 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMES: Approximate Multi-modal Enterprise Search via Late Interaction Retrieval
Mar 13, 2026We present AMES (Approximate Multimodal Enterprise Search), a unified multimodal late interaction retrieval architecture which is backend agnostic. AMES demonstrates that fine-grained multimodal late interaction retrieval can be deployed within a production grade enterprise search engine without architectural redesign. Text tokens, image patches, and video frames are embedded into a shared representation space using multi-vector encoders, enabling cross-modal retrieval without modality specific retrieval logic. AMES employs a two-stage pipeline: parallel token level ANN search with per document Top-M MaxSim approximation, followed by accelerator optimized Exact MaxSim re-ranking. Experiments on the ViDoRe V3 benchmark show that AMES achieves competitive ranking performance within a scalable, production ready Solr based system.
Ensemble Squared: A Meta AutoML System
Dec 10, 2020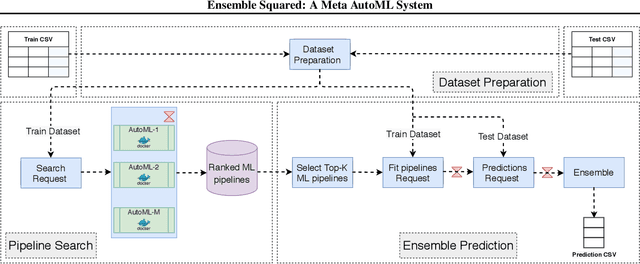
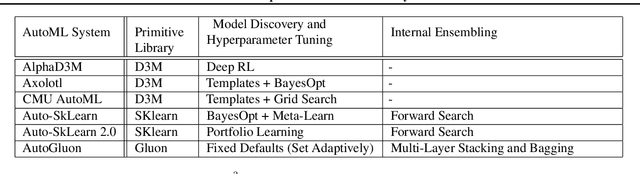
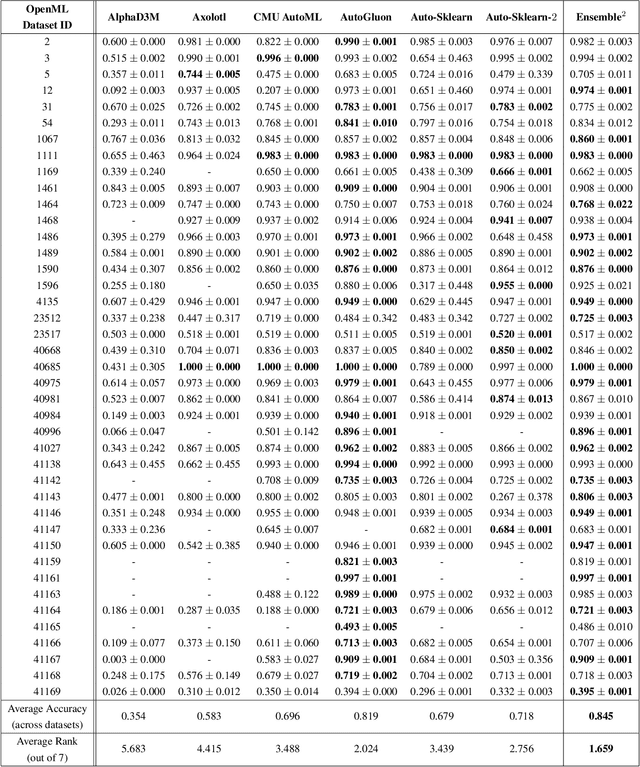
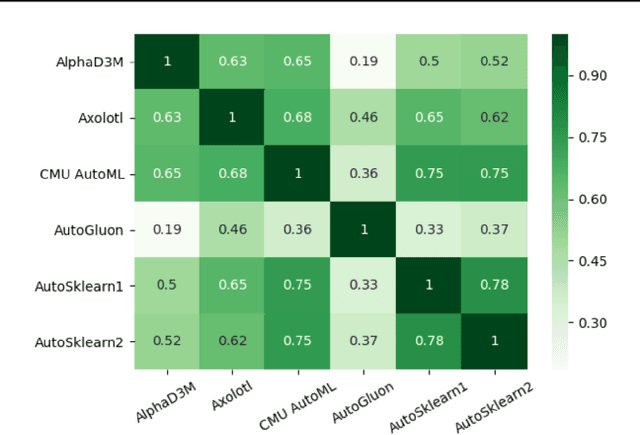
The continuing rise in the number of problems amenable to machine learning solutions, coupled with simultaneous growth in both computing power and variety of machine learning techniques has led to an explosion of interest in automated machine learning (AutoML). This paper presents Ensemble Squared (Ensemble$^2$), a "meta" AutoML system that ensembles at the level of AutoML systems. Ensemble$^2$ exploits the diversity of existing, competing AutoML systems by ensembling the top-performing models simultaneously generated by a set of them. Our work shows that diversity in AutoML systems is sufficient to justify ensembling at the AutoML system level. In demonstrating this, we also establish a new state of the art AutoML result on the OpenML classification challenge.
