratio regime. In the process, it is discovered that, interestingly, the influence of the combination policy on the transient behavior is insignificant, and thus it is more critical to employ policies that enhance the steady-state performance. The theoretical conclusions are illustrated by means of computer simulations.