 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-informed lifting line theory
Mar 30, 2026We present a data-driven framework that extends the predictive capability of classical lifting-line theory (LLT) to a wider aerodynamic regime by incorporating higher-fidelity aerodynamic data from panel method simulations. A neural network architecture with a convolutional layer followed by fully connected layers is developed, comprising two parallel subnetworks to separately process spanwise collocation points and global geometric/aerodynamic inputs such as angle of attack, chord, twist, airfoil distribution, and sweep. Among several configurations tested, this architecture is most effective in learning corrections to LLT outputs. The trained model captures higher-order three-dimensional effects in spanwise lift and drag distributions in regimes where LLT is inaccurate, such as low aspect ratios and high sweep, and generalizes well to wing configurations outside both the LLT regime and the training data range. The method retains LLT's computational efficiency, enabling integration into aerodynamic optimization loops and early-stage aircraft design studies. This approach offers a practical path for embedding high-fidelity corrections into low-order methods and may be extended to other aerodynamic prediction tasks, such as propeller performance.
Multilevel Training for Kolmogorov Arnold Networks
Mar 05, 2026Algorithmic speedup of training common neural architectures is made difficult by the lack of structure guaranteed by the function compositions inherent to such networks. In contrast to multilayer perceptrons (MLPs), Kolmogorov-Arnold networks (KANs) provide more structure by expanding learned activations in a specified basis. This paper exploits this structure to develop practical algorithms and theoretical insights, yielding training speedup via multilevel training for KANs. To do so, we first establish an equivalence between KANs with spline basis functions and multichannel MLPs with power ReLU activations through a linear change of basis. We then analyze how this change of basis affects the geometry of gradient-based optimization with respect to spline knots. The KANs change-of-basis motivates a multilevel training approach, where we train a sequence of KANs naturally defined through a uniform refinement of spline knots with analytic geometric interpolation operators between models. The interpolation scheme enables a ``properly nested hierarchy'' of architectures, ensuring that interpolation to a fine model preserves the progress made on coarse models, while the compact support of spline basis functions ensures complementary optimization on subsequent levels. Numerical experiments demonstrate that our multilevel training approach can achieve orders of magnitude improvement in accuracy over conventional methods to train comparable KANs or MLPs, particularly for physics informed neural networks. Finally, this work demonstrates how principled design of neural networks can lead to exploitable structure, and in this case, multilevel algorithms that can dramatically improve training performance.
Interpreting Transformer Architectures as Implicit Multinomial Regression
Sep 04, 2025Mechanistic interpretability aims to understand how internal components of modern machine learning models, such as weights, activations, and layers, give rise to the model's overall behavior. One particularly opaque mechanism is attention: despite its central role in transformer models, its mathematical underpinnings and relationship to concepts like feature polysemanticity, superposition, and model performance remain poorly understood. This paper establishes a novel connection between attention mechanisms and multinomial regression. Specifically, we show that in a fixed multinomial regression setting, optimizing over latent features yields optimal solutions that align with the dynamics induced by attention blocks. In other words, the evolution of representations through a transformer can be interpreted as a trajectory that recovers the optimal features for classification.
Leveraging KANs for Expedient Training of Multichannel MLPs via Preconditioning and Geometric Refinement
May 23, 2025Multilayer perceptrons (MLPs) are a workhorse machine learning architecture, used in a variety of modern deep learning frameworks. However, recently Kolmogorov-Arnold Networks (KANs) have become increasingly popular due to their success on a range of problems, particularly for scientific machine learning tasks. In this paper, we exploit the relationship between KANs and multichannel MLPs to gain structural insight into how to train MLPs faster. We demonstrate the KAN basis (1) provides geometric localized support, and (2) acts as a preconditioned descent in the ReLU basis, overall resulting in expedited training and improved accuracy. Our results show the equivalence between free-knot spline KAN architectures, and a class of MLPs that are refined geometrically along the channel dimension of each weight tensor. We exploit this structural equivalence to define a hierarchical refinement scheme that dramatically accelerates training of the multi-channel MLP architecture. We show further accuracy improvements can be had by allowing the $1$D locations of the spline knots to be trained simultaneously with the weights. These advances are demonstrated on a range of benchmark examples for regression and scientific machine learning.
Mixture of neural operator experts for learning boundary conditions and model selection
Feb 06, 2025While Fourier-based neural operators are best suited to learning mappings between functions on periodic domains, several works have introduced techniques for incorporating non trivial boundary conditions. However, all previously introduced methods have restrictions that limit their applicability. In this work, we introduce an alternative approach to imposing boundary conditions inspired by volume penalization from numerical methods and Mixture of Experts (MoE) from machine learning. By introducing competing experts, the approach additionally allows for model selection. To demonstrate the method, we combine a spatially conditioned MoE with the Fourier based, Modal Operator Regression for Physics (MOR-Physics) neural operator and recover a nonlinear operator on a disk and quarter disk. Next, we extract a large eddy simulation (LES) model from direct numerical simulation of channel flow and show the domain decomposition provided by our approach. Finally, we train our LES model with Bayesian variational inference and obtain posterior predictive samples of flow far past the DNS simulation time horizon.
