 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal disentanglement of multimodal data
Nov 08, 2023



Causal representation learning algorithms discover lower-dimensional representations of data that admit a decipherable interpretation of cause and effect; as achieving such interpretable representations is challenging, many causal learning algorithms utilize elements indicating prior information, such as (linear) structural causal models, interventional data, or weak supervision. Unfortunately, in exploratory causal representation learning, such elements and prior information may not be available or warranted. Alternatively, scientific datasets often have multiple modalities or physics-based constraints, and the use of such scientific, multimodal data has been shown to improve disentanglement in fully unsupervised settings. Consequently, we introduce a causal representation learning algorithm (causalPIMA) that can use multimodal data and known physics to discover important features with causal relationships. Our innovative algorithm utilizes a new differentiable parametrization to learn a directed acyclic graph (DAG) together with a latent space of a variational autoencoder in an end-to-end differentiable framework via a single, tractable evidence lower bound loss function. We place a Gaussian mixture prior on the latent space and identify each of the mixtures with an outcome of the DAG nodes; this novel identification enables feature discovery with causal relationships. Tested against a synthetic and a scientific dataset, our results demonstrate the capability of learning an interpretable causal structure while simultaneously discovering key features in a fully unsupervised setting.
Unsupervised physics-informed disentanglement of multimodal data for high-throughput scientific discovery
Feb 07, 2022We introduce physics-informed multimodal autoencoders (PIMA) - a variational inference framework for discovering shared information in multimodal scientific datasets representative of high-throughput testing. Individual modalities are embedded into a shared latent space and fused through a product of experts formulation, enabling a Gaussian mixture prior to identify shared features. Sampling from clusters allows cross-modal generative modeling, with a mixture of expert decoder imposing inductive biases encoding prior scientific knowledge and imparting structured disentanglement of the latent space. This approach enables discovery of fingerprints which may be detected in high-dimensional heterogeneous datasets, avoiding traditional bottlenecks related to high-fidelity measurement and characterization. Motivated by accelerated co-design and optimization of materials manufacturing processes, a dataset of lattice metamaterials from metal additive manufacturing demonstrates accurate cross modal inference between images of mesoscale topology and mechanical stress-strain response.
WiCV 2020: The Seventh Women In Computer Vision Workshop
Jan 11, 2021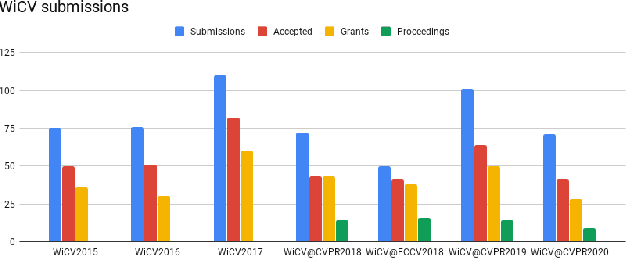
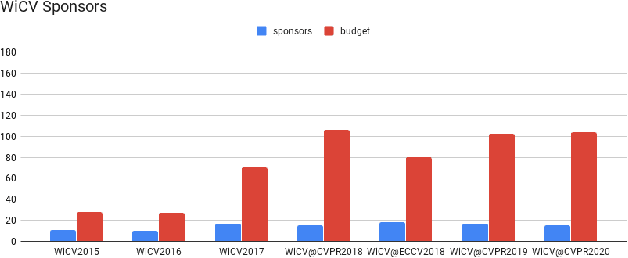
In this paper we present the details of Women in Computer Vision Workshop - WiCV 2020, organized in alongside virtual CVPR 2020. This event aims at encouraging the women researchers in the field of computer vision. It provides a voice to a minority (female) group in computer vision community and focuses on increasingly the visibility of these researchers, both in academia and industry. WiCV believes that such an event can play an important role in lowering the gender imbalance in the field of computer vision. WiCV is organized each year where it provides a.) opportunity for collaboration with between researchers b.) mentorship to female junior researchers c.) financial support to presenters to overcome monetary burden and d.) large and diverse choice of role models, who can serve as examples to younger researchers at the beginning of their careers. In this paper, we present a report on the workshop program, trends over the past years, a summary of statistics regarding presenters, attendees, and sponsorship for the current workshop.
