 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Clinical Question Answering Systems Really Need Specialised Medical Fine Tuning?
Jan 19, 2026Clinical Question-Answering (CQA) industry systems are increasingly rely on Large Language Models (LLMs), yet their deployment is often guided by the assumption that domain-specific fine-tuning is essential. Although specialised medical LLMs such as BioBERT, BioGPT, and PubMedBERT remain popular, they face practical limitations including narrow coverage, high retraining costs, and limited adaptability. Efforts based on Supervised Fine-Tuning (SFT) have attempted to address these assumptions but continue to reinforce what we term the SPECIALISATION FALLACY-the belief that specialised medical LLMs are inherently superior for CQA. To address this assumption, we introduce MEDASSESS-X, a deployment-industry-oriented CQA framework that applies alignment at inference time rather than through SFT. MEDASSESS-X uses lightweight steering vectors to guide model activations toward medically consistent reasoning without updating model weights or requiring domain-specific retraining. This inference-time alignment layer stabilises CQA performance across both general-purpose and specialised medical LLMs, thereby resolving the SPECIALISATION FALLACY. Empirically, MEDASSESS-X delivers consistent gains across all LLM families, improving Accuracy by up to +6%, Factual Consistency by +7%, and reducing Safety Error Rate by as much as 50%.
MAGIC-Enhanced Keyword Prompting for Zero-Shot Audio Captioning with CLIP Models
Sep 16, 2025Automated Audio Captioning (AAC) generates captions for audio clips but faces challenges due to limited datasets compared to image captioning. To overcome this, we propose the zero-shot AAC system that leverages pre-trained models, eliminating the need for extensive training. Our approach uses a pre-trained audio CLIP model to extract auditory features and generate a structured prompt, which guides a Large Language Model (LLM) in caption generation. Unlike traditional greedy decoding, our method refines token selection through the audio CLIP model, ensuring alignment with the audio content. Experimental results demonstrate a 35% improvement in NLG mean score (from 4.7 to 7.3) using MAGIC search with the WavCaps model. The performance is heavily influenced by the audio-text matching model and keyword selection, with optimal results achieved using a single keyword prompt, and a 50% performance drop when no keyword list is used.
Stochastic MPC with Multi-modal Predictions for Traffic Intersections
Sep 26, 2021
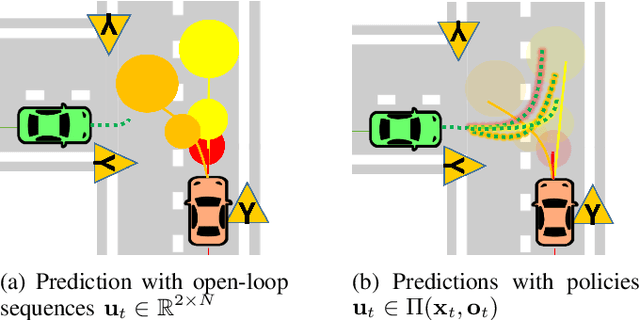
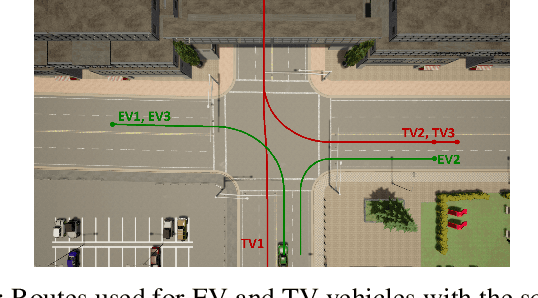
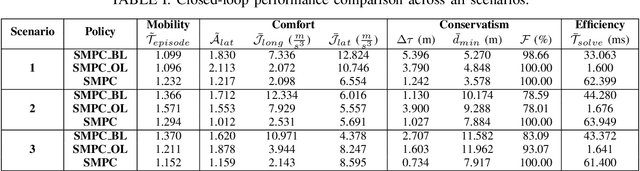
We propose a Stochastic MPC (SMPC) formulation for autonomous driving at traffic intersections which incorporates multi-modal predictions of surrounding vehicles for collision avoidance constraints. The multi-modal predictions are obtained with Gaussian Mixture Models (GMM) and constraints are formulated as chance-constraints. Our main theoretical contribution is a SMPC formulation that optimizes over a novel feedback policy class designed to exploit additional structure in the GMM predictions, and that is amenable to convex programming. The use of feedback policies for prediction is motivated by the need for reduced conservatism in handling multi-modal predictions of the surrounding vehicles, especially prevalent in traffic intersection scenarios. We evaluate our algorithm along axes of mobility, comfort, conservatism and computational efficiency at a simulated intersection in CARLA. Our simulations use a kinematic bicycle model and multimodal predictions trained on a subset of the Lyft Level 5 prediction dataset. To demonstrate the impact of optimizing over feedback policies, we compare our algorithm with two SMPC baselines that handle multi-modal collision avoidance chance constraints by optimizing over open-loop sequences.