UAN: Unified Attention Network for Convolutional Neural Networks
Jan 16, 2019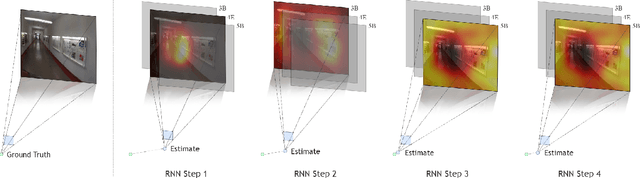
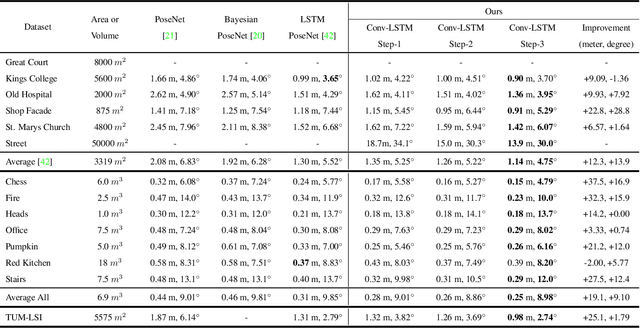
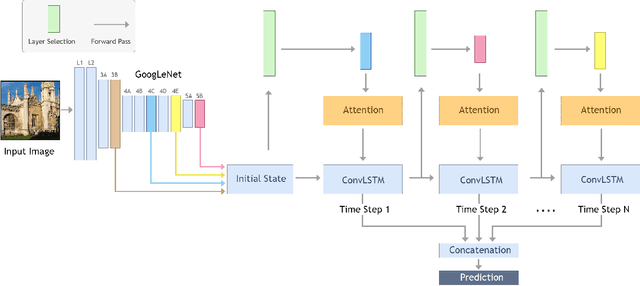

We propose a new architecture that learns to attend to different Convolutional Neural Networks (CNN) layers (i.e., different levels of abstraction) and different spatial locations (i.e., specific layers within a given feature map) in a sequential manner to perform the task at hand. Specifically, at each Recurrent Neural Network (RNN) timestep, a CNN layer is selected and its output is processed by a spatial soft-attention mechanism. We refer to this architecture as the Unified Attention Network (UAN), since it combines the "what" and "where" aspects of attention, i.e., "what" level of abstraction to attend to, and "where" should the network look at. We demonstrate the effectiveness of this approach on two computer vision tasks: (i) image-based camera pose and orientation regression and (ii) indoor scene classification. We evaluate our method on standard benchmarks for camera localization (Cambridge, 7-Scene, and TUM-LSI datasets) and for scene classification (MIT-67 indoor dataset), and show that our method improves upon the results of previous methods. Empirically, we show that combining "what" and "where" aspects of attention improves network performance on both tasks.
EdgeConnect: Generative Image Inpainting with Adversarial Edge Learning
Jan 11, 2019
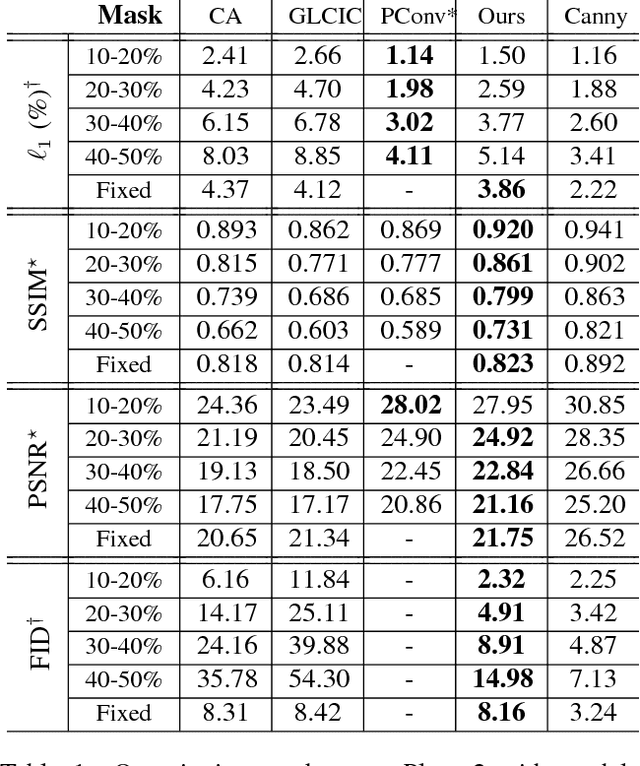
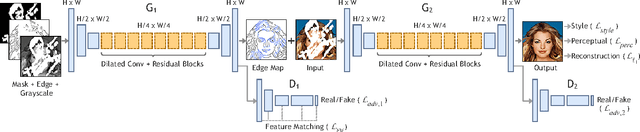
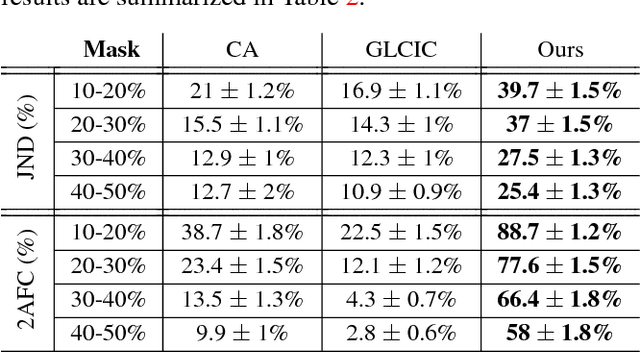
Over the last few years, deep learning techniques have yielded significant improvements in image inpainting. However, many of these techniques fail to reconstruct reasonable structures as they are commonly over-smoothed and/or blurry. This paper develops a new approach for image inpainting that does a better job of reproducing filled regions exhibiting fine details. We propose a two-stage adversarial model EdgeConnect that comprises of an edge generator followed by an image completion network. The edge generator hallucinates edges of the missing region (both regular and irregular) of the image, and the image completion network fills in the missing regions using hallucinated edges as a priori. We evaluate our model end-to-end over the publicly available datasets CelebA, Places2, and Paris StreetView, and show that it outperforms current state-of-the-art techniques quantitatively and qualitatively. Code and models available at: https://github.com/knazeri/edge-connect