 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDrIFT: Autonomous Drone Dataset with Integrated Real and Synthetic Data, Flexible Views, and Transformed Domains
Dec 06, 2024


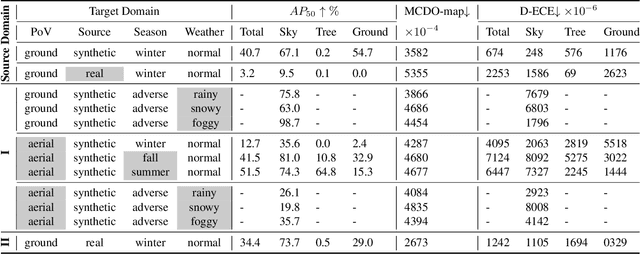
Dependable visual drone detection is crucial for the secure integration of drones into the airspace. However, drone detection accuracy is significantly affected by domain shifts due to environmental changes, varied points of view, and background shifts. To address these challenges, we present the DrIFT dataset, specifically developed for visual drone detection under domain shifts. DrIFT includes fourteen distinct domains, each characterized by shifts in point of view, synthetic-to-real data, season, and adverse weather. DrIFT uniquely emphasizes background shift by providing background segmentation maps to enable background-wise metrics and evaluation. Our new uncertainty estimation metric, MCDO-map, features lower postprocessing complexity, surpassing traditional methods. We use the MCDO-map in our uncertainty-aware unsupervised domain adaptation method, demonstrating superior performance to SOTA unsupervised domain adaptation techniques. The dataset is available at: https://github.com/CARG-uOttawa/DrIFT.git.
An Intent Modeling and Inference Framework for Autonomous and Remotely Piloted Aerial Systems
Sep 13, 2024An intent modelling and inference framework is presented to assist the defense planning for protecting a geo-fence against unauthorized flights. First, a novel mathematical definition for the intent of an uncrewed aircraft system (UAS) is presented. The concepts of critical waypoints and critical waypoint patterns are introduced and associated with a motion process to fully characterize an intent. This modelling framework consists of representations of a UAS mission planner, used to plan the aircraft's motion sequence, as well as a defense planner, defined to protect the geo-fence. It is applicable to autonomous, semi-autonomous, and piloted systems in 2D and 3D environments with obstacles. The framework is illustrated by defining a library of intents for a security application. Detection and tracking of the target are presumed for formulating the intent inference problem. Multiple formulations of the decision maker's objective are discussed as part of a deep-learning-based methodology. Further, a multi-modal dynamic model for characterizing the UAS flight is discussed. This is later utilized to extract features using the interacting multiple model (IMM) filter for training the intent classifier. Finally, as part of the simulation study, an attention-based bi-directional long short-term memory (Bi-LSTM) network for intent inference is presented. The simulation experiments illustrate various aspects of the framework, including trajectory generation, radar measurement simulation, etc., in 2D and 3D environments.
Sequential Decision Making under Uncertainty with Dynamic Resource Constraints
Apr 18, 2019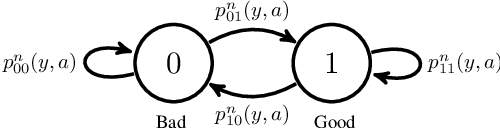
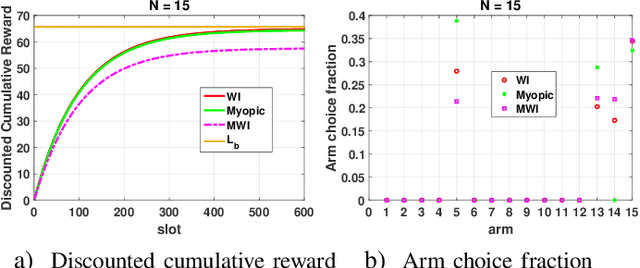
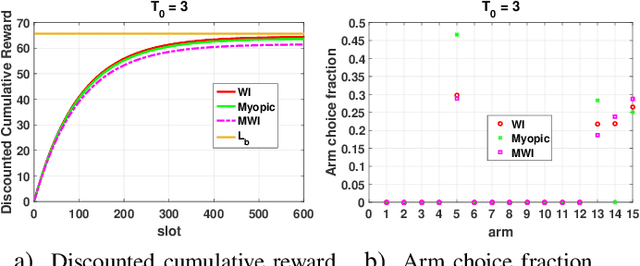
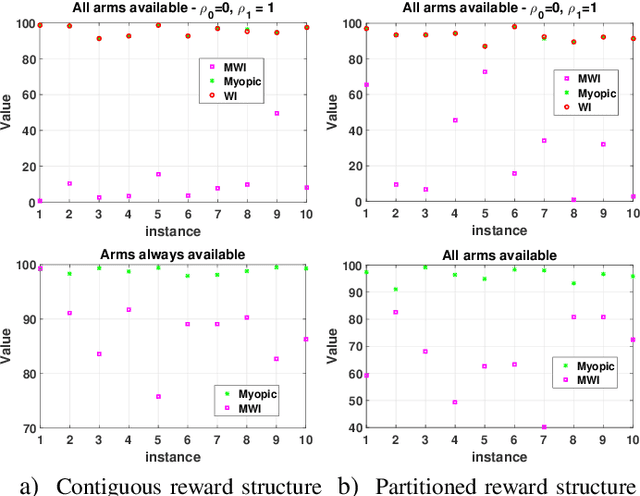
This paper studies a class of constrained restless multi-armed bandits. The constraints are in the form of time varying availability of arms. This variation can be either stochastic or semi-deterministic. A fixed number of arms can be chosen to be played in each decision interval. The play of each arm yields a state dependent reward. The current states of arms are partially observable through binary feedback signals from arms that are played. The current availability of arms is fully observable. The objective is to maximize long term cumulative reward. The uncertainty about future availability of arms along with partial state information makes this objective challenging. This optimization problem is analyzed using Whittle's index policy. To this end, a constrained restless single-armed bandit is studied. It is shown to admit a threshold-type optimal policy, and is also indexable. An algorithm to compute Whittle's index is presented. Further, upper bounds on the value function are derived in order to estimate the degree of sub-optimality of various solutions. The simulation study compares the performance of Whittle's index, modified Whittle's index and myopic policies.