 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegCLR: A Self-Supervised Framework for Tabular Representation Learning in the Wild
Nov 02, 2022Recent advances in self-supervised learning (SSL) using large models to learn visual representations from natural images are rapidly closing the gap between the results produced by fully supervised learning and those produced by SSL on downstream vision tasks. Inspired by this advancement and primarily motivated by the emergence of tabular and structured document image applications, we investigate which self-supervised pretraining objectives, architectures, and fine-tuning strategies are most effective. To address these questions, we introduce RegCLR, a new self-supervised framework that combines contrastive and regularized methods and is compatible with the standard Vision Transformer architecture. Then, RegCLR is instantiated by integrating masked autoencoders as a representative example of a contrastive method and enhanced Barlow Twins as a representative example of a regularized method with configurable input image augmentations in both branches. Several real-world table recognition scenarios (e.g., extracting tables from document images), ranging from standard Word and Latex documents to even more challenging electronic health records (EHR) computer screen images, have been shown to benefit greatly from the representations learned from this new framework, with detection average-precision (AP) improving relatively by 4.8% for Table, 11.8% for Column, and 11.1% for GUI objects over a previous fully supervised baseline on real-world EHR screen images.
Can Current Explainability Help Provide References in Clinical Notes to Support Humans Annotate Medical Codes?
Oct 28, 2022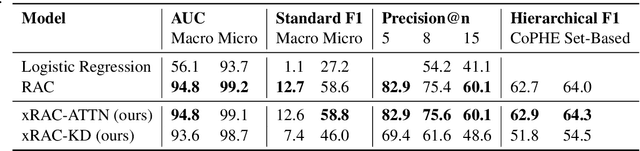


The medical codes prediction problem from clinical notes has received substantial interest in the NLP community, and several recent studies have shown the state-of-the-art (SOTA) code prediction results of full-fledged deep learning-based methods. However, most previous SOTA works based on deep learning are still in early stages in terms of providing textual references and explanations of the predicted codes, despite the fact that this level of explainability of the prediction outcomes is critical to gaining trust from professional medical coders. This raises the important question of how well current explainability methods apply to advanced neural network models such as transformers to predict correct codes and present references in clinical notes that support code prediction. First, we present an explainable Read, Attend, and Code (xRAC) framework and assess two approaches, attention score-based xRAC-ATTN and model-agnostic knowledge-distillation-based xRAC-KD, through simplified but thorough human-grounded evaluations with SOTA transformer-based model, RAC. We find that the supporting evidence text highlighted by xRAC-ATTN is of higher quality than xRAC-KD whereas xRAC-KD has potential advantages in production deployment scenarios. More importantly, we show for the first time that, given the current state of explainability methodologies, using the SOTA medical codes prediction system still requires the expertise and competencies of professional coders, even though its prediction accuracy is superior to that of human coders. This, we believe, is a very meaningful step toward developing explainable and accurate machine learning systems for fully autonomous medical code prediction from clinical notes.