We Know Where We Don't Know: 3D Bayesian CNNs for Uncertainty Quantification of Binary Segmentations for Material Simulations
Oct 23, 2019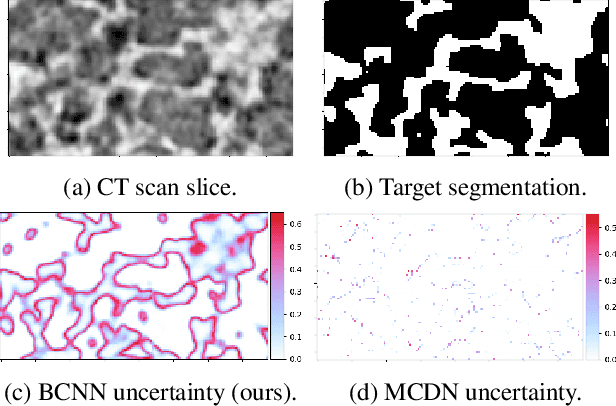
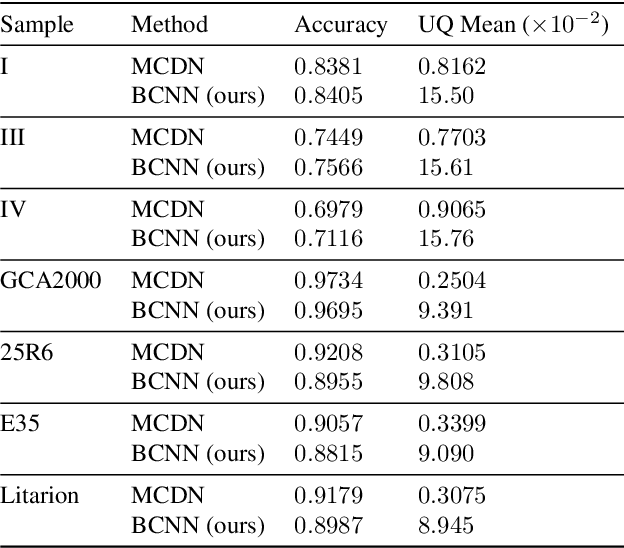
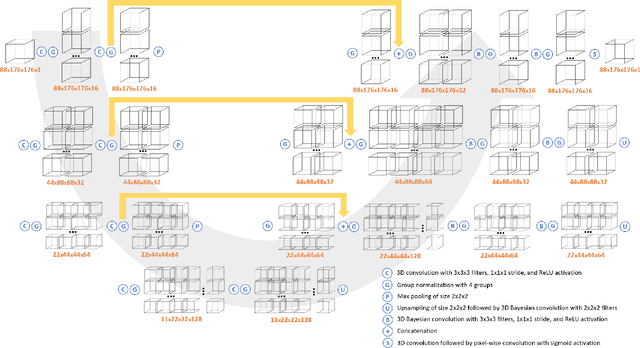
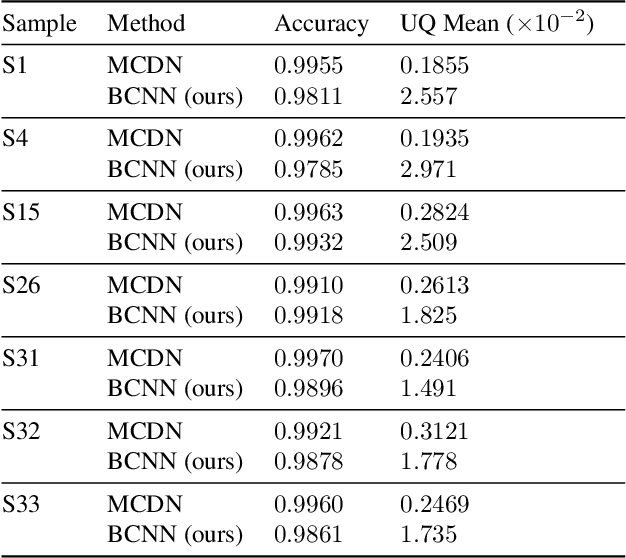
Deep learning has been applied with great success to the segmentation of 3D X-Ray Computed Tomography (CT) scans. Establishing the credibility of these segmentations requires uncertainty quantification (UQ) to identify problem areas. Recent UQ architectures include Monte Carlo dropout networks (MCDNs), which approximate Bayesian inference in deep Gaussian processes, and Bayesian neural networks (BNNs), which use variational inference to learn the posterior distribution of the neural network weights. BNNs hold several advantages over MCDNs for UQ, but due to the difficulty of training BNNs, they have not, to our knowledge, been successfully applied to 3D domains. In light of several recent developments in the implementation of BNNs, we present a novel 3D Bayesian convolutional neural network (BCNN) that provides accurate binary segmentations and uncertainty maps for 3D volumes. We present experimental results on CT scans of lithium-ion battery electrode materials and laser-welded metals to demonstrate that our BCNN provides improved UQ as compared to an MCDN while achieving equal or better segmentation accuracy. In particular, the uncertainty maps generated by our BCNN capture continuity and visual gradients, making them interpretable as confidence intervals for segmentation usable in subsequent simulations.