 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhi-4-reasoning-vision-15B Technical Report
Mar 04, 2026We present Phi-4-reasoning-vision-15B, a compact open-weight multimodal reasoning model, and share the motivations, design choices, experiments, and learnings that informed its development. Our goal is to contribute practical insight to the research community on building smaller, efficient multimodal reasoning models and to share the result of these learnings as an open-weight model that is good at common vision and language tasks and excels at scientific and mathematical reasoning and understanding user interfaces. Our contributions include demonstrating that careful architecture choices and rigorous data curation enable smaller, open-weight multimodal models to achieve competitive performance with significantly less training and inference-time compute and tokens. The most substantial improvements come from systematic filtering, error correction, and synthetic augmentation -- reinforcing that data quality remains the primary lever for model performance. Systematic ablations show that high-resolution, dynamic-resolution encoders yield consistent improvements, as accurate perception is a prerequisite for high-quality reasoning. Finally, a hybrid mix of reasoning and non-reasoning data with explicit mode tokens allows a single model to deliver fast direct answers for simpler tasks and chain-of-thought reasoning for complex problems.
Task Shift: From Classification to Regression in Overparameterized Linear Models
Feb 18, 2025Modern machine learning methods have recently demonstrated remarkable capability to generalize under task shift, where latent knowledge is transferred to a different, often more difficult, task under a similar data distribution. We investigate this phenomenon in an overparameterized linear regression setting where the task shifts from classification during training to regression during evaluation. In the zero-shot case, wherein no regression data is available, we prove that task shift is impossible in both sparse signal and random signal models for any Gaussian covariate distribution. In the few-shot case, wherein limited regression data is available, we propose a simple postprocessing algorithm which asymptotically recovers the ground-truth predictor. Our analysis leverages a fine-grained characterization of individual parameters arising from minimum-norm interpolation which may be of independent interest. Our results show that while minimum-norm interpolators for classification cannot transfer to regression a priori, they experience surprisingly structured attenuation which enables successful task shift with limited additional data.
The Group Robustness is in the Details: Revisiting Finetuning under Spurious Correlations
Jul 19, 2024Modern machine learning models are prone to over-reliance on spurious correlations, which can often lead to poor performance on minority groups. In this paper, we identify surprising and nuanced behavior of finetuned models on worst-group accuracy via comprehensive experiments on four well-established benchmarks across vision and language tasks. We first show that the commonly used class-balancing techniques of mini-batch upsampling and loss upweighting can induce a decrease in worst-group accuracy (WGA) with training epochs, leading to performance no better than without class-balancing. While in some scenarios, removing data to create a class-balanced subset is more effective, we show this depends on group structure and propose a mixture method which can outperform both techniques. Next, we show that scaling pretrained models is generally beneficial for worst-group accuracy, but only in conjuction with appropriate class-balancing. Finally, we identify spectral imbalance in finetuning features as a potential source of group disparities -- minority group covariance matrices incur a larger spectral norm than majority groups once conditioned on the classes. Our results show more nuanced interactions of modern finetuned models with group robustness than was previously known. Our code is available at https://github.com/tmlabonte/revisiting-finetuning.
Towards Last-layer Retraining for Group Robustness with Fewer Annotations
Sep 15, 2023Empirical risk minimization (ERM) of neural networks is prone to over-reliance on spurious correlations and poor generalization on minority groups. The recent deep feature reweighting (DFR) technique achieves state-of-the-art group robustness via simple last-layer retraining, but it requires held-out group and class annotations to construct a group-balanced reweighting dataset. In this work, we examine this impractical requirement and find that last-layer retraining can be surprisingly effective with no group annotations (other than for model selection) and only a handful of class annotations. We first show that last-layer retraining can greatly improve worst-group accuracy even when the reweighting dataset has only a small proportion of worst-group data. This implies a "free lunch" where holding out a subset of training data to retrain the last layer can substantially outperform ERM on the entire dataset with no additional data or annotations. To further improve group robustness, we introduce a lightweight method called selective last-layer finetuning (SELF), which constructs the reweighting dataset using misclassifications or disagreements. Our empirical and theoretical results present the first evidence that model disagreement upsamples worst-group data, enabling SELF to nearly match DFR on four well-established benchmarks across vision and language tasks with no group annotations and less than 3% of the held-out class annotations. Our code is available at https://github.com/tmlabonte/last-layer-retraining.
