 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDrIFT: Autonomous Drone Dataset with Integrated Real and Synthetic Data, Flexible Views, and Transformed Domains
Dec 06, 2024


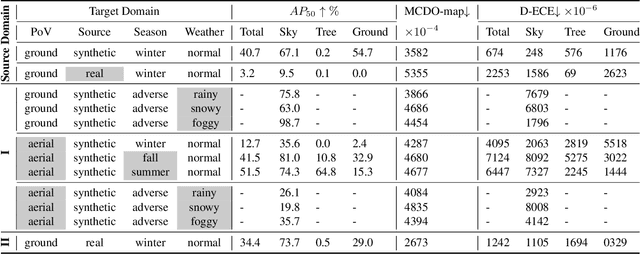
Dependable visual drone detection is crucial for the secure integration of drones into the airspace. However, drone detection accuracy is significantly affected by domain shifts due to environmental changes, varied points of view, and background shifts. To address these challenges, we present the DrIFT dataset, specifically developed for visual drone detection under domain shifts. DrIFT includes fourteen distinct domains, each characterized by shifts in point of view, synthetic-to-real data, season, and adverse weather. DrIFT uniquely emphasizes background shift by providing background segmentation maps to enable background-wise metrics and evaluation. Our new uncertainty estimation metric, MCDO-map, features lower postprocessing complexity, surpassing traditional methods. We use the MCDO-map in our uncertainty-aware unsupervised domain adaptation method, demonstrating superior performance to SOTA unsupervised domain adaptation techniques. The dataset is available at: https://github.com/CARG-uOttawa/DrIFT.git.
Object Semantics Give Us the Depth We Need: Multi-task Approach to Aerial Depth Completion
Apr 25, 2023Depth completion and object detection are two crucial tasks often used for aerial 3D mapping, path planning, and collision avoidance of Uncrewed Aerial Vehicles (UAVs). Common solutions include using measurements from a LiDAR sensor; however, the generated point cloud is often sparse and irregular and limits the system's capabilities in 3D rendering and safety-critical decision-making. To mitigate this challenge, information from other sensors on the UAV (viz., a camera used for object detection) is utilized to help the depth completion process generate denser 3D models. Performing both aerial depth completion and object detection tasks while fusing the data from the two sensors poses a challenge to resource efficiency. We address this challenge by proposing a novel approach to jointly execute the two tasks in a single pass. The proposed method is based on an encoder-focused multi-task learning model that exposes the two tasks to jointly learned features. We demonstrate how semantic expectations of the objects in the scene learned by the object detection pathway can boost the performance of the depth completion pathway while placing the missing depth values. Experimental results show that the proposed multi-task network outperforms its single-task counterpart, particularly when exposed to defective inputs.