ParkPredict: Motion and Intent Prediction of Vehicles in Parking Lots
Apr 21, 2020
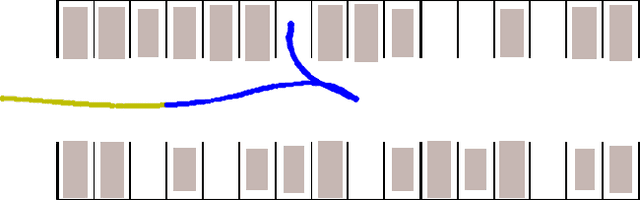
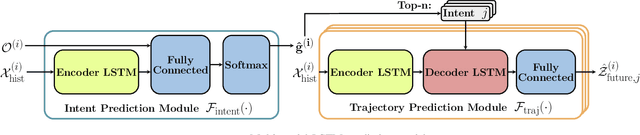
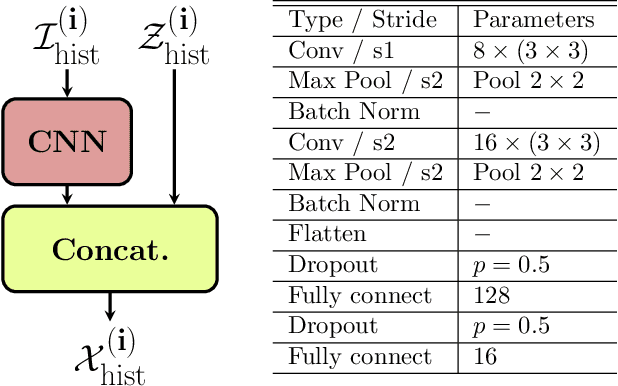
We investigate the problem of predicting driver behavior in parking lots, an environment which is less structured than typical road networks and features complex, interactive maneuvers in a compact space. Using the CARLA simulator, we develop a parking lot environment and collect a dataset of human parking maneuvers. We then study the impact of model complexity and feature information by comparing a multi-modal Long Short-Term Memory (LSTM) prediction model and a Convolution Neural Network LSTM (CNN-LSTM) to a physics-based Extended Kalman Filter (EKF) baseline. Our results show that 1) intent can be estimated well (roughly 85% top-1 accuracy and nearly 100% top-3 accuracy with the LSTM and CNN-LSTM model); 2) knowledge of the human driver's intended parking spot has a major impact on predicting parking trajectory; and 3) the semantic representation of the environment improves long term predictions.
A Hybrid Control Design for Autonomous Vehicles at Uncontrolled Intersections
Feb 02, 2019
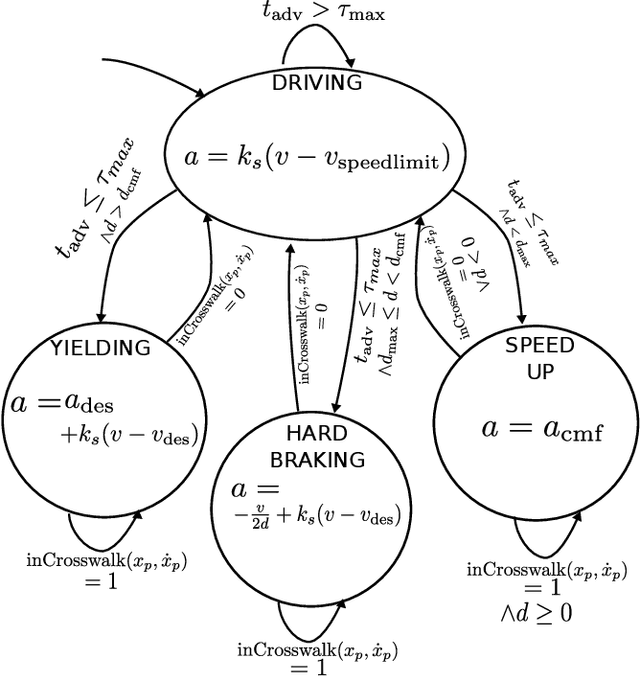
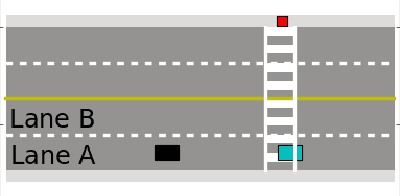

As autonomous vehicles (AVs) inch closer to reality, a central requirement for acceptance will be earning the trust of humans in everyday driving situations. In particular, the interaction between AVs and pedestrians is of high importance, as every human is a pedestrian at some point of the day. This paper considers the interaction of a pedestrian and an autonomous vehicle at a mid-block, unsignalized intersection where there is ambiguity over when the pedestrian should cross and when and how the vehicle should yield. By modeling pedestrian behavior through the concept of gap acceptance, the authors show that a hybrid controller with just four distinct modes allows an autonomous vehicle to successfully interact with a pedestrian across a continuous spectrum of possible crosswalk entry behaviors. The controller is validated through extensive simulation and compared to an alternate POMDP solution and experimental results are provided on a research vehicle for a virtual pedestrian.