Read, Attend, and Code: Pushing the Limits of Medical Codes Prediction from Clinical Notes by Machines
Jul 10, 2021

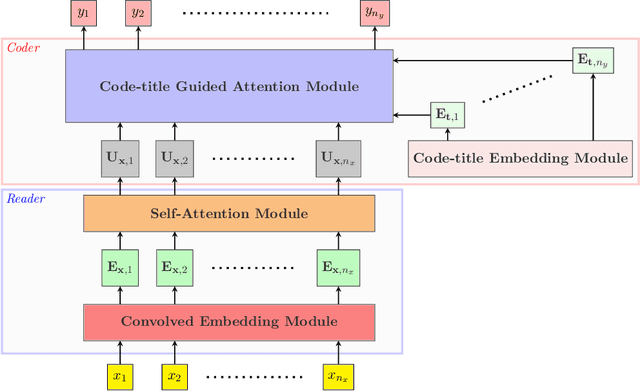
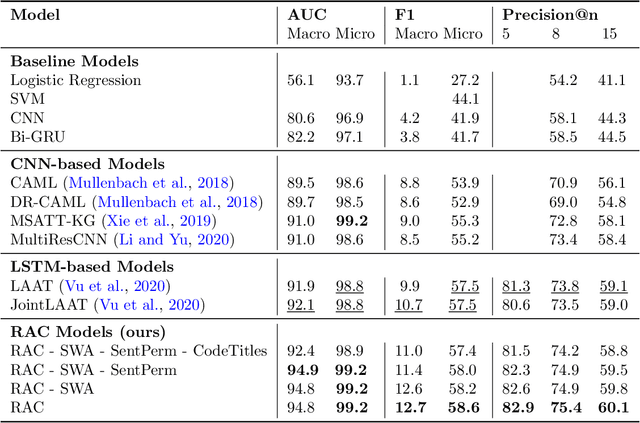
Prediction of medical codes from clinical notes is both a practical and essential need for every healthcare delivery organization within current medical systems. Automating annotation will save significant time and excessive effort spent by human coders today. However, the biggest challenge is directly identifying appropriate medical codes out of several thousands of high-dimensional codes from unstructured free-text clinical notes. In the past three years, with Convolutional Neural Networks (CNN) and Long Short-Term Memory (LTSM) networks, there have been vast improvements in tackling the most challenging benchmark of the MIMIC-III-full-label inpatient clinical notes dataset. This progress raises the fundamental question of how far automated machine learning (ML) systems are from human coders' working performance. We assessed the baseline of human coders' performance on the same subsampled testing set. We also present our Read, Attend, and Code (RAC) model for learning the medical code assignment mappings. By connecting convolved embeddings with self-attention and code-title guided attention modules, combined with sentence permutation-based data augmentations and stochastic weight averaging training, RAC establishes a new state of the art (SOTA), considerably outperforming the current best Macro-F1 by 18.7%, and reaches past the human-level coding baseline. This new milestone marks a meaningful step toward fully autonomous medical coding (AMC) in machines reaching parity with human coders' performance in medical code prediction.
Deep Claim: Payer Response Prediction from Claims Data with Deep Learning
Jul 13, 2020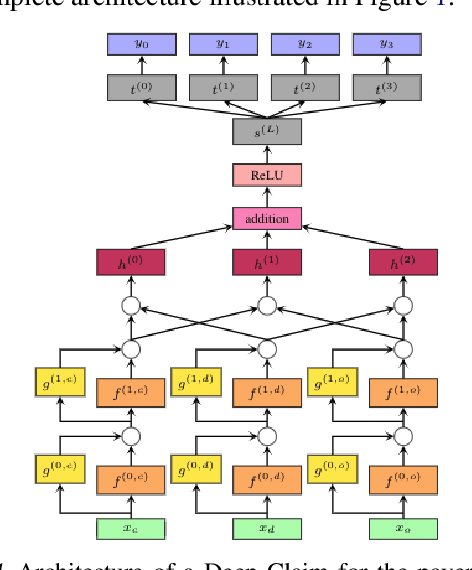


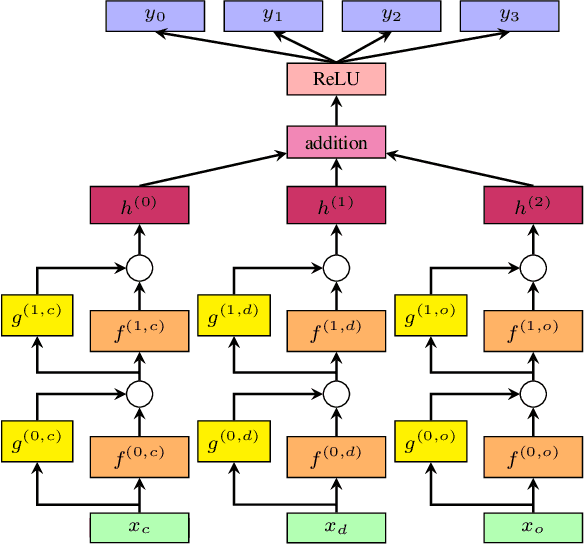
Each year, almost 10% of claims are denied by payers (i.e., health insurance plans). With the cost to recover these denials and underpayments, predicting payer response (likelihood of payment) from claims data with a high degree of accuracy and precision is anticipated to improve healthcare staffs' performance productivity and drive better patient financial experience and satisfaction in the revenue cycle (Barkholz, 2017). However, constructing advanced predictive analytics models has been considered challenging in the last twenty years. That said, we propose a (low-level) context-dependent compact representation of patients' historical claim records by effectively learning complicated dependencies in the (high-level) claim inputs. Built on this new latent representation, we demonstrate that a deep learning-based framework, Deep Claim, can accurately predict various responses from multiple payers using 2,905,026 de-identified claims data from two US health systems. Deep Claim's improvements over carefully chosen baselines in predicting claim denials are most pronounced as 22.21% relative recall gain (at 95% precision) on Health System A, which implies Deep Claim can find 22.21% more denials than the best baseline system.
