 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdge-Informed Single Image Super-Resolution
Sep 11, 2019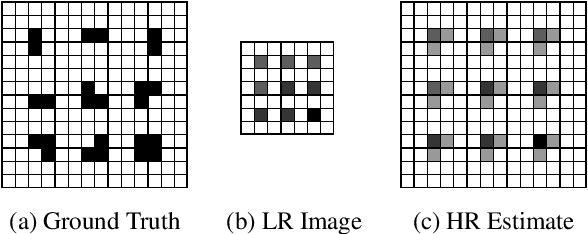


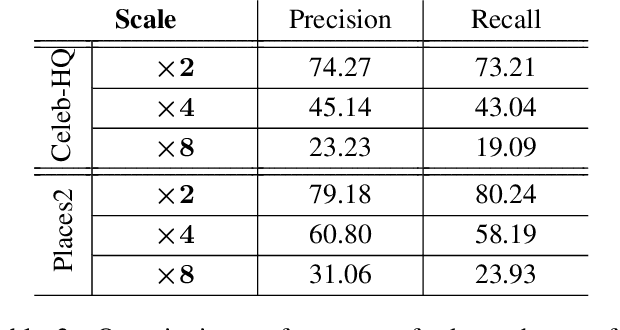
The recent increase in the extensive use of digital imaging technologies has brought with it a simultaneous demand for higher-resolution images. We develop a novel edge-informed approach to single image super-resolution (SISR). The SISR problem is reformulated as an image inpainting task. We use a two-stage inpainting model as a baseline for super-resolution and show its effectiveness for different scale factors (x2, x4, x8) compared to basic interpolation schemes. This model is trained using a joint optimization of image contents (texture and color) and structures (edges). Quantitative and qualitative comparisons are included and the proposed model is compared with current state-of-the-art techniques. We show that our method of decoupling structure and texture reconstruction improves the quality of the final reconstructed high-resolution image. Code and models available at: https://github.com/knazeri/edge-informed-sisr
Automatic Temporally Coherent Video Colorization
Apr 21, 2019



Greyscale image colorization for applications in image restoration has seen significant improvements in recent years. Many of these techniques that use learning-based methods struggle to effectively colorize sparse inputs. With the consistent growth of the anime industry, the ability to colorize sparse input such as line art can reduce significant cost and redundant work for production studios by eliminating the in-between frame colorization process. Simply using existing methods yields inconsistent colors between related frames resulting in a flicker effect in the final video. In order to successfully automate key areas of large-scale anime production, the colorization of line arts must be temporally consistent between frames. This paper proposes a method to colorize line art frames in an adversarial setting, to create temporally coherent video of large anime by improving existing image to image translation methods. We show that by adding an extra condition to the generator and discriminator, we can effectively create temporally consistent video sequences from anime line arts. Code and models available at: https://github.com/Harry-Thasarathan/TCVC
EdgeConnect: Generative Image Inpainting with Adversarial Edge Learning
Jan 11, 2019
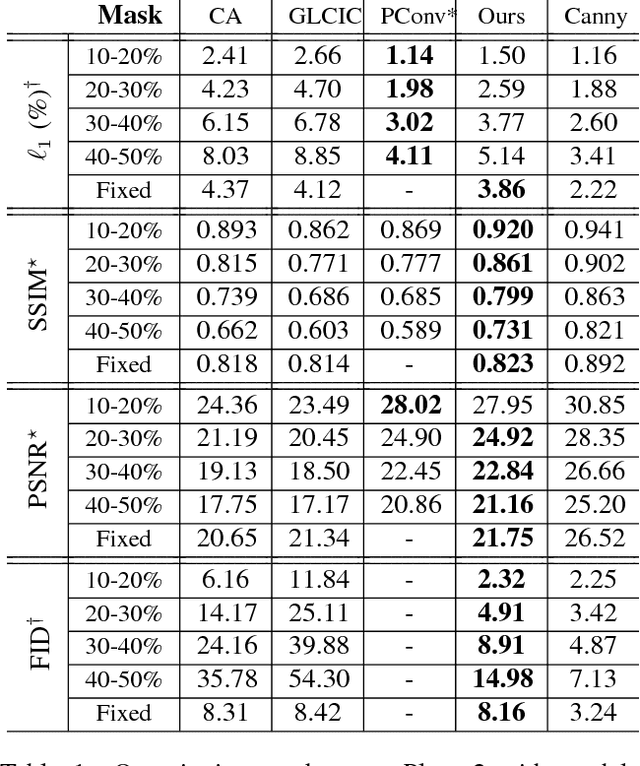
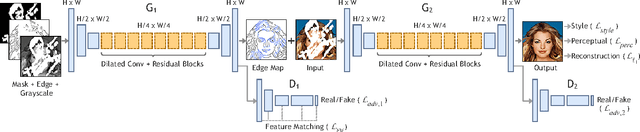
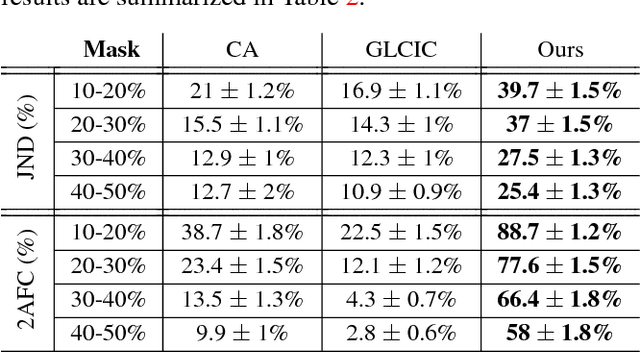
Over the last few years, deep learning techniques have yielded significant improvements in image inpainting. However, many of these techniques fail to reconstruct reasonable structures as they are commonly over-smoothed and/or blurry. This paper develops a new approach for image inpainting that does a better job of reproducing filled regions exhibiting fine details. We propose a two-stage adversarial model EdgeConnect that comprises of an edge generator followed by an image completion network. The edge generator hallucinates edges of the missing region (both regular and irregular) of the image, and the image completion network fills in the missing regions using hallucinated edges as a priori. We evaluate our model end-to-end over the publicly available datasets CelebA, Places2, and Paris StreetView, and show that it outperforms current state-of-the-art techniques quantitatively and qualitatively. Code and models available at: https://github.com/knazeri/edge-connect
Image Colorization with Generative Adversarial Networks
May 16, 2018

