 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRead, Attend, and Code: Pushing the Limits of Medical Codes Prediction from Clinical Notes by Machines
Paper and Code
Jul 10, 2021

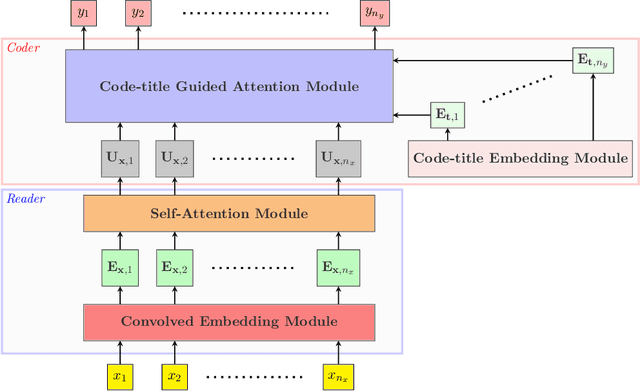
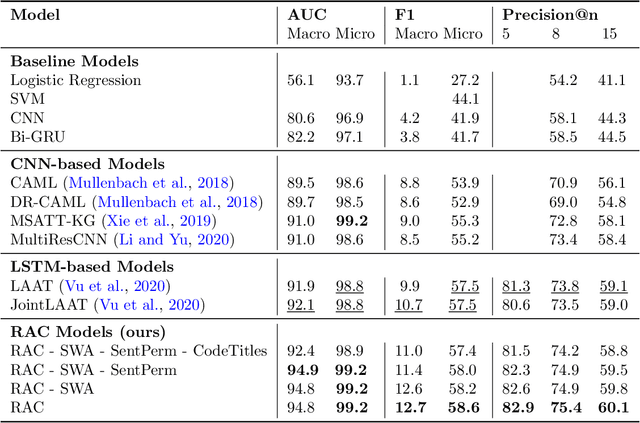
Prediction of medical codes from clinical notes is both a practical and essential need for every healthcare delivery organization within current medical systems. Automating annotation will save significant time and excessive effort spent by human coders today. However, the biggest challenge is directly identifying appropriate medical codes out of several thousands of high-dimensional codes from unstructured free-text clinical notes. In the past three years, with Convolutional Neural Networks (CNN) and Long Short-Term Memory (LTSM) networks, there have been vast improvements in tackling the most challenging benchmark of the MIMIC-III-full-label inpatient clinical notes dataset. This progress raises the fundamental question of how far automated machine learning (ML) systems are from human coders' working performance. We assessed the baseline of human coders' performance on the same subsampled testing set. We also present our Read, Attend, and Code (RAC) model for learning the medical code assignment mappings. By connecting convolved embeddings with self-attention and code-title guided attention modules, combined with sentence permutation-based data augmentations and stochastic weight averaging training, RAC establishes a new state of the art (SOTA), considerably outperforming the current best Macro-F1 by 18.7%, and reaches past the human-level coding baseline. This new milestone marks a meaningful step toward fully autonomous medical coding (AMC) in machines reaching parity with human coders' performance in medical code prediction.