LumièreNet: Lecture Video Synthesis from Audio
Jul 04, 2019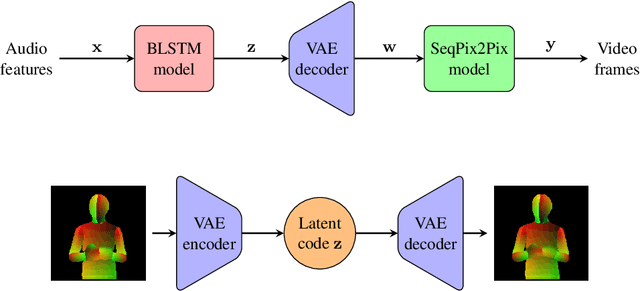


We present Lumi\`ereNet, a simple, modular, and completely deep-learning based architecture that synthesizes, high quality, full-pose headshot lecture videos from instructor's new audio narration of any length. Unlike prior works, Lumi\`ereNet is entirely composed of trainable neural network modules to learn mapping functions from the audio to video through (intermediate) estimated pose-based compact and abstract latent codes. Our video demos are available at [22] and [23].
GritNet 2: Real-Time Student Performance Prediction with Domain Adaptation
Sep 07, 2018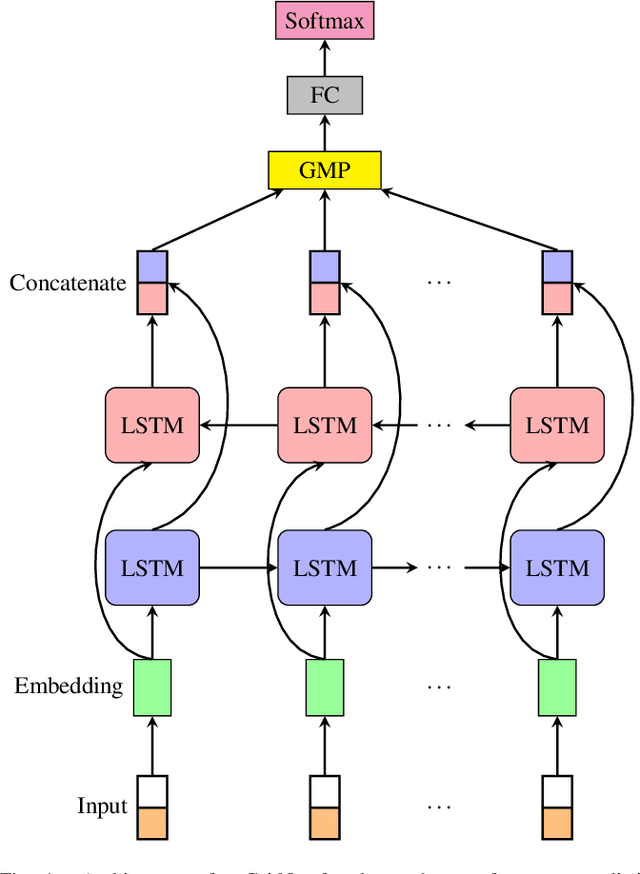
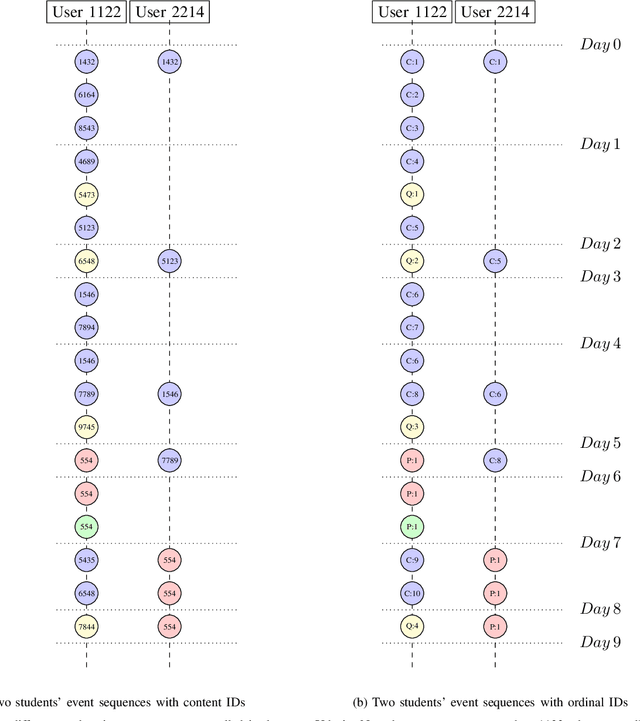
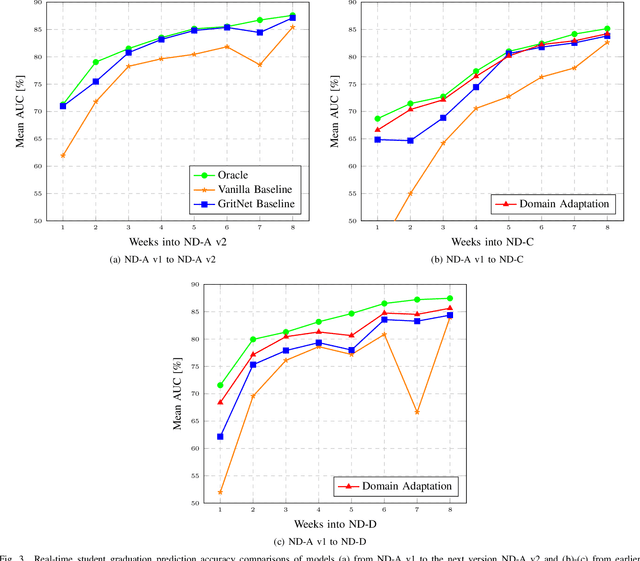

Increasingly fast development and update cycle of online course contents, and diverse demographics of students in each online classroom, make student performance prediction in real-time (before the course finishes) an interesting topic for both industrial research and practical needs. In that, we tackle the problem of real-time student performance prediction with on-going courses in domain adaptation framework, which is a system trained on students' labeled outcome from one previous coursework but is meant to be deployed on another. In particular, we first review recently-developed GritNet architecture which is the current state of the art for student performance prediction problem, and introduce a new unsupervised domain adaptation method to transfer a GritNet trained on a past course to a new course without any (students' outcome) label. Our results for real Udacity students' graduation predictions show that the GritNet not only generalizes well from one course to another across different Nanodegree programs, but enhances real-time predictions explicitly in the first few weeks when accurate predictions are most challenging.
