Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLumièreNet: Lecture Video Synthesis from Audio
Paper and Code
Jul 04, 2019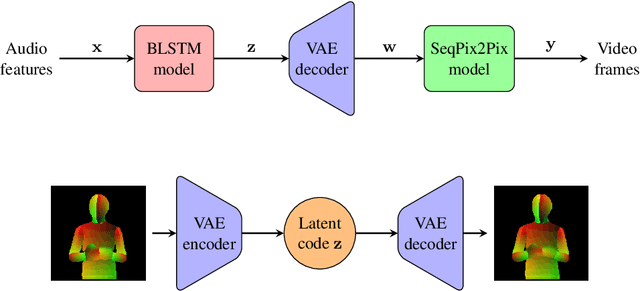

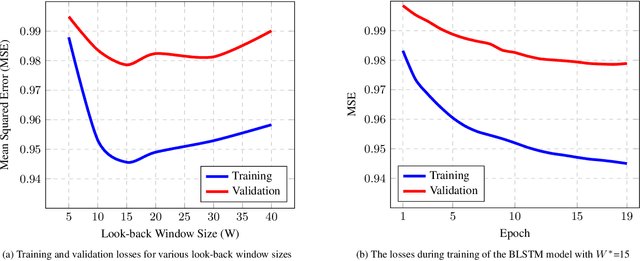

We present Lumi\`ereNet, a simple, modular, and completely deep-learning based architecture that synthesizes, high quality, full-pose headshot lecture videos from instructor's new audio narration of any length. Unlike prior works, Lumi\`ereNet is entirely composed of trainable neural network modules to learn mapping functions from the audio to video through (intermediate) estimated pose-based compact and abstract latent codes. Our video demos are available at [22] and [23].
View paper on