 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaCliP: Adaptive Clipping for Private SGD
Aug 20, 2019
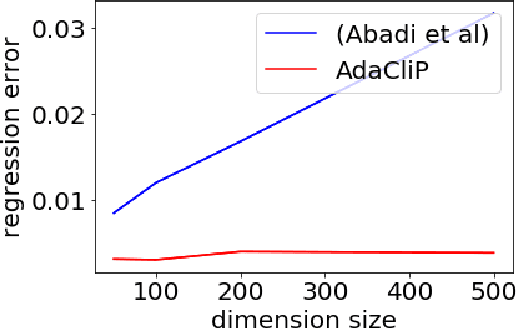
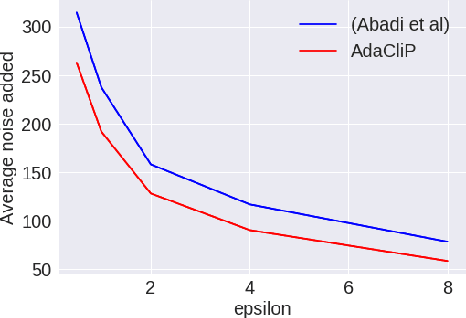

Privacy preserving machine learning algorithms are crucial for learning models over user data to protect sensitive information. Motivated by this, differentially private stochastic gradient descent (SGD) algorithms for training machine learning models have been proposed. At each step, these algorithms modify the gradients and add noise proportional to the sensitivity of the modified gradients. Under this framework, we propose AdaCliP, a theoretically motivated differentially private SGD algorithm that provably adds less noise compared to the previous methods, by using coordinate-wise adaptive clipping of the gradient. We empirically demonstrate that AdaCliP reduces the amount of added noise and produces models with better accuracy.
On Learning Markov Chains
Oct 28, 2018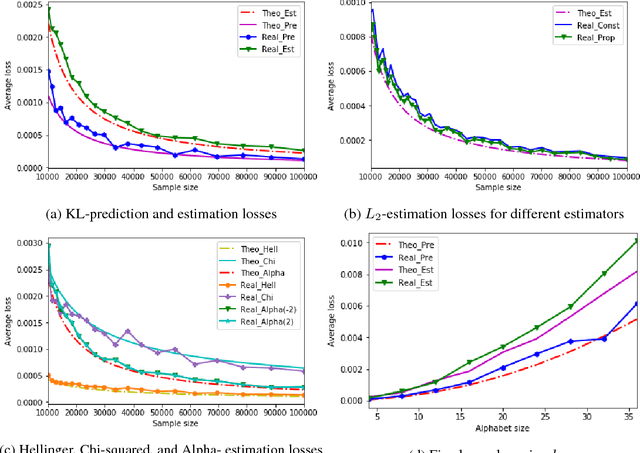
The problem of estimating an unknown discrete distribution from its samples is a fundamental tenet of statistical learning. Over the past decade, it attracted significant research effort and has been solved for a variety of divergence measures. Surprisingly, an equally important problem, estimating an unknown Markov chain from its samples, is still far from understood. We consider two problems related to the min-max risk (expected loss) of estimating an unknown $k$-state Markov chain from its $n$ sequential samples: predicting the conditional distribution of the next sample with respect to the KL-divergence, and estimating the transition matrix with respect to a natural loss induced by KL or a more general $f$-divergence measure. For the first measure, we determine the min-max prediction risk to within a linear factor in the alphabet size, showing it is $\Omega(k\log\log n\ / n)$ and $\mathcal{O}(k^2\log\log n\ / n)$. For the second, if the transition probabilities can be arbitrarily small, then only trivial uniform risk upper bounds can be derived. We therefore consider transition probabilities that are bounded away from zero, and resolve the problem for essentially all sufficiently smooth $f$-divergences, including KL-, $L_2$-, Chi-squared, Hellinger, and Alpha-divergences.