GritNet: Student Performance Prediction with Deep Learning
Apr 19, 2018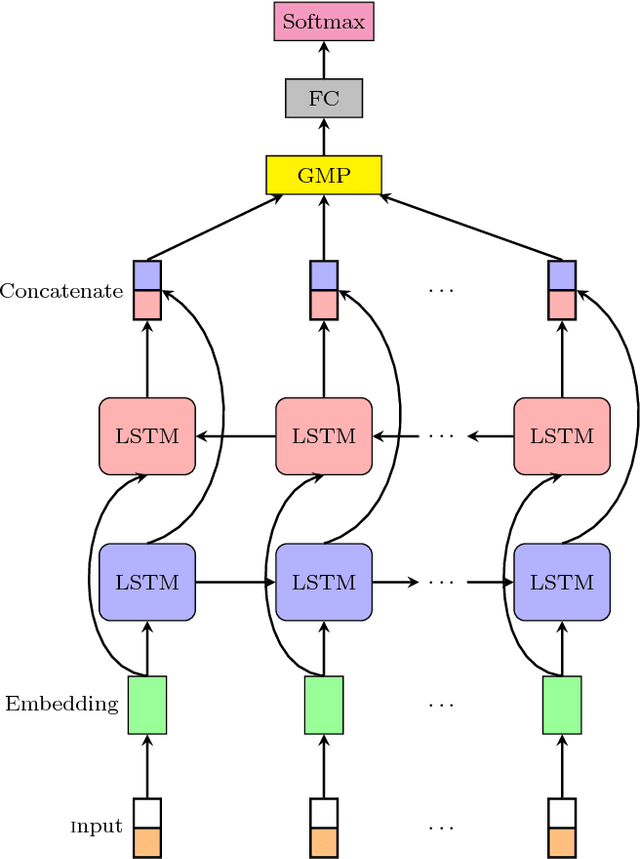

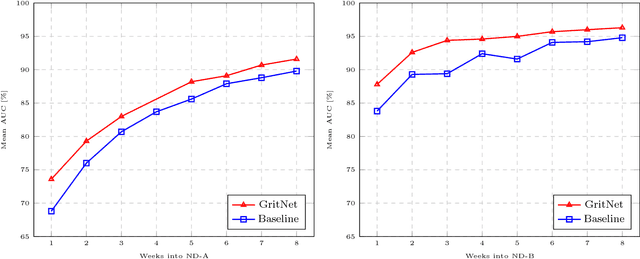
Student performance prediction - where a machine forecasts the future performance of students as they interact with online coursework - is a challenging problem. Reliable early-stage predictions of a student's future performance could be critical to facilitate timely educational interventions during a course. However, very few prior studies have explored this problem from a deep learning perspective. In this paper, we recast the student performance prediction problem as a sequential event prediction problem and propose a new deep learning based algorithm, termed GritNet, which builds upon the bidirectional long short term memory (BLSTM). Our results, from real Udacity students' graduation predictions, show that the GritNet not only consistently outperforms the standard logistic-regression based method, but that improvements are substantially pronounced in the first few weeks when accurate predictions are most challenging.
Constrained Approximate Maximum Entropy Learning of Markov Random Fields
Jun 13, 2012
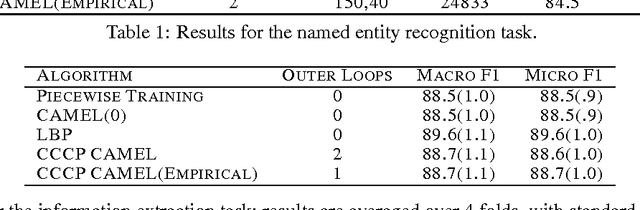

Parameter estimation in Markov random fields (MRFs) is a difficult task, in which inference over the network is run in the inner loop of a gradient descent procedure. Replacing exact inference with approximate methods such as loopy belief propagation (LBP) can suffer from poor convergence. In this paper, we provide a different approach for combining MRF learning and Bethe approximation. We consider the dual of maximum likelihood Markov network learning - maximizing entropy with moment matching constraints - and then approximate both the objective and the constraints in the resulting optimization problem. Unlike previous work along these lines (Teh & Welling, 2003), our formulation allows parameter sharing between features in a general log-linear model, parameter regularization and conditional training. We show that piecewise training (Sutton & McCallum, 2005) is a very restricted special case of this formulation. We study two optimization strategies: one based on a single convex approximation and one that uses repeated convex approximations. We show results on several real-world networks that demonstrate that these algorithms can significantly outperform learning with loopy and piecewise. Our results also provide a framework for analyzing the trade-offs of different relaxations of the entropy objective and of the constraints.