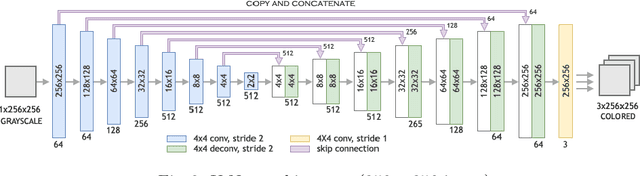

Over the last decade, the process of automatic image colorization has been of significant interest for several application areas including restoration of aged or degraded images. This problem is highly ill-posed due to the large degrees of freedom during the assignment of color information. Many of the recent developments in automatic colorization involve images that contain a common theme or require highly processed data such as semantic maps as input. In our approach, we attempt to fully generalize the colorization procedure using a conditional Deep Convolutional Generative Adversarial Network (DCGAN), extend current methods to high-resolution images and suggest training strategies that speed up the process and greatly stabilize it. The network is trained over datasets that are publicly available such as CIFAR-10 and Places365. The results of the generative model and traditional deep neural networks are compared.
* Lecture Notes in Computer Science, Proceedings of tenth international conference on Articulated Motion and Deformable Objects (AMDO), Palma, Mallorca, Spain, 12-13 July 2018
Two-Stage Convolutional Neural Network for Breast Cancer Histology Image Classification
Apr 01, 2018

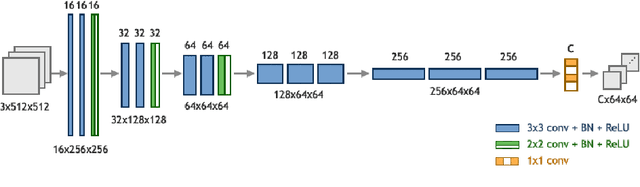
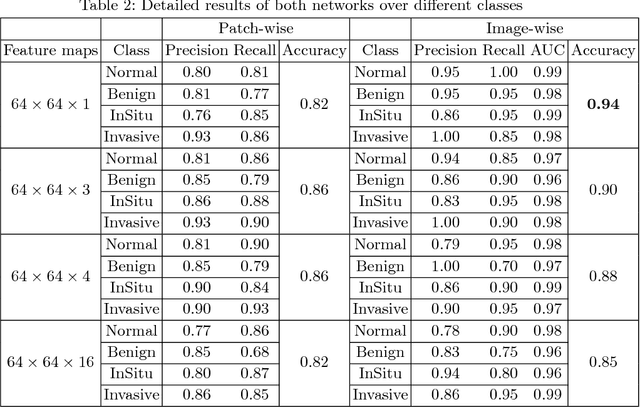
This paper explores the problem of breast tissue classification of microscopy images. Based on the predominant cancer type the goal is to classify images into four categories of normal, benign, in situ carcinoma, and invasive carcinoma. Given a suitable training dataset, we utilize deep learning techniques to address the classification problem. Due to the large size of each image in the training dataset, we propose a patch-based technique which consists of two consecutive convolutional neural networks. The first "patch-wise" network acts as an auto-encoder that extracts the most salient features of image patches while the second "image-wise" network performs classification of the whole image. The first network is pre-trained and aimed at extracting local information while the second network obtains global information of an input image. We trained the networks using the ICIAR 2018 grand challenge on BreAst Cancer Histology (BACH) dataset. The proposed method yields 95 % accuracy on the validation set compared to previously reported 77 % accuracy rates in the literature. Our code is publicly available at https://github.com/ImagingLab/ICIAR2018
* 10 pages, 5 figures, ICIAR 2018 conference