 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTree Detection and Diameter Estimation Based on Deep Learning
Oct 31, 2022Tree perception is an essential building block toward autonomous forestry operations. Current developments generally consider input data from lidar sensors to solve forest navigation, tree detection and diameter estimation problems. Whereas cameras paired with deep learning algorithms usually address species classification or forest anomaly detection. In either of these cases, data unavailability and forest diversity restrain deep learning developments for autonomous systems. So, we propose two densely annotated image datasets - 43k synthetic, 100 real - for bounding box, segmentation mask and keypoint detections to assess the potential of vision-based methods. Deep neural network models trained on our datasets achieve a precision of 90.4% for tree detection, 87.2% for tree segmentation, and centimeter accurate keypoint estimations. We measure our models' generalizability when testing it on other forest datasets, and their scalability with different dataset sizes and architectural improvements. Overall, the experimental results offer promising avenues toward autonomous tree felling operations and other applied forestry problems. The datasets and pre-trained models in this article are publicly available on \href{https://github.com/norlab-ulaval/PercepTreeV1}{GitHub} (https://github.com/norlab-ulaval/PercepTreeV1).
Training Deep Learning Algorithms on Synthetic Forest Images for Tree Detection
Oct 08, 2022

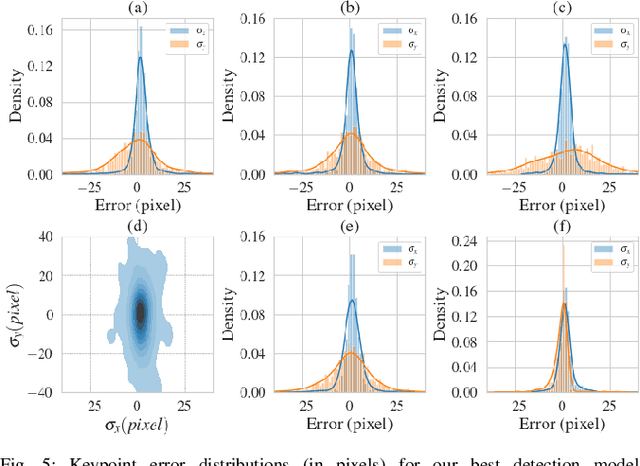
Vision-based segmentation in forested environments is a key functionality for autonomous forestry operations such as tree felling and forwarding. Deep learning algorithms demonstrate promising results to perform visual tasks such as object detection. However, the supervised learning process of these algorithms requires annotations from a large diversity of images. In this work, we propose to use simulated forest environments to automatically generate 43 k realistic synthetic images with pixel-level annotations, and use it to train deep learning algorithms for tree detection. This allows us to address the following questions: i) what kind of performance should we expect from deep learning in harsh synthetic forest environments, ii) which annotations are the most important for training, and iii) what modality should be used between RGB and depth. We also report the promising transfer learning capability of features learned on our synthetic dataset by directly predicting bounding box, segmentation masks and keypoints on real images. Code available on GitHub (https://github.com/norlab-ulaval/PercepTreeV1).
Instance Segmentation for Autonomous Log Grasping in Forestry Operations
Mar 03, 2022

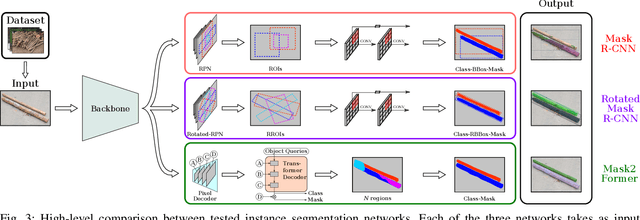

Wood logs picking is a challenging task to automate. Indeed, logs usually come in cluttered configurations, randomly orientated and overlapping. Recent work on log picking automation usually assume that the logs' pose is known, with little consideration given to the actual perception problem. In this paper, we squarely address the latter, using a data-driven approach. First, we introduce a novel dataset, named TimberSeg 1.0, that is densely annotated, i.e., that includes both bounding boxes and pixel-level mask annotations for logs. This dataset comprises 220 images with 2500 individually segmented logs. Using our dataset, we then compare three neural network architectures on the task of individual logs detection and segmentation; two region-based methods and one attention-based method. Unsurprisingly, our results show that axis-aligned proposals, failing to take into account the directional nature of logs, underperform with 19.03 mAP. A rotation-aware proposal method significantly improve results to 31.83 mAP. More interestingly, a Transformer-based approach, without any inductive bias on rotations, outperformed the two others, achieving a mAP of 57.53 on our dataset. Our use case demonstrates the limitations of region-based approaches for cluttered, elongated objects. It also highlights the potential of attention-based methods on this specific task, as they work directly at the pixel-level. These encouraging results indicate that such a perception system could be used to assist the operators on the short-term, or to fully automate log picking operations in the future.
Evaluation of Skid-Steering Kinematic Models for Subarctic Environments
Apr 10, 2020
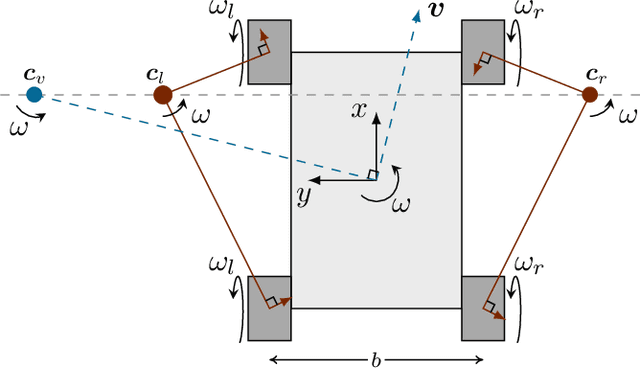

In subarctic and arctic areas, large and heavy skid-steered robots are preferred for their robustness and ability to operate on difficult terrain. State estimation, motion control and path planning for these robots rely on accurate odometry models based on wheel velocities. However, the state-of-the-art odometry models for skid-steer mobile robots (SSMRs) have usually been tested on relatively lightweight platforms. In this paper, we focus on how these models perform when deployed on a large and heavy (590 kg) SSMR. We collected more than 2 km of data on both snow and concrete. We compare the ideal differential-drive, extended differential-drive, radius-of-curvature-based, and full linear kinematic models commonly deployed for SSMRs. Each of the models is fine-tuned by searching their optimal parameters on both snow and concrete. We then discuss the relationship between the parameters, the model tuning, and the final accuracy of the models.