Scaling Novel Object Detection with Weakly Supervised Detection Transformers
Jul 11, 2022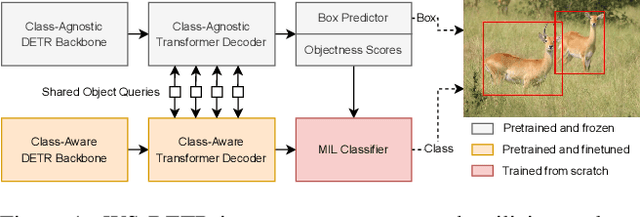

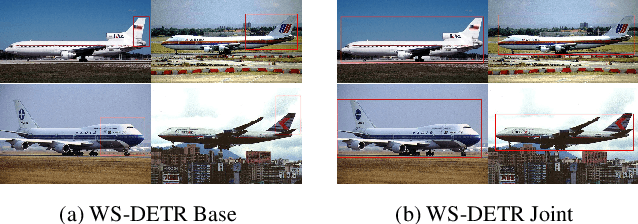
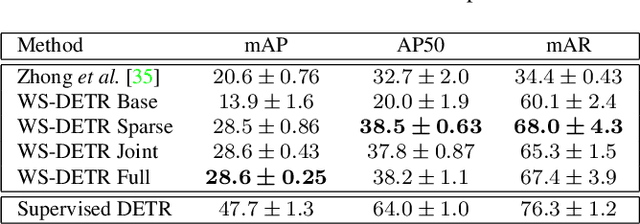
Weakly supervised object detection (WSOD) enables object detectors to be trained using image-level class labels. However, the practical application of current WSOD models is limited, as they operate at small scales and require extensive training and refinement. We propose the Weakly Supervised Detection Transformer, which enables efficient knowledge transfer from a large-scale pretraining dataset to WSOD finetuning on hundreds of novel objects. We leverage pretrained knowledge to improve the multiple instance learning framework used in WSOD, and experiments show our approach outperforms the state-of-the-art on datasets with twice the novel classes than previously shown.
We Know Where We Don't Know: 3D Bayesian CNNs for Uncertainty Quantification of Binary Segmentations for Material Simulations
Oct 23, 2019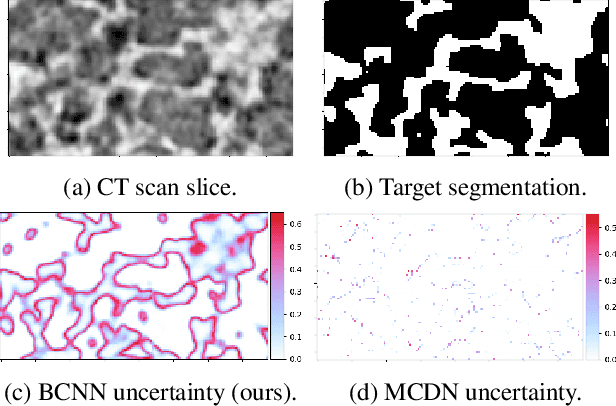
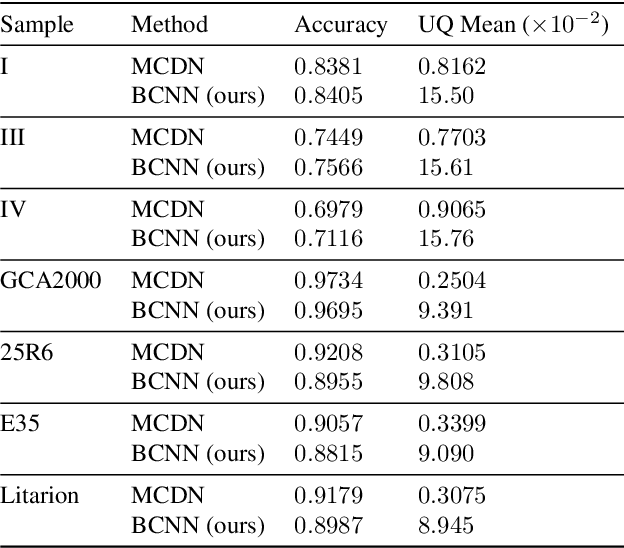
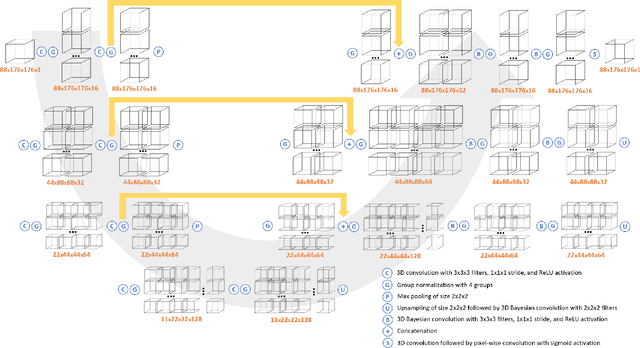
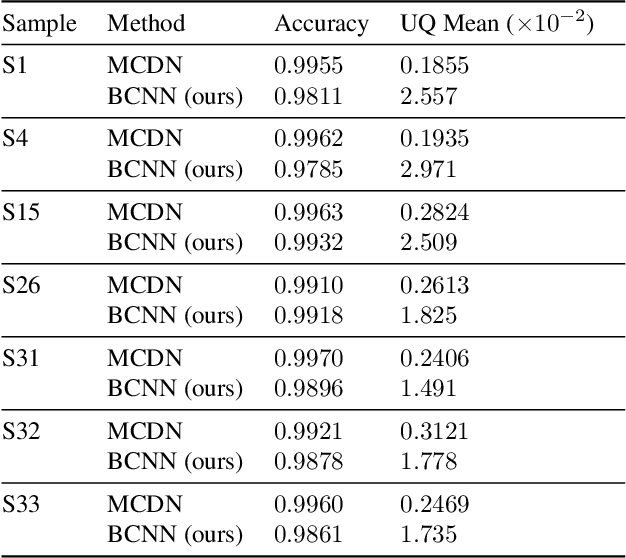
Deep learning has been applied with great success to the segmentation of 3D X-Ray Computed Tomography (CT) scans. Establishing the credibility of these segmentations requires uncertainty quantification (UQ) to identify problem areas. Recent UQ architectures include Monte Carlo dropout networks (MCDNs), which approximate Bayesian inference in deep Gaussian processes, and Bayesian neural networks (BNNs), which use variational inference to learn the posterior distribution of the neural network weights. BNNs hold several advantages over MCDNs for UQ, but due to the difficulty of training BNNs, they have not, to our knowledge, been successfully applied to 3D domains. In light of several recent developments in the implementation of BNNs, we present a novel 3D Bayesian convolutional neural network (BCNN) that provides accurate binary segmentations and uncertainty maps for 3D volumes. We present experimental results on CT scans of lithium-ion battery electrode materials and laser-welded metals to demonstrate that our BCNN provides improved UQ as compared to an MCDN while achieving equal or better segmentation accuracy. In particular, the uncertainty maps generated by our BCNN capture continuity and visual gradients, making them interpretable as confidence intervals for segmentation usable in subsequent simulations.