Gaussian Variational Schemes on Bounded and Unbounded Domains
Oct 08, 2024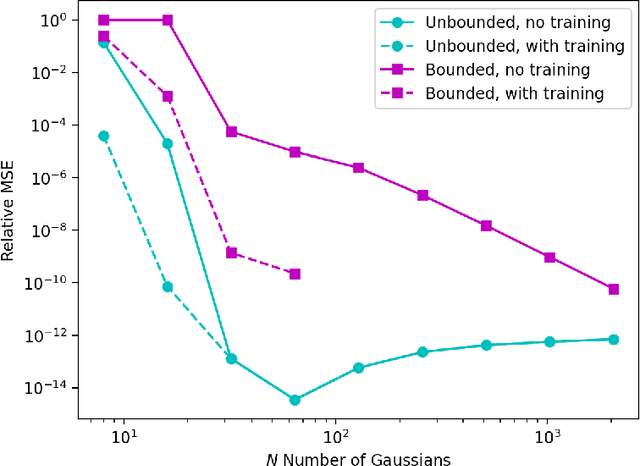
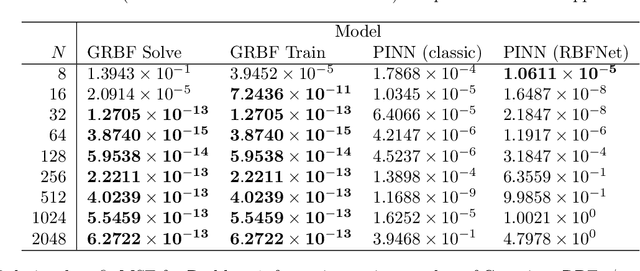

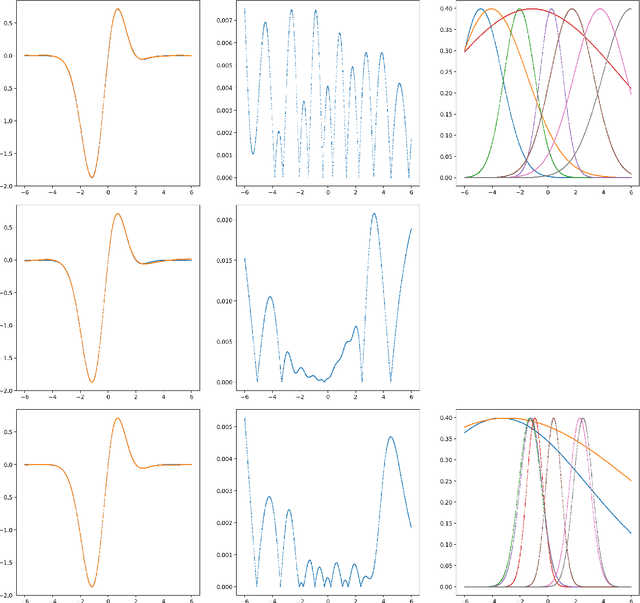
A machine-learnable variational scheme using Gaussian radial basis functions (GRBFs) is presented and used to approximate linear problems on bounded and unbounded domains. In contrast to standard mesh-free methods, which use GRBFs to discretize strong-form differential equations, this work exploits the relationship between integrals of GRBFs, their derivatives, and polynomial moments to produce exact quadrature formulae which enable weak-form expressions. Combined with trainable GRBF means and covariances, this leads to a flexible, generalized Galerkin variational framework which is applied in the infinite-domain setting where the scheme is conforming, as well as the bounded-domain setting where it is not. Error rates for the proposed GRBF scheme are derived in each case, and examples are presented demonstrating utility of this approach as a surrogate modeling technique.
Causal disentanglement of multimodal data
Nov 08, 2023



Causal representation learning algorithms discover lower-dimensional representations of data that admit a decipherable interpretation of cause and effect; as achieving such interpretable representations is challenging, many causal learning algorithms utilize elements indicating prior information, such as (linear) structural causal models, interventional data, or weak supervision. Unfortunately, in exploratory causal representation learning, such elements and prior information may not be available or warranted. Alternatively, scientific datasets often have multiple modalities or physics-based constraints, and the use of such scientific, multimodal data has been shown to improve disentanglement in fully unsupervised settings. Consequently, we introduce a causal representation learning algorithm (causalPIMA) that can use multimodal data and known physics to discover important features with causal relationships. Our innovative algorithm utilizes a new differentiable parametrization to learn a directed acyclic graph (DAG) together with a latent space of a variational autoencoder in an end-to-end differentiable framework via a single, tractable evidence lower bound loss function. We place a Gaussian mixture prior on the latent space and identify each of the mixtures with an outcome of the DAG nodes; this novel identification enables feature discovery with causal relationships. Tested against a synthetic and a scientific dataset, our results demonstrate the capability of learning an interpretable causal structure while simultaneously discovering key features in a fully unsupervised setting.
Polynomial-Spline Neural Networks with Exact Integrals
Oct 26, 2021Using neural networks to solve variational problems, and other scientific machine learning tasks, has been limited by a lack of consistency and an inability to exactly integrate expressions involving neural network architectures. We address these limitations by formulating a novel neural network architecture that combines a polynomial mixture-of-experts model with free knot B1-spline basis functions. Effectively, our architecture performs piecewise polynomial approximation on each cell of a trainable partition of unity. Our architecture exhibits both $h$- and $p$- refinement for regression problems at the convergence rates expected from approximation theory, allowing for consistency in solving variational problems. Moreover, this architecture, its moments, and its partial derivatives can all be integrated exactly, obviating a reliance on sampling or quadrature and enabling error-free computation of variational forms. We demonstrate the success of our network on a range of regression and variational problems that illustrate the consistency and exact integrability of our network architecture.