Maximum Selection and Ranking under Noisy Comparisons
May 15, 2017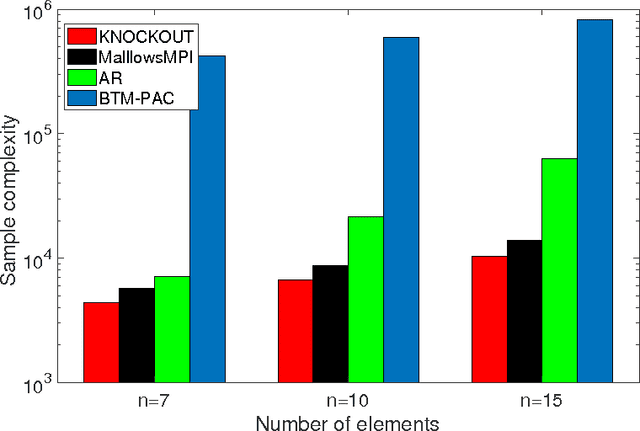
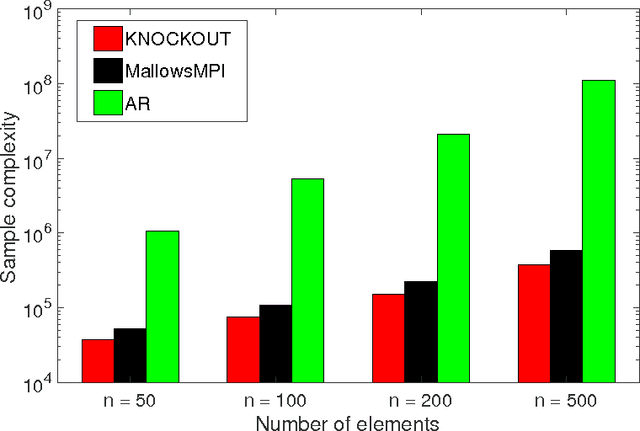
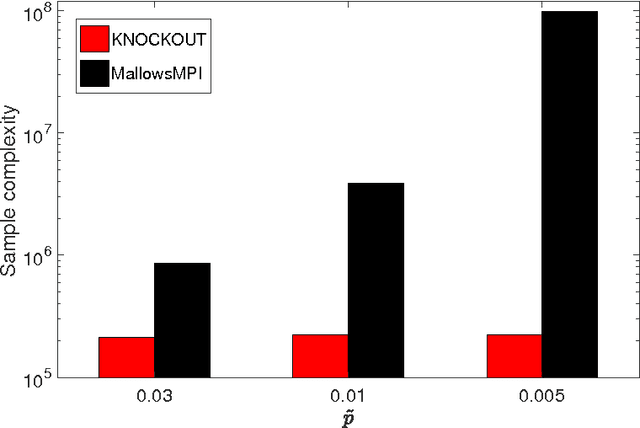
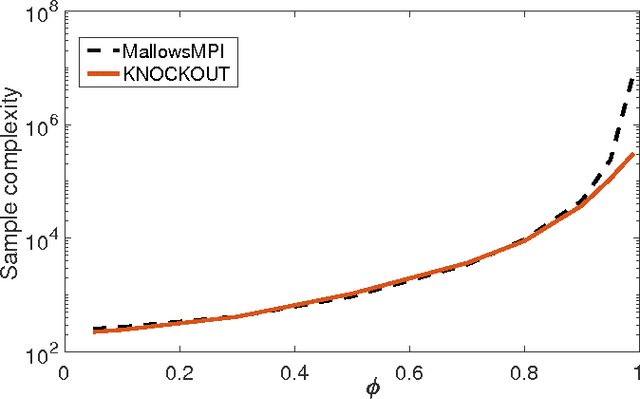
We consider $(\epsilon,\delta)$-PAC maximum-selection and ranking for general probabilistic models whose comparisons probabilities satisfy strong stochastic transitivity and stochastic triangle inequality. Modifying the popular knockout tournament, we propose a maximum-selection algorithm that uses $\mathcal{O}\left(\frac{n}{\epsilon^2}\log \frac{1}{\delta}\right)$ comparisons, a number tight up to a constant factor. We then derive a general framework that improves the performance of many ranking algorithms, and combine it with merge sort and binary search to obtain a ranking algorithm that uses $\mathcal{O}\left(\frac{n\log n (\log \log n)^3}{\epsilon^2}\right)$ comparisons for any $\delta\ge\frac1n$, a number optimal up to a $(\log \log n)^3$ factor.